

函数(python很重要的,可以调用)
一、我们先了解python的结构,
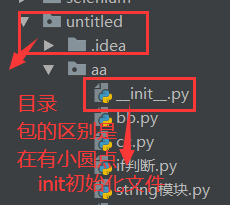
# 1、Python中的先要知道python程序结构:由目录(),包(python package)、模块、函数组成,包里面包含了不同的模块,
# 其中模块中包含了一系列处理一些问题的函数或者类,常量,变量,同时模块可以理解为是一个.py文件(一个.py 文件就是一个模块)
# 注意:
# 1、每个包中都包括"__init__.py"文件,该文件用表示当前目录是一个包
# 2、其中包里面有无数个".py"文件组成,我们可 2020/06/09 14:24 类组成,变量和常量 等。
在C:\Python37\Lib\下的lib下有很多文件(包),点开里面的有很多.py文件
4、对模块进行初始化就需要在包里面创建_init_.py 文件, _init_.py 文件作用就是用来导入包的时候初始化
注意:目录和包的区别:(1)目录没有初始化文件,_init_.py,包里面有 ,件作用就是用来导入包的时候初始化
(2)显示不一样


函数:一个工具,随调随用
# 优点:
(1)降低代码冗余
(2)增加代码的复用性,提高开发效率
(3)提高程序扩展性
(3)函数有两个阶段:定义阶段,调用阶段。
(4)定义时:只检查函数体内代码语法,不执行函数体内代码。
(5)比如:我们存储的过程,就是把所有的语句块,调用
(6)封装:就是把代码片段放在函数当中
第一种函数:
python中有很多内建函数----内建函数(内置函数)
例如:abs
a=-1
print (abs(a))

第二种函数:
自定义函数:==自己根据业务需求自己封装的函数
下面我们重点下python中的函数
如何定义一个函数(自定义函数)
def 来定义一个函数
def 函数名称+英文的小括号()+英文的冒号结尾:
一个tab键就是4个小空格 (字符缩进默认长度是4个空格)
叫函数体
如何实现对函数的调用,来引用函数体中的代码
:函数调用函数体通过函数自己调用自己本身,函数调用函数自己(名称)
--------------------------------------------------------

举例1:
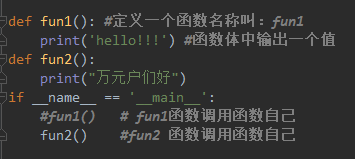
def fun1(): #定义一个函数名称叫:fun1
print('hello!!!') #函数体中输出一个值
fun1() #函数调用函数自己 hello!
---------------------------------------------------------------------------------------------------------
调用方法:
第一种调用方法:
格式:
#自定义一个函数:
def fun(): #定义一个函数名称叫:fun 函数名称可以自定义
pass #函数体
fun() #函数来调用函数自己本身来得到函数体中的结果
--------------------------------------------------------
第二种调用方法 (这种方法经常用来做调试)
def fun1(): #定义一个函数名称叫:fun1
print('hello!!!') #函数体中输出一个值
def fun2():
print("万元户们好")
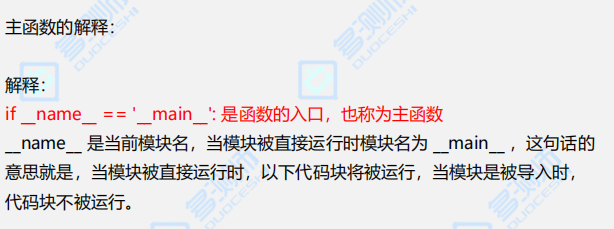
if __name__ == '__main__':
#fun1() # fun1函数调用函数自己
fun2() #fun2 函数调用函数自己
注意点:直接输入一个main ,在按tab键联想 ,就可以关联出来
这种调用的好处:就是可以在多个函数调用其中的几个就方便;
if __name__ == '__main__':#函数入口,当模块名等于要被主函数则执行如下代码
注意:主函数的入口下注释要用占位符pss,
函数的入口只能在本模块调用 ,以上两种都是在本模块的调用;
注意:如果调不了,就是命名的问题,不要和python中的命名一样
--------------------------------------------------------
第三种方法:调用其他模块
举例:
aa模块
bb模块
备注:要使用import导入
场景一:
bb文件中内容
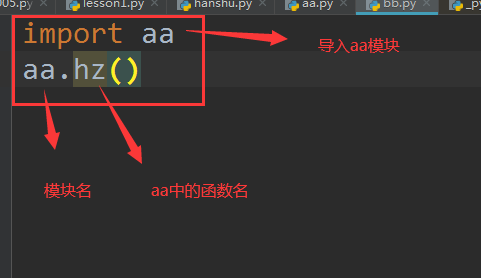
场景二:
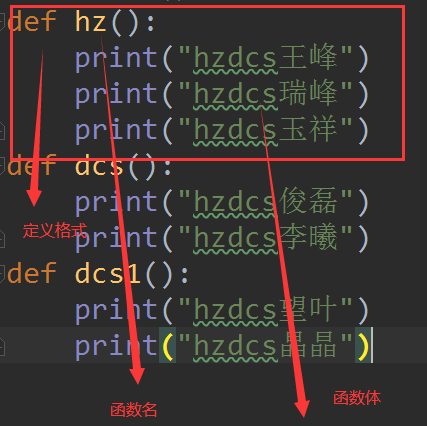
-----------------------------------------------------------------------------------------

