
import re
# 一、常用方法:
# match():从头匹配
# search():从整个文本搜索
# findall():找到所有符合的
# split():分割
# sub():替换
# group():结果转化为内容
# groupdict():结果转化为字典
二、常用的正则表达式符号
# '^'匹配字符开头
#
# '$'匹配字符结尾
#
# '*'匹配*号前的字符0次或多次
#
# '+'匹配前一个字符1次或多次
#
# '?'匹配前一个字符1次或0次
#
# '{m}'匹配前一个字符m次
#
# '{n,m}匹配前一个字符n到m次
#
# '|'匹配符号两边的任意一个,相当于或
#
# '(...)'分组匹配
#
# '\A'只从字符开头匹配,比如re.search("\Aabc","gggggabc") 是匹配不到的
#
# '\Z'匹配字符结尾,和$一样
#
# '\d'匹配数字0-9
#
# '\D'匹配非数字
#
# '\w'匹配[A-Za-z0-9]
#
# '\W'匹配非[A-Za-z0-9]
#
# '\s'匹配空白字符、\t、\n、\r
三、
match

# (1).:默认匹配除\n之外的任意一个字符。'''
# s='abc123wfj456'
# c = re.match('....', s) #match():从头匹配
# print(c.group()) # 结果:abc1 group():结果转化为内容
# #(.)代表一个字符
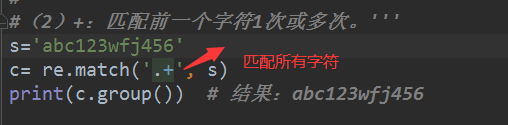
#(2)+:匹配前一个字符1次或多次。'''
s='abc123wfj456'
c= re.match('.+', s)
print(c.group()) # 结果:abc123wfj456

#(3)^:从开头匹配字符。'''
s='abc123wfj456'
c = re.match('^abc\d+', s) #\d表示字符
print(c.group()) # 结果:abc123
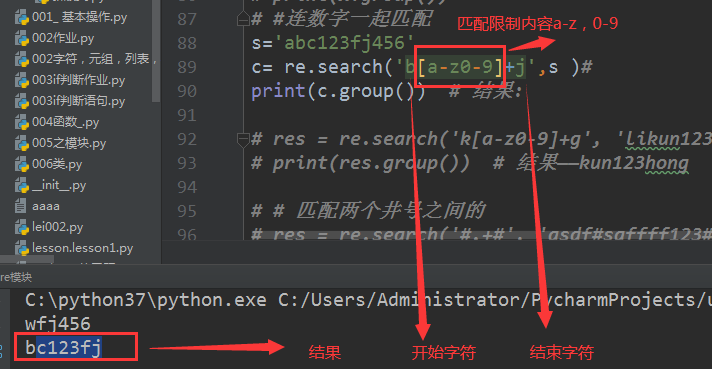
search方法
# (4)字母数字一起匹配
# s='abc123fj456'
# c= re.search('b[a-z0-9]+j',s )#
# print(c.group()) # 结果:bc123fj
x = re.search('a[a-z0-9]+v', 'aaaaa1111444avbdfff')
print(x.group()) # 结果

search方法
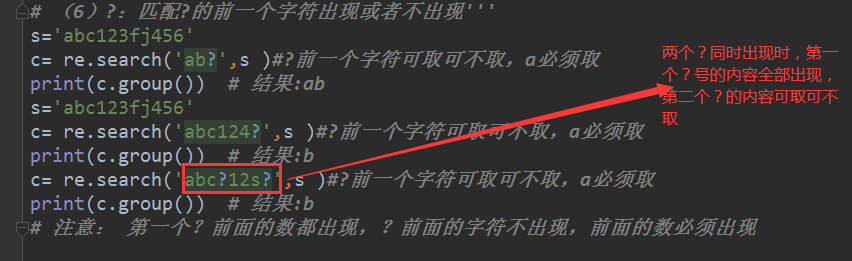
(5)?:匹配?的前一个字符出现或者不出现'''
s='abc123fj456'
c= re.search('ab?',s )#?前一个字符可取可不取,a必须取
print(c.group()) # 结果:ab
search方法
(6)
c= re.search('abc?12s?',s )#?前一个字符可取可不取,a必须取
print(c.group()) # 结果:b
# 注意: 第一个?前面的数都出现,?前面的字符不出现,前面的数必须出现
# s='abc123fj456'
# c= re.search('ab?',s )#?前一个字符可取可不取,a必须取
# print(c.group()) # 结果:ab
# s='abc123fj456'
# c= re.search('abc124?',s )#?前一个字符可取可不取,a必须取
# print(c.group()) # 结果:abc12
# c= re.search('abc?12s?',s )#?前一个字符可取可不取,a必须取
# print(c.group()) # 结果:abc12
# # 注意: 第一个?前面的数都出现,?前面的字符不出现,前面的数必须出现

