Python - Playwright安装与基础使用
前言:
Playwright 是专门为满足端到端测试的需要而创建的。Playwright 支持所有现代渲染引擎,包括 Chromium、WebKit(Safari 的浏览器引擎)和 Firefox。在 Windows、Linux 和 macOS 上进行本地测试或在 CI 上进行测试.
与Selenium+driver不同的是,Pw需要使用定制版的浏览器。如果本地已经安装了浏览器,那么可能会被覆盖掉,所以安装时请注意。官方会通过微软CDN自动下载,也支持配置外网代理下载,如果微软CDN在工作环境禁用,申请外网权限后,可以通过搭建一个跳板机进行代理下载。Playwright 安装的定制浏览器可以作为普通浏览器正常使用
一、安装:
安装Playwright
python3 -m pip install playwright -i https://mirrors.aliyun.com/pypi/simple/ # 安装playwright的python版本
安装Playwright自带的浏览器
python3 -m playwright install # 安装playwright自带的浏览器和ffmepg
二、基本使用:
cmd输入命令
仅打开
playwright open #打开Playwright
打开并开启录制
playwright codegen #开启录制
#指定网址 playwright codegen www.baidu.com #移动端浏览 playwright codegen --device="iPhone 11" #输出保存的代码文件名称 playwright codegen -o test.py #浏览器的名称,默认Google chromium浏览器 playwright codegen -b chromium #保留经过身份验证的状态 playwright codegen --save-storage=auth.json URL #取的状态文件路径,文件包含cookie信息 playwright codegen --load-storage=auth.json URL
三、录制的代码:
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None: browser = playwright.chromium.launch(headless=False) context = browser.new_context() page = context.new_page() page.goto("https://www.baidu.com/") page.locator("#kw").click() page.locator("#kw").fill("Playwright") age.wait_for_timeout(2000) #等待 page.locator("#kw").press("Enter") # --------------------- context.close() browser.close() with sync_playwright() as playwright: run(playwright)
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None: browser = playwright.chromium.launch(headless=False) context = browser.new_context() page = context.new_page() page.goto("https://www.baidu.com/") page.locator("#s-usersetting-top").hover() #鼠标悬停设置 page.wait_for_timeout(3000) page.get_by_role("link", name="搜索设置").click() page.wait_for_timeout(5000) # --------------------- context.close() browser.close() with sync_playwright() as playwright: run(playwright)
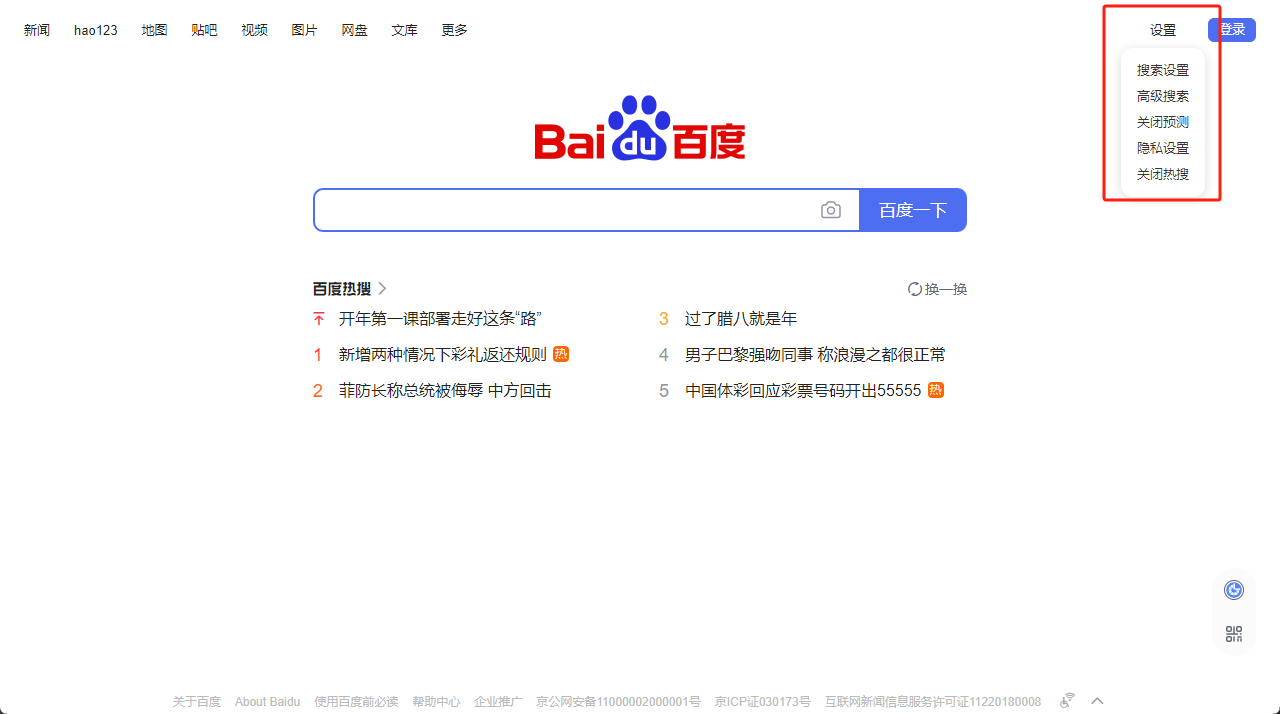
四、相关命令:
# 访问具体网站 page.goto(url) #悬停 page.locator("#xx").hover() # 监听事件, 比如close、console、load、request、response等 page.on(event, callback) #页面等待 page.wait_for_timeout(2000)
# 等待页面500 ms没有网络请求 可切换到domcontentloaded- 等到加载DOMContentLoaded事件 page.wait_for_load_state(state='networkidle') # 请求拦截 page.route(url, handler) # url可以是普通字符串(必须含url末位字符),也可以是正则pattern字符串,即re.compile(r'xxx') # 设置页面大小 page.set_viewport_size({'width':1366, 'height':768}) # 执行js代码 data1 = page.evaluate('() => {return window.encrypt("xx", "yyy")}') data2 = page.evaluate('([a, b]) => a + b', [3, 4]) # 7 data3 = page.evaluate('10+5') # 15 js_code1 = ''' var test = function(a,b){window.hello = 20;return a + b}; // 只能使用函数表达式,使用函数声明则会报错 test(30,60) // 不能使用return ''' js_code2 = '''window.hello''' js_code3 = ''' var a = 20; var b = 30; a + b ''' print(page.evaluate(js_code1)) # 90 print(page.evaluate(js_code2)) # 20 print(page.evaluate(js_code3)) # 50 # 截图 page.screenshot(type=None, path=None) # 点击页面元素 page.click(selector) # 获取页面源码 page.content() # 获取单个节点 element = page.query_selector(selector) element.get_attribute('属性名') # 获取节点属性 element.text_content() # 获取节点文本 # 获取多个节点 elements = page.query_selector_all(selector) for ele in elements: ele.get_attribute('属性名') # 获取属性 ele.text_content() # 获取文本 # 文本输入 page.fill(selector, value, timeout=None) # 根据选择器,输入文本内容,timeout可设置对应节点的最长等待时间
五、事件监听:
Page对象提供了on方法,用来监听页面中的各个事件,比如close、console、load、request、response等
from playwright.sync_api import sync_playwright def on_response(response): # 直接截获ajax请求数据 if '/api/movie' in response.url and response.status == 200: print(response.json()) with sync_playwright() as playwright: browser = playwright.chromium.launch(headless=False) page = browser.new_page() # 事件监听,例如close、console、load、request、response等 page.on('response', on_response) page.goto("https://spa6.scrape.center/") # 访问网址 page.wait_for_load_state(state='networkidle') # 等待当前页面初始化和加载完成 browser.close()
作者:小林同学_Scorpio
本博客所有文章仅用于学习、分享和交流目的,欢迎非商业性质转载。
博主的文章没有高度、深度和广度,只是凑字数,做笔记。由于博主的水平不高,不足和错误之处在所难免,希望大家能够批评指出。
博主是利用参考、引用、抄袭、复制和粘贴等多种方式打造成自己的文章,请原谅博主成为一个无耻的文档搬运工!
