
DiscuzNT3正式版发布已经有一段时间了,最近半年多来很少再写关于这个产品的技术文章了,一是时间,二是精力有限。不过在正式版发表之后,倒是有了些功夫,同时我们的一个商业客户在从2.6版本升级到3.0正式版之后,出了一个小插曲,导致不得不退回到2.6版本。因为这个客户的论坛访问量和发帖量比较大,平时在线人数5000,日发帖量在2-3万左右。所以出了一些性能上的问题,在大并发情况下,服务器响应超时,且在峰值时越发不稳定。之前我在公司内部用了tinyget做了一些简单的压力测试,发现了一些问题,但原因尚不明显,所以在公司会议上就有人提出使用loadruner来做一下压力测试,看看3.0产品的性能倒底如何,是什么造成用户的服务器不稳定。所以就有了今天的这篇文章。
当然,我写这篇文章的目的主要是做一份备忘录。原因很简单,就是三年多以前曾用过一段时间的LR,本以为这次测试会轻车熟路,可不曾想,连最简单的并发用户数都忘在哪里设置了,所以鉴于此,才有感做记录的‘必要性’。所以本文的内容兼笔记和实战于一身,呵呵。好了,费话少说,let’s go!
首先,我要在本地搭建一个测试环境,而这个测试环境是一个小型的内部网络,包括一台1u的服务器,一台TPLINK交换机和一台安装了lr的机器。而为什么要这样做,原因很简单,如果使用公司局域网,首先就要受到网络内部流量的影响以及限流软件的限制,如果再有一两个同事开个什么‘雷’呀,‘驴’呀,‘米’呀的下载器,那就更热闹了,很难最终把压力和网络流量模拟上来,所以我就直接通过网管找来了这三台设备,给成了一个100m的内部网络,这样能够从根本上确保1000 的并发用户数(v_user)。
这里要声明的是,本身用的是loadruner8.0,且是破解版。呵呵,你没看错,因为我很穷,没这份财力去购买正版的lisence,所以这里就只能‘那个’了。同时,为了确保安装的lr正常运行,我直接将其安装在了window2003+ie6的平台上,这是lr比较标准的系统运行环境。在完成安装和lisence注册后,下面就来看一下其使用流程。
第一步:录制脚本
下面就是一个录制脚本的过程:
因为测试的是WEB应用,所以在创建项目窗口中选择http协议。
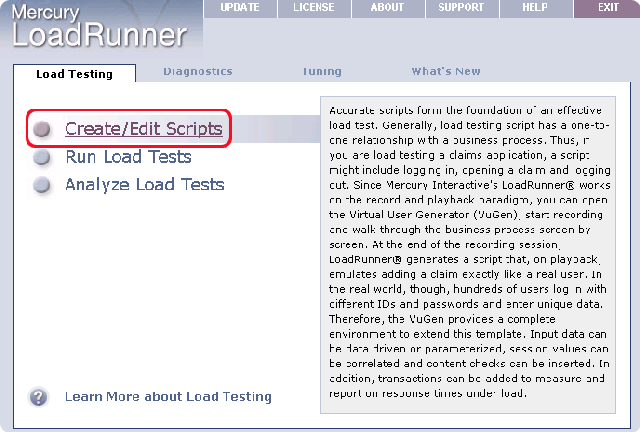

然后紧接着在下面窗口中填入要测试程序的http链接地址,然后点击确定。这时lr就会启动ie6并按之前我们设置的网址访问该应用。
这里我们可以看到下面的events在不断的累加,这些events我们可以看成是一个个http请求处理操作(比如下载js,css,图片等)。
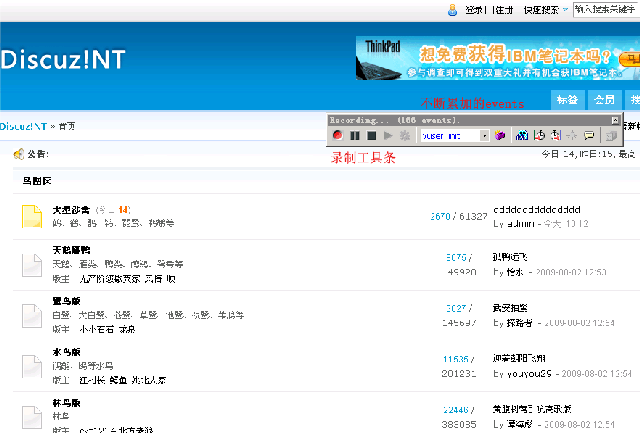
接着我们点击该录制工具的“new action”图标来新建一个action,这样做的目的就是将我们测试流程中的每一个环节分别定义,以便在后续分析压力测试结果时能够一目了然,呵呵。
我们在新的action中,定义为“showforum”(即显示版块信息),然后我们就去点击一个论坛版块链接,如下:
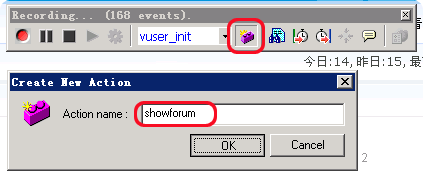