# 3、#函数参数:
# 参数分形参、实参
# 形参:函数定义时括号内的参数
# 实参:函数调用时括号内的参数
# 形参相当于变量,实参相当于变量的值。
# 定义时:
举例1:
def func(a, b, c): # a, b, c为形参
print (a+b+c)
func(1, 2, 3) # 1, 2, 3 为实参

定义:
形参: 只在被调用时,才分配内存单元。调用结束,立刻释放所分配的内存。(形参只在函数内部有效)
实参:常量、变量、表达式、函数。 进行函数调用时,实参必须是确定的值。
位置参数:
位置形参:函数定义时,从左往右写的参数,比如上面的 a, b , c
位置实参:函数调用时,从左往右写的参数, 比如上面的 1,2,3
位置形参定义多少个,调用时位置实参必须写上多少个,多一个少一个都不行。
关键参数:
正常情况下,给函数传参数,要按顺序。如果不想按顺序,就用关键参数。
指定参数名的参数,就叫做关键参数。
函数调用时:func(a=1, b=2), 这种指定了参数名的参数,就是关键参数。
调用函数时,关键参数可以和位置参数一起用,但是关键参数必须在位置参数的后面。不然会报错。
默认参数:
函数定义时,默认参数必须在位置形参的后面。
函数调用时,指定参数名的参数,叫关键参数。
而在函数定义时,给参数名指定值的时候,这个参数叫做默认参数。
关键参数,和默认参数两个参数写法一样,区别在于:
关键参数是在函数调用时,指定实参的参数名,也可以说指定值的参数名。
默认参数是在函数定义时,指定参数名的值。
举例2:不带参数的函数
def fun():
print ('欢迎来到多测师')
fun() # 调用函数
举例3:#函数中有单个参数
#函数中有单个参数
def func(name):
print ("欢迎"+name+"来到多测师")
func("大家")
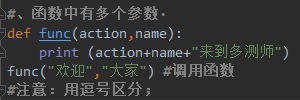
举例4:
#、函数中有多个参数·
def func(action,name):
print (action+name+"来到多测师")
func("欢迎","大家") #调用函数
#注意:用逗号区分
举例5:
#函数定义时带上默认参数(缺省参数)(也叫默认参数)
def func(action,name, where="多测师"):
print(action+name+"来到"+where)
func("欢迎","大家" )
#调用函数未给默认参数传新值,则函数使用默认值 # func("欢迎","大家","杭州多测师")
func("欢迎","大家","宝安多测师")
注意:当多种参数同时出现在函数中,默认参数要放在最后的位置,不能放在形式参数的前面

举例6:

在函数中可变长元组和可变长字典的引用
可变长的元组:* 可变长字典:**
6.1
def fun1(*name): #定义一个函数形参类型通过*号改变为可变长元组
print(name)
print(type(name)) #<class 'tuple'>元组的类型
fun1("zhangsan ","lisi") #函数调用时可以赋予对应形参多个实参
打印结果为:(zhangsan, lisi)