注:我习惯于将action的名称定义为链接页面名称,这样比较直观。

这里我们看到events累加数又在变化。这时我们再创建一个action,以记录发主题的操作,这里因为我们的产品在3.0中支持了弹窗功能,所以我们就将该action记录为"pop_posttopic”, 然后我们点击一个当前showforum页面的“新帖”按钮,这样发帖页面就被弹出来了,如下图:
这里大家看到了吧,即使是ajax弹窗,lr也会‘忠实’的加以记录。
这里我们简单的输入一些信息,然后在创建一个新的action叫‘posttopic’,也就是提交主题,接着我们点击发布按钮,这样就将提交主题流程也记录下来了。
大家会发现当发布成功后,页面会跳转到showtopic。换句话说'posttopic’这个action中包含提交和跳转两个操作,不过没关系,等测试报告出来时,我们可以看到这一个action中的两个操作分别的执行时间,页面体积等信息。
按一般人浏览论坛的习惯,就是其会在不同的版块和话题之间‘翻来覆去’的‘折腾’,所以我们就再创建一action,叫'showforum_2’,以代表其跳转版块的行为,然后点击导航链接上的按钮,如下图:
当页面跳到showforum页面下时,我们再创建一个action,叫showtopic_2,以代表用户又打开了一个新主题。然后我们就随便点一个主题帖。这样就基本上完成了一个主要的操作流程。最后我们在录制工具的下拉框中找到“vuser_end”这个action,以此作为最后一个action的操作,平时我把‘注销(退出登陆)’操作做为这个action的内容,而今天我以‘跳转回首页’作为了“vuser_end”这个action的内容了。
这样,录制工具就完成了,我们点击录制工具条上的那个方块图标,来结束录制,如下图:

下面我们来看一下lr给我们生成的相关脚本。如下图:

直接从脚本上来看,基本上就是每个action所访问页面内容中的链接,脚本及相关文件的链接信息。lr就是借助这些信息来依次执行相关操作的。
下面我们可以接着设置一下我们刚才录制脚本时所做的‘一系列操作’的‘重复次数’,我们可以通过点击lr上的工具栏图标来进行设置,如下图:
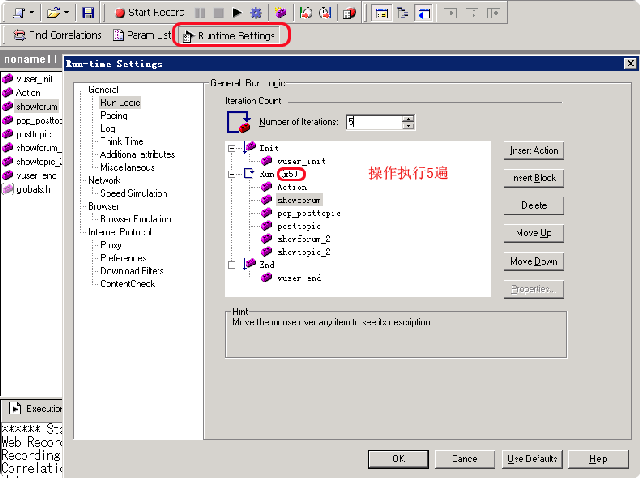
在弹出窗口中,我们可以设置重复次数,图中的设置是重复这些操作5次。
当然我们还可以设置每个action执行完之后的间隔时间,这一点我们可以理解成为:当我们看一个帖子时,不会一打开页面就跳转或关闭,肯定会看完相应内容之后才执行‘后续操作’。不过为了最大限度的给服务器和数据库‘制造压力’,这里用的是默认设置,即一个action操作完后马上执行下一个action,如下图:

我们可以用lr上的操作图标,来看一下我们脚本的执行情况(注:按F10为单步执行)
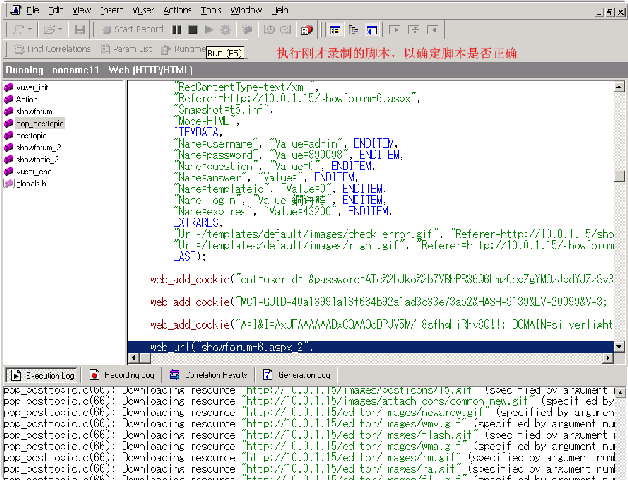
注:检查脚本的执行情况主要是为了后续工作考虑,因为有些脚本录制的内容可能不正确或不是我们想要的,我们可以酌情修改。