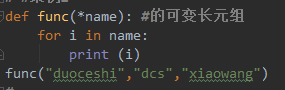
6.2
def func(*name): #遍历的可变长元组
for i in name:
print (i)
func("duoceshi","dcs","xiaowang")
小结: '''可变长定义:定义一个可变长元组后,函数调用处,可以给当前可变长形参赋予N个实参
如没有定义是可变长元组:在函数调用处只能给对应形参对应个数的具体实参'''
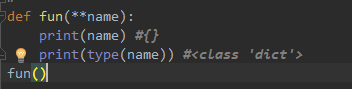
案例7:
7.1案例
def fun(**name): #可变长字典
print(name) # 打印结果是{}
print(type(name)) #打印结果:<class 'dict'>
fun()
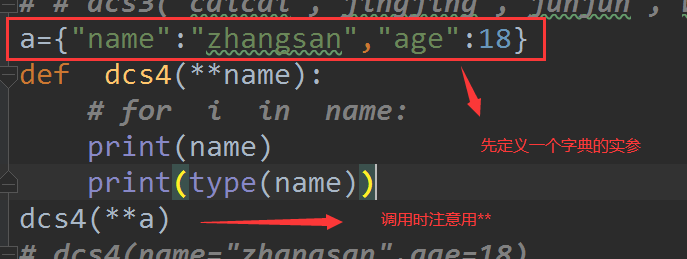
7.2案例
def fun1(**name): #定义一个函数 形参定义为可变长字典类型
print(name) #打印字典
if __name__ == '__main__':
fun1(name='zhangsan',age=18) #{'name': 'zhangsan', 'age': 18}

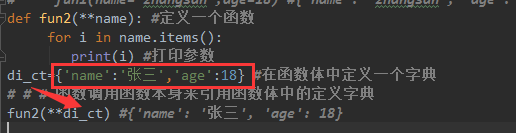
7.3案例
def fun2(**name): #定义一个函数
for i in name.items():
print(i) #打印参数
di_ct={'name':'张三','age':18} #在函数体中定义一个字典
fun2(**di_ct) # {'name': '张三', 'age': 18} # 函数调用函数本身来引用函数体中的定义字典
7.4案例 可变长字典后面不能接普通形参变量
def fun(a,**name,c):
print(name)
fun() # 打印结果:SyntaxError: invalid syntax
小结:(1)如当前函数中定义的是可变长字典:字典后后面不能在定义普通的形参变量,也不能定义可变长元组:
(2)元组的后是可以在定义一个普通形参变量,也可以在后面定义一个可变长字典'''
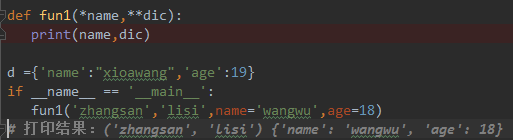
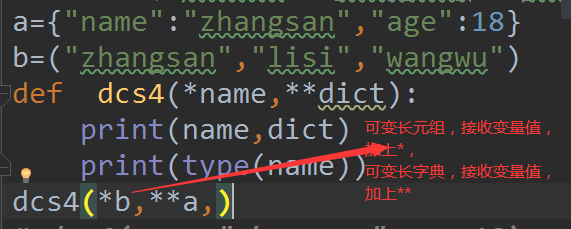
案例8:函数中同时出现可变长元组和可变长字典
8.1
def fun1(*name,**dic):
print(name,dic)
d ={'name':"xioawang",'age':19}
if __name__ == '__main__':
fun1('zhangsan','lisi',name='wangwu',age=18)
8.2
def fun1(*name,**dic):
print(name,dic)
d ={'name':"xioawang",'age':19}
if __name__ == '__main__':
fun1('中国',**d) # 实参‘中国’,可变长字典**d
打印结果('中国',) {'name': 'xioawang', 'age': 19}
注意点:当可变长元组和可变长字典同时出现时,默认将可变长字典放后面

-------------------------------------------------------------------------
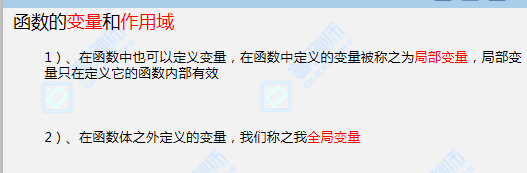
局部变量 和全局变量
案例:

举例:
全局变量:
场景一:(全局变量和局部变量)
num =200 #定义一个变量num 赋予一个值200 当前变量为全局的变量
def fun(): #定义一个函数
num=100 #在函数中定义一个变量num=100 ##当前函数体中的这个num:局部变量
print(num) #打印的结果为:函数内部变量的num=100
fun() #函数调用函数自己本身得到结果为:100
print (num) #打印全局变量 #打印结果:200
场景二:(全局变量和局部变量 都存在:优先引用局部变量)
案例1:
num=200 #全局变量
def func():
num=100 #局部变量
print (num) #打印局部变量
func() #函数调的是局部变量 100
案例2:
num =200 #定义一个变量
def fun():#定义一个函数
num=100 #在函数中定义一个变量
a=num/2 #定义一个变量 :通过num /2
print(int(a)) #打印变量
fun()#函数调用 #打印结果:50
场景三:(只有全局变量,不存在局部变量,直接调用全局变量)
num1 =300
def fun():
print(num1) #300
fun()
场景四:(只有局部变量,不存在全局变量,直接调用局部变量)
def fun():
a=20 #局部变量
print(a)
fun()