好了,今天的内容就先到这里了,在后续的文章中,将会介绍如果设置并发用户,以及生成保存测试结果,以及如果分析测试报告,因为一切工作都是为了生成一份尽可能准确,客观的‘报告’,从而能快速帮助我们找出‘系统瓶颈’,从而重点加以优化。
在上文中,介绍了如果录制脚本和设置脚本执行次数。如果经过调试脚本能够正常工作的话,就可以设置并发用户数并进行压力测试了。
首先我们通过脚本编辑界面上的“工具”菜单项,选择该菜单的第二项“Create Controller Scenario(创建控制场景)”,如下图:
这时,lr会弹出一个窗口,我们只要在select scenario type项中的number of vusers设置成1000,这样我们就可以用1000并发用户来测试我们上文中所执行的操作了,如下图:
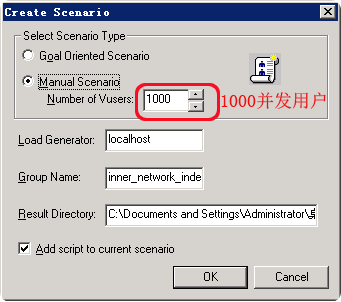
注:之前在上文中设置脚本执行次数为5,这里又做了1000的并发用户,所以最终我们要创建的“主题数”等于:1000*5 = 5000,而这5000主题要在10分钟左右的时间里创建完成,压力不小,呵呵。
完成了这个设计并点击"ok”之后,我们就可以看到我们所设置的场被“创建”出来了,这里我们只要点击"start scenario”就可以启动压力测试了,如下图:
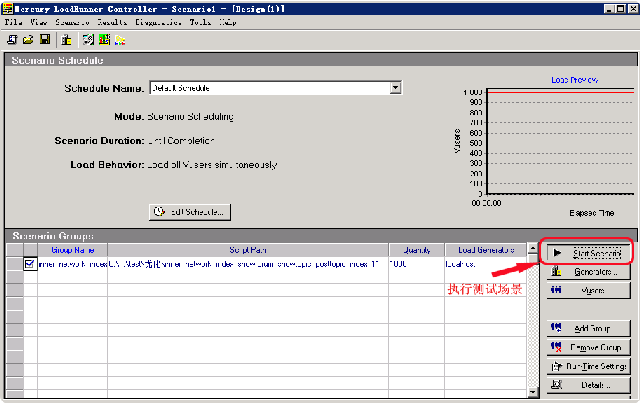
这里lr就可以运行压力测试了,同时我们可以从下图中看到正在测试过程中的各项参数,如下图(注意红字标注部分):
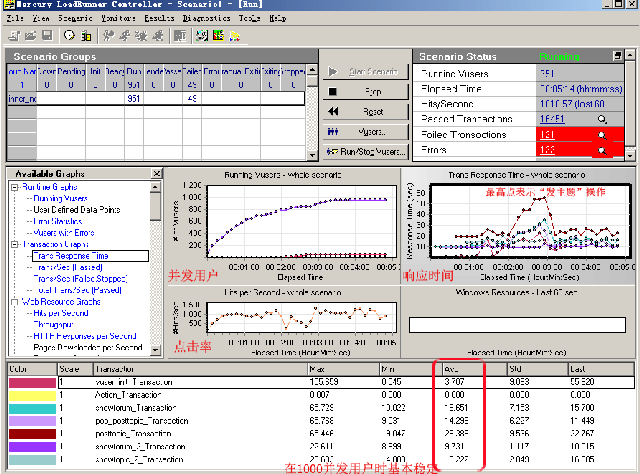
从上图中的“并发用户”图中,大概可以看到,大经销商在5分钟时,并发用户数达到了1000的‘上限’,而在“响应时间”中我们看到“发主题”操作的执行曲线在3分钟时创出响应时间的‘高峰’,且其执行时间普遍高于其它页面。而就在3分钟时并发用户数开始接近于1000,看来大并发对于发主题操作的压力不小呀。其实在正常环境下,用户要求的响应时间维护在3-8秒左右,而像上图所posttopic_transaction中的“平均值”却达到了26秒多,显然是不可接受的,但正如我在前一篇中所说的那样,这次测试是抱着一种将“服务器”压死的目的来测试的,所以设置的参数基本上已接近那台1u服务器所能承受的上限了,当然这会上平均页面的响应时间变得‘过长’,但我认为正是这种‘慢动作’的‘假象’才能让系统处于‘疲于奔命’的情况,也才能让其问题能够暴露的更全面一些。当然除了这种加大并发和工作量的方式之后,在lr中还可以通过设置‘集合点’的方式来制造更大的压力,只不过后者更倾向于对那些正在改进或已改进的程序代码进行压力测试的情况,我会在后面优化程序的时候加以说明。
注:这里有必要介绍一下什么是“点击率(Hits/sec)”, 即每秒点击数,是在场景或会话步骤运行过程中VUser每秒向WEB服务器提交的HTTP请求数. 而上图中就是0--5分钟这段采样时间内VUser平均每秒发送的HTTP请求数。而这个值的图表‘走势’是与系统的‘吞吐量(Throughput)’相对应的,这一点会在生成测试报告时加以解释说明。
一般在这个时间,我会在到达1000并发用户(图中4分钟左右)时,习惯性的去看一下服务器的cpu,内存和网络情况,因为这时如果cpu处于长时间100%时就是已到了系统瓶颈了,下面就是此时服务器端的cpu,内存使用情况:
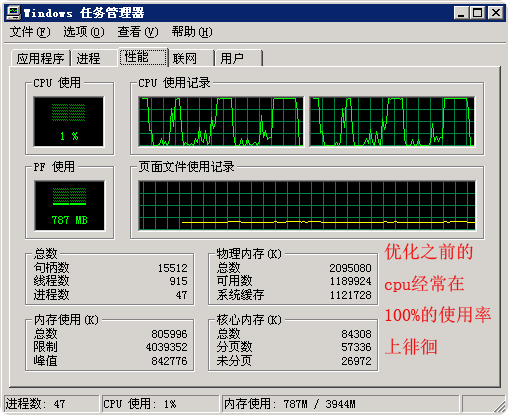
上图中,我们看到cpu经常在100%的使用率上徘徊,并且一旦到了100%的高峰上时,就会持续一段时间,大约为3-5秒,然后就会迅速下跌。这说明系统在此时‘可能’出现了资源争用情况,比如内存,文件或数据库等,而此时图中内存使用情况并不高,可以排除内存方面的问题,还有就是此时的网络情况也并未造成拥塞(如下图:经常处于20-50%的状态下),所以网络方面的因素也应该予以排除了。
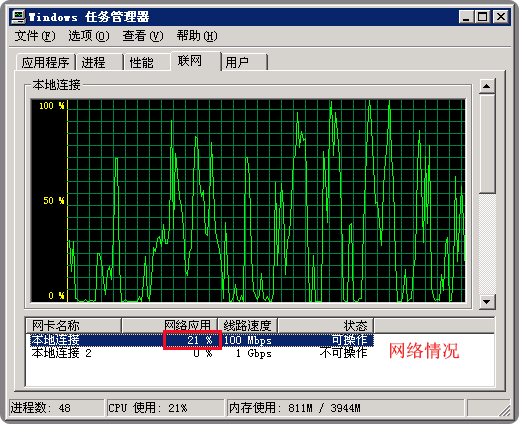
那么就只剩下文件访问和数据库方面的问题了。因为在discuznt中使用了配置文件方式来设置系统参数,并且其文件被加载之后就被static方式进行声明,所以一旦系统运行起来之后,就不会频繁访问文件了,这一点在之前的“Discuz!NT之配置文件类”中已做过说明,所以最后就剩下数据库方面的因素了。
注:如果大家有人能搞到正版lisence的话,就不用这么麻烦了,因为lr会自动收集这方面的信息,可以在生成报造时给我们提供在测试周期内的cpu,内存,网络方面的详细结果,以便于我们在‘决策’时有准确的数据进行参考。而我本人这种做法只是权宜之计,且在准确性上也要打上‘折扣’。
如果一切正常的话,这个测试会在10分钟后运行完毕,这时我们就可以点击‘控制场景’中的工具条上的这个图标来生成测试报告了(终于到了采摘‘胜利果实’的时候了),如下图:
这样lr就会将刚才的测试过程生成一份报告,下面就来介绍一下这个报告(关于如何分析报告以及优化程序,因为内容较多,不可能在本文中详细介绍,只能在下一篇中说明了),如下图:
下面就是其报告首页的介绍(注意红框和说明):
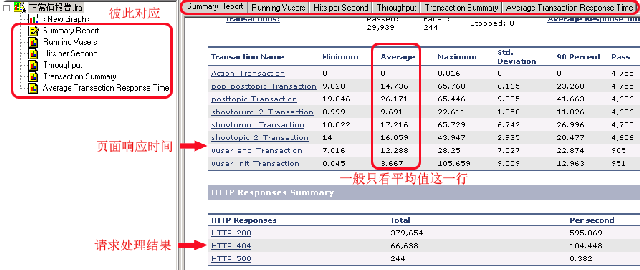
而在首页还有一个信息就是静态统计,如下图(红框部分):
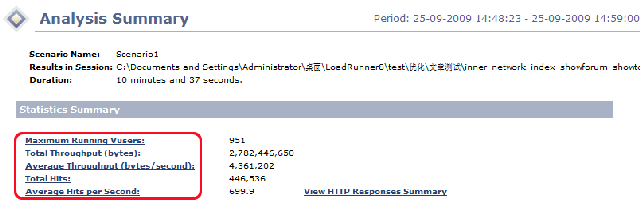
其中:
Maxinum Running Vusers:就是模拟的最大运行用户数(951)人,这里为什么不是1000,我想主要还是与测试过程中的服务运行状态和lr测试机本身的情况所决定的,这个值会随你不断反复测试而有所变化的。
Total Throughput(bytes):即吞吐总量,是在测试过程中场景执行时从Server上接收到的数据总量(以字节为单位,千万别看错单位,要不心脏不好的TX肯定会晕过去了,呵呵)。
Average Throughput(bytes/second):即每秒吞吐量,即在场景执行期间每秒从Server上接收到的数据量的值。这个值一般与网络带宽相比较,用以判断目前的网络带宽是否是瓶颈。
Total Hits:总点击率,在场景或会话步骤运行过程中VUser向WEB服务器提交的HTTP请求总数.
Average Hits per Second:每秒点击数,即在场景或会话步骤运行过程中VUser每秒向WEB服务器提交的HTTP请求数.