全局变量的引用:
a=10 #全局变量
def fun():
b=a+20 #局部变量
print(b)
fun()
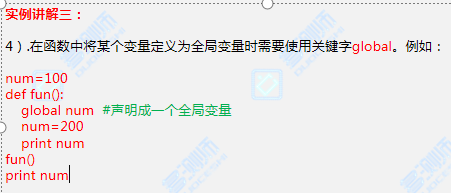
global设置全局变量:
num=200
def fun():
global num #将num变量声明成为一个全局(重新声明一个全局变量)
num=100
print(num)
fun() #结果为:100 #声明全局变量优先级高于函数外的全局变量
注意: 那么当前声明的全局优先级要比直接在函数外声明的全局要高
----------------------------------------------------------------------
return返回值


场景一:(将函数中的返回值,传递到另一个函数中)
函数中的返回值的作用:((函数的调用,函数中有返回值才是一个完整的函数去调用)
def fun(): #定义的一个函数
num =100
a=num/2
#print(a) #50.0
return a
# return 下面的代码是不会被运行的
fun()
#'''函数的传递'''
def fun1():
c=fun() #函数传递,把fun函数中的50拿过来赋值给c那么当前c=50
# print(c) #50.0
c*=2
print(c) #100.0
fun1()

例如:
方法一:
def fun1():
user_name=input('输入账号:')
if user_name =='admin':
user_pwd=input('输入密码:')
if user_pwd =='123456':
user_yzm=input('输入验证码:')
if user_yzm =='abc123':
print('登录成功')
return True
else:
print('验证码错误!!')
return False
else:
print('密码错误!!')
else:
print('账号错误!!')
def fun():
a=fun1()
if a ==True:
print('查询的余额为:¥8888888888.00')
else:
pass
fun()
方法二:
def fun():
a ='查询的余额为:¥8888888888.00'
return a
fun()
def fun1():
user_name=input('输入账号:')
if user_name =='admin':
user_pwd=input('输入密码:')
if user_pwd =='123456':
user_yzm=input('输入验证码:')
if user_yzm =='abc123':
print('登录成功',fun())
else:
print('验证码错误!!')
else:
print('密码错误!!')
else:
print('账号错误!!')
fun1()
-----------------------------------------------------------------------------------------------------------------------------
内置函数:
我们讲解的有format,zip,open
----------------------------------------------------------------------------------------------------------------------

举例:1、不设置指定位置,按默认顺序打印出来
场景一:
(1.1)一个{}显示一个字符
a ='{}'.format('hello','ni','hao')
print(a) #打印结果 hello
(1.2)两个{}显示两个字符
a ='{}{}'.format('hello','ni','hao')
print(a) # 打印结果hello ni
(1.3)超出范围{}{}{}{},报错:(内容tuple index out of range)
a ='{} {} {} {}'.format('hello','ni','hao')
print(a) #{}可以小于等于具体的值,但是不能大于否者抛异常
场景二:设置指定的位置
2.1 { 1} 大括号内输入索引.format( 内容 ) ,#结果根据索引输出结果
a ='{1} {0}'.format('hello','ni','hao')
print(a) #打印结果:ni hello
2.2换个写法:把输出的的位置按变量的方式输出
name = "我叫{0},年龄{1}-{0}-{0}"
val = name.format('帅哥',"18岁")
print(val) #打印结果:我叫帅哥,年龄18岁-帅哥-帅哥
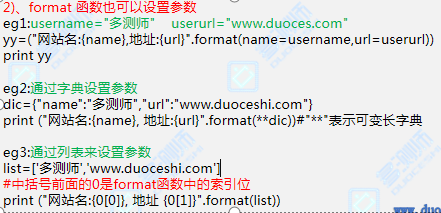
案例:
场景一:函数也可以设置参数
1,1d ="姓名:{name} 年纪:{age}".format(name='张三',age=18)
print(d) #姓名:张三 年纪:18
场景二:通过字典设置参数
2.1
name = "我叫{name},年龄{age}"
dic = {'name':'杭州','age':18}
val = name.format(**dic)
print(val)
备注:1、格式化{}中输入键
2、format括号内用**字典变量名
2.2
a={"name":"多测师","url":"www.duoceshi.com"}
b="网站名:{name}, 地址:{url}".format(**a)
print(b)
场景三:对列表进行格式化
3.1
a=['多测师','www.duoceshi.com']
#大括号里面的0代表的是列表、中括号里面的0和1表示列表元素对应的索引位
b="网站名:{0[0]}, 地址 {0[1]}".format(a)
print(b) #打印结果:网站名:多测师, 地址 www.duoceshi.com
3.2当多个列表时取值,根据列表的格式如:0表示第一个列表,1表示 第二个列表
a =[1,2,3,4] #0
a1=[5,6,7,8] #1
a2=[9,10,11,12] #2
a ='{2[1]} {2[2]}'.format(a,a1,a2)
print(a)
注意:列表排序 0,1,2