看了这些参数,其实我一般很少看它们,因为对于优化程序来说,多数时间是要看运行图形的变化情况,而不是这些统计值或平均数,它们只是告诉你系统的运行情况是好是坏,却不能告诉你系统的瓶颈出在了哪里。下面就来简单介绍一下报告中几个非常重要的图表,首先就是并发用户图:
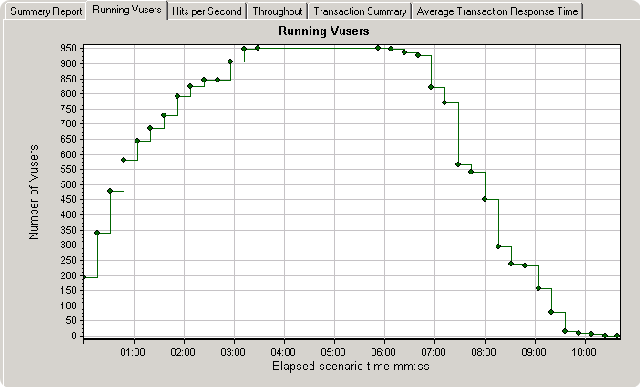
该图显示的是并发用户数量在整个测试周期中的生成情况,可以看到在3分钟后,并发用户数到达了顶峰,并在6分钟后高峰退去。所以在这段时间内是个‘敏感期’,我们要特别重视在这个时间段内系统的反映情况。
接着就是每秒点击率图:

这个图看到在3--6分钟出现了三个高峰(值基本上到达了1300),而这个期间与上面的并发用户高峰时段正好‘稳合’,原因很好解释,必定用户多了,操作多了,自然向服务器提交的http请求就多了。
接下来,再看一下‘吞吐量’:
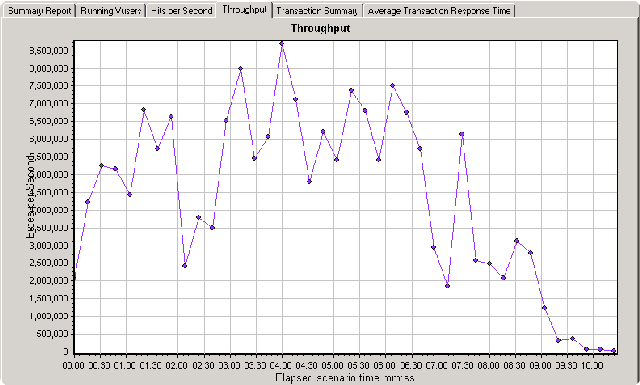
这一张图基本上已上前的点击率图的走势差不多,原因很好解释,因为操作请求多了,服务器端忙了,在服务端能正常处理请求的情况下,自然接收到的数据量相应也会增加了。
下面再介绍一下事务执行情况,这张图可以帮助我们看到那些action执行时出了问题(红色部分为出错),那些工作良好(绿色为良好)。
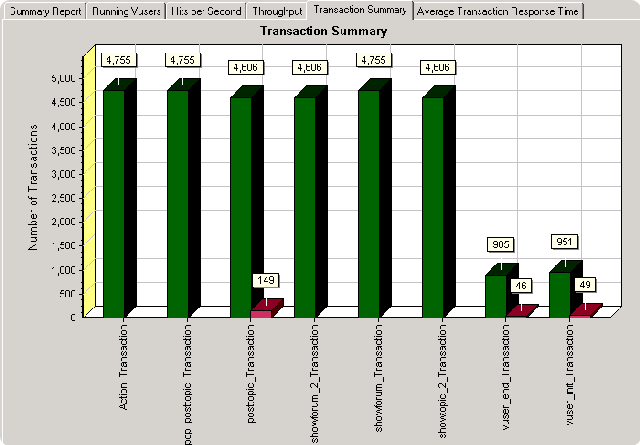
最后一个图就是我经常看的图了,“平均时间响应时间”,它告诉我们那个action的执行时间过长,那些基本稳定,那些先是稳定但大并发来时出了问题。

当然,除了这五个图表之后,lr还提供了更多其它方面的图表,比如页面大小,文件(js,css,aspx等)元素加载时间等,比如下图就是我经常添加的图表:
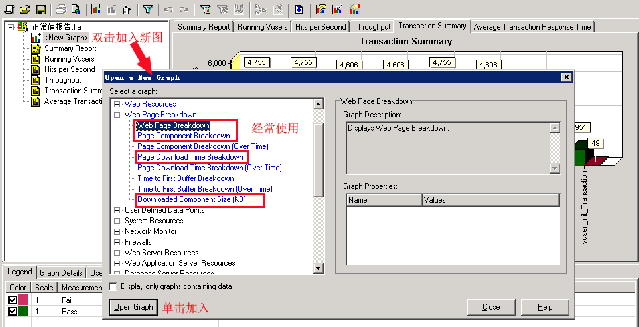
其中:
Web Page Breakdown:会告诉你所做的action中,每个页面(aspx,js,css,img)的加载时间(最大,最小,平均值)
Page Downloaded Time Breakdown: 页面下载时间,包括dns解析时间,首次缓冲时间,发起链接时间等。
Downloaded Component:每个页面体积尺寸,以便于分析那些页面体积过大,从而影响网络传输或处理速度。
最后声明一下,上面这些图只是说明各个图表的性质和作用,并不是优化前的最终测试结果。
在下一篇中,我们通过最终的测试数据来找出系统有那些瓶颈,以及如果优化数据库访问查询,更新等。
好了,今天的内容就先到这里了。