-----------------------------------------------------------------------------------------------------
zip

zip函数就是:将两个列表进行拼接返回一个个的元组(将对应的元素打包成一个个元祖)
l =[1,2,3,4] ll=[5,6,7] lll=[8,9,10] a =zip(lll,ll) b =zip(l,ll) print(a) #打印结果<zip object at 0x00000000027819C8>(对象) print(list(a)) #打印结果 [(8, 5), (9, 6), (10, 7)] # list() 转换为列表 print(list(b)) # 打印结果[(1, 5), (2, 6), (3, 7)]#元素个数与最短的列表一致
注意: 取值的要求:必须两两为真才取,一真一假不取
场景一:zip拼接后返回list格式 list
print(list(zip(l,ll)))
场景二:zip拼接以后返回字典格式 dict
print(dict(zip(l,ll)))
场景三:zip拼接以后返回 元组tuple
print (tuple(zip(l,ll)))
打印的结果是一个元组
场景四:zip拼接以后返回 zip
print (zip(zip(l,ll))) #打印结果是一个对象
场景五:zip 拼接以后直接答应,也是显示一个对象
print(zip(l,ll))
zip(*)解压
s,c =zip(*zip(l,ll)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式 print (list(s)) #打印结果 print (list(c)) #打印结果
案例:将两个列表转换成字典
解答:方法一:
a=['name','url']
b=['duoceshi','www.duoceshi.cn']
#c=zip(a,b) #通过zip方法转换成元组放入列表当中
#print(list(c)) #打印结果:[('name', 'duoceshi'), ('url', 'www.duoceshi.cn')]
d = dict(zip(a,b)) #利用字典的方法转换成字典
print(d)
-----------------------------------------------------------------------------------------------------------
open

第一种方法:读取绝对路径
场景一:
b=open(r"C:\Users\Administrator\PycharmProjects\untitled1\requester\ss.py","r",encoding="utf-8")
print (b.read())

open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
备注:路径问题:解决方一:\\ ;解决方法二;加 r
打开文件的模式有:
#文件句柄 = open('文件路径', '模式')
r,只读模式(默认)。
w,只写模式。【不可读;不存在则创建;存在则删除内容;】
a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
r+,可读写文件。【可读;可写;可追加】
w+,写读
a+,同a
#完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:
备注:查看用法ctrl+鼠标+移动到使用的函数
第二种方法:读取引用本地的文件
场景一:读取文件所有内容read
t =open(r'D:\bao\aaaa.txt','r') print(t.read()) #读取文件所有内容 #显示文件aaaa bbbb cccc dddd 1111 2222 3333 4444
场景二:读取文件中第一行readline
t =open(r'D:\bao\aaaa.txt','r') print(t.readline())#只读取第一行 #打印结果:aaaa
print(type(a.readline())) 打印的结果是:str类型
场景三:读取所有返回一个列表readlines
t =open(r'D:\bao\aaaa.txt','r') print(t.readlines())#读取所有返回一个列表
#打印结果:['aaaa\n', 'bbbb\n', 'cccc\n', 'dddd\n', '1111\n', '2222\n', '3333\n', '4444']
场景四: readlines 通过遍历来显示文件内容
t =open(r'D:\bao\aaaa.txt','r')
a =t.readlines()
for i in a:
print(i)
注意点:
引用本地电脑中的文件,对于中文可以进行转译 引用工具中的文件file创建的,对于中文不能进行转译,需要定义一个编码格式encoding='utf-8'