在之前的两篇文章中,基本上介绍了如何录制脚本和生成并发用户,同时还对测试报告中的几个图表做了简单的说明。今天这篇文章做为这个系列的最后一篇,将会介绍如何通过测试报告来查看系统的运行情况,找出影响性能的因素,以及如何去进行优化。
首先,看一下这张并发用户的图:
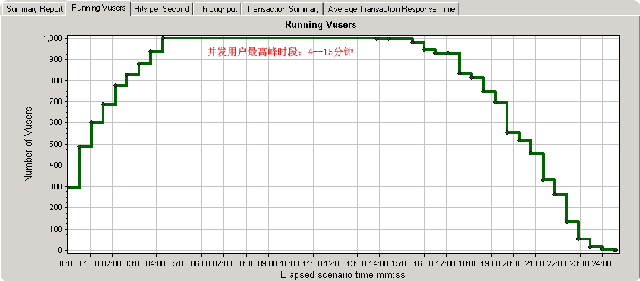
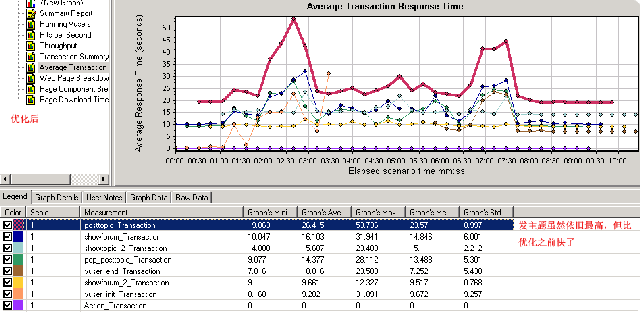
这是在优化之前我生成的测试报告的截图,通过这张图可以看到这个测试过程长达24分钟(这在之前的无数次测试中算是具有代表性的了),
而并发用户峰值是从4--15分钟,持续时间近11分钟。就目前而言,其执行的测试时间和高峰持续时间肯定要比discuz(php)要差了不少,因为dz那边基本上也就是10多分钟就‘完活’了。这里先把这张图放一放,看一下平均事物响应时间这张图, 如下:
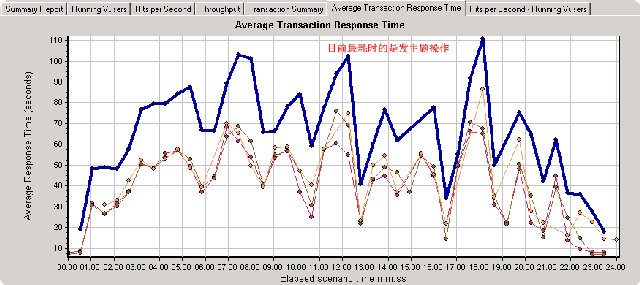
可以看出目前最耗时的操作就是“发主题(posttopic)”了,我们通过在该图上点击鼠标右键,然后选中merge graphs来进行图表合并,这里将并发用户(上图)与本图进行合并:
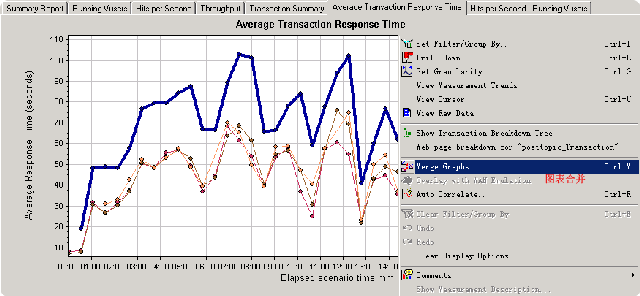
合并之后的图如下,:
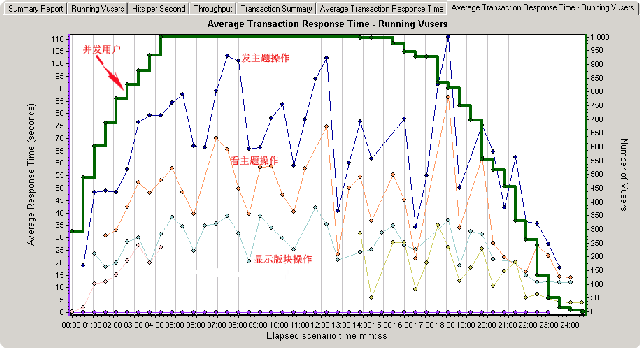
首先可以肯定的是在并发上来时(1000用户,posttopic基本上处于最高位,同时查看主题(showtopic),显示版块(showforum)也有‘走高趋势’)。直到并发过去了之后,用户数下来了,这几个操作的响应时间才又快了起来。其实到这里,我认为可以将posttopic作为优化起点,然后依次是showtopic,showforum事务。注意我这里用的是‘事务’而不是页面,原因很简单,比如posttopic事务内部包括:发主题和跳转到showtopic页面这两个操作(回想一下我在第一篇中的说明)。为了看的更‘清楚’,这里有必要加入几张图,如下:
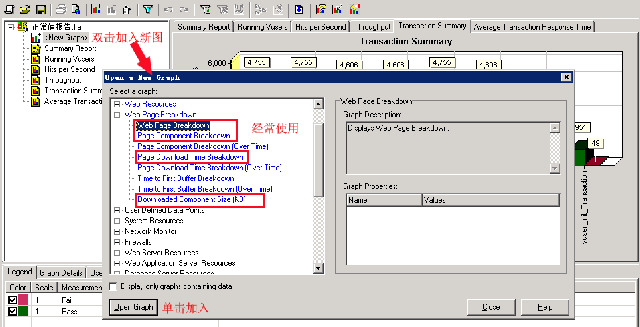
然后点击“opengraph”按钮,加入这四个图,这时我们将web page breakdown打开并定到posttopic_transaction,看一下这个事务中相应
操作的执行情况,如下:

首先一个‘发现’,就是这个页面串不仅仅有之前所说的“发主题”,“显示主题”,还包括另一个ajax请求,且其耗时达到15秒,而这是之前没有想到的,按说不应该在这个事务中出现。换句话说,发主题事务给ajax加载背了‘黑锅’(注:后来经过测试发现,这个请求是在页面加载时就发出了,而原本可以在用户鼠标点击之后再加载),如下:
接着再看一下发主题成功之后,跳转回“显示主题页面”(showtopic)的操作情况:

而下面是posttopic,提交post请求时的处理时间(19秒,虽目前可以接受,但估化之后,这个时间被大幅提升):
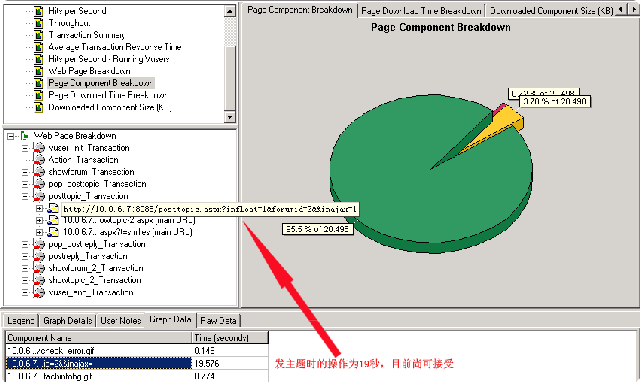
看来光就提交而言,posttopic还是比showtopic快,看来之前的优化顺序要做一下调整,将posttopic与showtopic这两个页面放在同一优先级上进行优化了。下面接着再看一下showtopic这个transaction的执行情况,如下图:
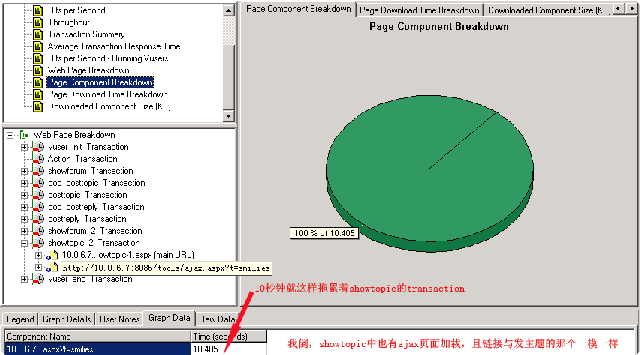
一看吓一跳,怎么这个页面里也有那个ajax加载呀,看来问题不那个简单了,下面再看一下showtopic页面的加载时间:
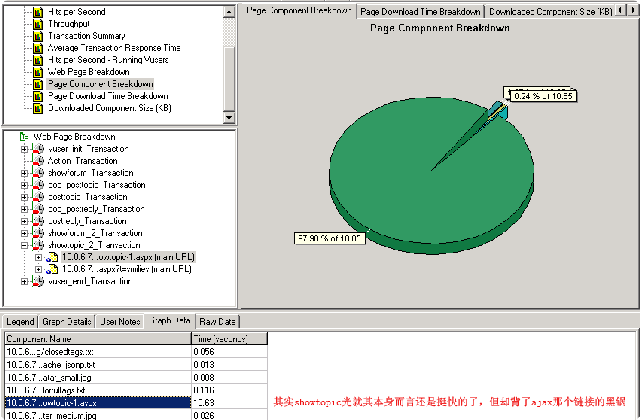
看来这个ajax加载已经像狗皮膏药一样粘在我们产品身体上,赶紧把问题打给相关的开发者吧,呵呵。
在完成了这些事务分析之后,还有一个问题,就是对吞吐量的观察,因为如果吞吐量(Throughput)的曲线随着Vuser数量的增加没有增加,而是呈现出比较平的直线,说明当前的网络速度不能够满足目前的系统的要求,网络造成了瓶颈。为了排除这种可能性,有必要看一下吞吐量这张图,如下:
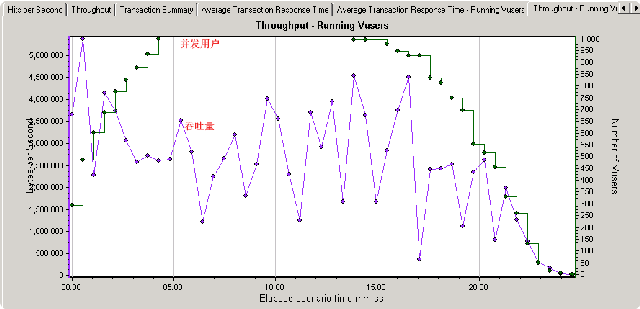
图表显示还是正常的,松了口气(必定是100兆带宽呀)。下面就开始专门优化一下相应的页面和数据访问操作了。
这里,我还是使用了的profiler来观察有那个sql操作被频繁执行,如下图:
注:这里为了简化篇幅,直接将最终的观察结果列了出来。
首先是频繁的在线表操作更新,方法名称:OnlineUser.UpdateAction(…),经过优化,该操作在showforum,showtopic,posttopic页面中的调用次数从两次变成了一次。
接着是对获取用户信息的操作,方法名称:User.GetShortUserInfo(),方法因为在传参时使用了不当的参数,导致在更新用户积分时还需要被执行一到两次。
更新用户积分:Users.UpdateUserCredit(), 这个操作主要用在了posttopic页面中,因为其原来的设计时传参无法做到通用,导致后续开发者不得不再写一个效率不高的方法来满足自己的需要,影响了提交主题页面的执行效率。
当然除了上述三个主要问题外,还有一些别的问题,这里就不一一列举了。当然这些问题都通过重构优化加以解决了(包括之前的ajax请求问题)。所以最终我们看到的优化之后的结果如下(注:为便于对比,我将优化前和优化后的截图一起发上来):
首先是优化前:

优化后:
可以看出主要的页面性能都被提升上来了,特别是posttopic 这个事务,从65提到了26。这里要特别说明的是,在写本文之前,我们还在持续优化程序性能, 所以说“面对优化,只有起点,没有终点”。
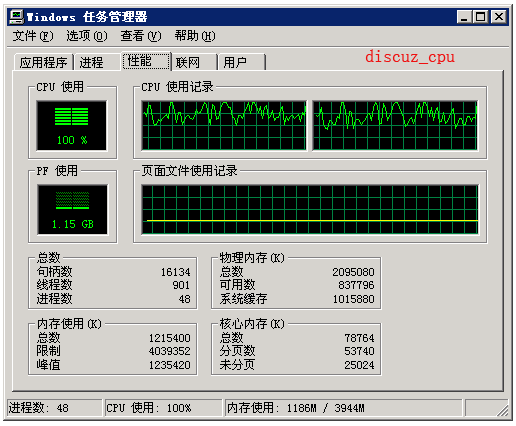
下面是优化前和优化后的1000并发cpu使用率的截图:

优化后的cpu使用率:

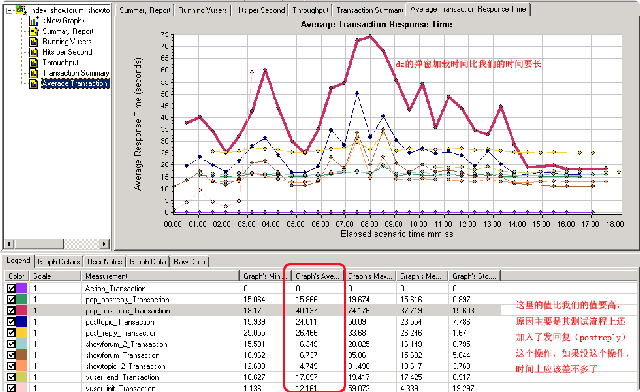
同时,这里再附上一张对discuz进行压力测试时其在1000并发用户时的cpu运行截图:
而discuz的测试报告截图如下:
好了,基本上的流程就介绍完了,下面介绍个小插曲,以免让别人犯跟我一样的错误。
在前一轮优化中,因为我们的产品有弹窗发主题和非弹窗发主题两个设置,而就在对非弹窗发主题时出了岔子,导致我在这个功能测试上花一近1天的时间找原因,如下图:
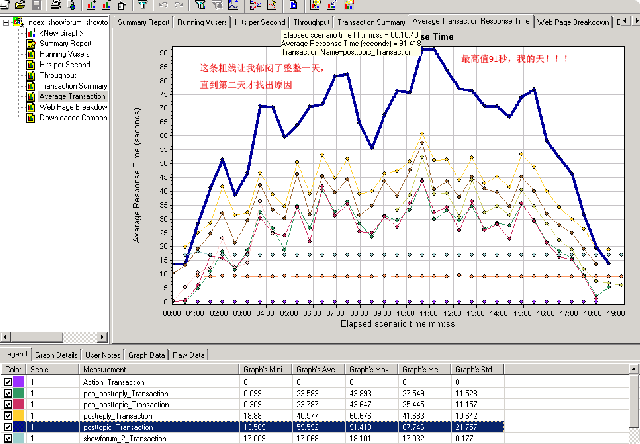
当然因为我们的这个功能用的是一个页面,即posttopic, 而在这个页面的cs中,“非弹窗下”使用了这个方法:SetMetaRefresh(5)
其作用就是在发主题成功后,先不跳转到showtopic页面,而是暂停在本页上5秒中(来显示‘提交成功’这类的信息字样,如下图):

然后再用meta元素跳转到showtopic,而就是这5秒,人为的降低了页面的响应时间,而lr就真‘诚实’地将这5秒也照单记录了下来,导致在这个事务上响应时间高的吓人。而discuz在后台有相应的开关来控制是否显示‘提交成功’。当然现在我们已在后台加入了类似的设置。
另外还有一点就是,通过优化一些重要的页面,还可能带来其它页面执行效率上的提升,必定难做的工作做快了,系统就能腾出手来加快其它工作的执行速度了,呵呵。
其实在lr中,这类东西只是冰山一角,只要你有lisence,你能看到的东西会更多,比如你可以看到cpu上下文切换对系统吞吐量的影响,如下图:
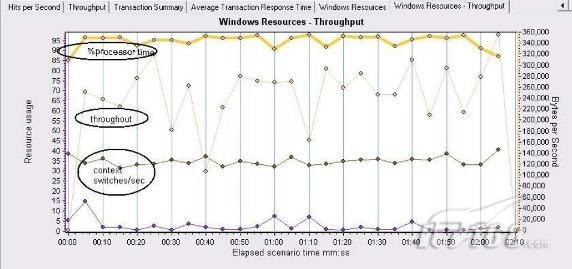
还有如果进行数据库压力测试,设置集合点,参数化等很多有用的功能。