解决:读取路径中的中文encoding=“utf8”
错误场景一:
url ='C:/Users/Administrator/PycharmProjects/untitled/python/002作业.py ' a=open(url,'r') print(a.read())
打印报错结果:
print(a.read()) #结果: 无效参数OSError: [Errno 22] Invalid argument: 'D:\x08ao\\多测师\x07a.txt'
UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 14: illegal multibyte sequence
正确场景二:
url ='C:/Users/Administrator/PycharmProjects/untitled/python/002作业.py ' a=open(url,'r',encoding='utf-8') print(a.read())

在open函数中w权限:替换
场景一: write写入文档,把之前文档覆盖
url =r'C:\Users\Administrator\PycharmProjects\untitled1\requester\ss.py'
a =open(url,'w',encoding='utf-8')
a.write('多测师大佬!!!!')
a.close() #覆盖后关闭当前文件释放资源
场景二:writelines写入文档,把之前文档覆盖
url =r'C:\Users\Administrator\PycharmProjects\untitled1\requester\ss.py'
a =open(url,'w',encoding='utf-8')
a.writelines('多测师11')
a.close() #覆盖后关闭当前文件释放资源
查看语句
b=open(url,"r",encoding='utf-8')
print(b.read())
#
--------------------------------------------------------------------------------------------------------
a追加在open函数中
url =r'C:\Users\Administrator\PycharmProjects\untitled1\requester\ss.py'
a =open(url,'a',encoding='utf-8')
a.write('杭州')
url =r'C:\Users\Administrator\PycharmProjects\untitled1\requester\ss.py'
a =open(url,'a',encoding='utf-8')
a.write('杭州')
#查看 追加内容
b=open(url,"r",encoding='utf-8')
print(b.read()) #打印显示' 多测师11杭州'
b.close()
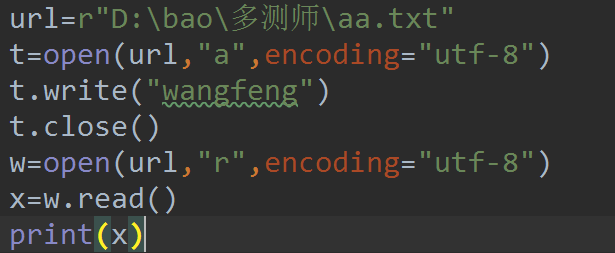

# #open()函数扩展用法
url =r'C:\Users\Administrator\PycharmProjects\untitled1\requester\ss.py'
with open(url,'r',encoding='utf-8')as o:
a=o.read()
print(a)
# #用with语句的好处,就是到达语句末尾时,会自动关闭文件,即便出现异常
场景一:读取所有内容
with open(r"D:\bao\aaaa.txt", 'r' )as f:
# a = f.read()
# print (a)
场景二:读取一行
with open(r"D:\bao\aaaa.txt", 'r' )as f: b = f.readline() print(b)
场景三:
with open(r"D:\bao\aaaa.txt", 'r' )as f: c = f.readlines() print(3)
场景四:写入
with open(r"D:\bao\aaaa.txt", 'r' )as f: d = f.write() print(d)
场景五:写入一行
with open(r"D:\bao\aaaa.txt", 'r' )as f: e = f.writelines() print(e)
练习题:
题目:字符串 hellword ni hao ya 将字符转换为:hellword%$ni%$haoya
方法一:
#场景一:
def fun(): # s="hollword ni hao ya" # c=s.split(' ') # print("%$".join(c)) # fun() 场景二: # def fun1(): # m = "hollword ni haoya" # n ='' # for i in range(len(m)): # if m[i]==' ': # n+='%$' # else: # n+=m[i] # print(n) # fun1()
场景三:
str='hellword ni hao ya'
b=str.split(' ')
print(b)
# print(type(b))
c="{0[0]}%${0[1]}%${0[2]}{0[3]}".format(b)
print(c)
场景四:
str="hellword ni hao ya"
a=str.split(" ")
b=a[1]
c=a[2]
e=b.replace(" ","")
f=c.replace(" ","")
y="{a1[0]}%${b1}%${c1}{a1[3]}".format(b1=e,c1=f,a1=a)
print(y)
场景五:直接替换
a='hellword ni hao ya'
b=a.replace(' n','%$n')
c=b.replace(' h','%$h')
d=c.replace(' y','y')
print(d)
场景六:赋值
list1='hellwordnihaoya'
str=list(list1)
str[7]="d%$"
str[-6]='i%$'
print(''.join(str))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号