search方法
# (7)|:或'''
s='abc123fj456'
c= re.search('abc|123',s )#匹配符号两边任意一个,如果都存在就从左开始取
print(c.group()) # 结果:ab
s='abc123fj456'
c= re.search('abd|123',s )#匹配符号两边任意一个,如果都存左边不存在,就取右边
print(c.group()) # 结果:123

search方法
(8)s='yihang18boss01'
c= re.search("(?P<name>[a-zA-Z]+)(?P<age>[0-9]+)(?P<job>\w+)", s).groupdict()
print(c)
# 结果为:{'name': 'yihang', 'age': '18', 'job': 'boss01'}
#备注:groupdict():结果转化为字典 ;? 匹配前一个字符1次或0次;[]:限制''',\w+匹配[A-Za-z0-9]

search方法
(9)
s = '362421199806106218'
c = re.search('(?P<province>\d{3})(?P<shi>\d{3})(?P<birth>\d{8})(?P<num>\d{2})(?P<last>\d{2})', s).groupdict()
print(c)
# 结果为:{'province': '362', 'shi': '421', 'birth': '19980610', 'num': '62', 'last': '18'}

split方法
(10)
# #split()分割'''
# res = re.split('[a-z]+', 'ab23bas23basd9989ad')
# print(res) # 结果为['', '23', '23', '9989', '']
# res = re.split('[1-9]+', 'ab23bas3basd9989ad')
# print(res) # 结果为['ab', 'bas', 'basd', 'ad']
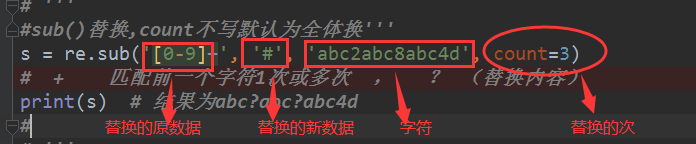
sub方法
(11)
#sub()替换,count不写默认为全体换'''
s = re.sub('[0-9]+', '#', 'abc2abc8abc4d', count=3)
# + 匹配前一个字符1次或多次 , ? (替换内容)
print(s) # 结果:abc#abc#abc#d

match方法
(12)
aa=re.match('\d+',a) #
print (aa.group()) #通过group函数获取对象中的结果
b='a2233113abf123'
bb=re.match('\d+',b) #
print (bb.group()) #通过group函数获取对象中的结果

match方法
(13)
#大写的D:匹配非数字
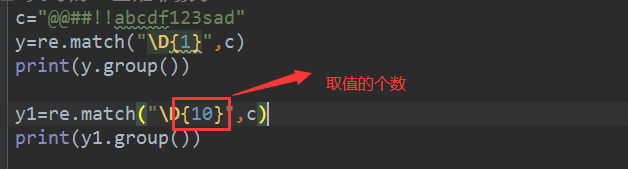
c="@@##!!abc123sad"
y=re.match("\D{1}",c)
print(y.group())
match方法
(14)
y1=re.match("\D{10}",c)
print(y1.group())

find all 方法
(15)
# import re
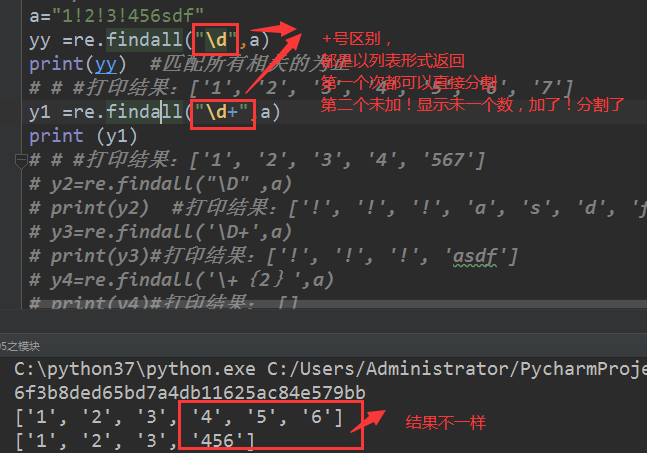
a="1!2!3!4asdf567"
yy =re.findall("\d",a)
print(yy) #匹配所有相关的为止
# # #打印结果:['1', '2', '3', '4', '5', '6', '7']
find all 方法
(16)
# import re
a="1!2!3!456sdf"
yy =re.findall("\d",a)
print(yy) #匹配所有相关的为止
# # #打印结果:['1', '2', '3', '4', '5', '6', '7']
y1 =re.findall("\d+",a)
print (y1)
拓展:
compile 方法O(只是用来编译
)
compile 方法
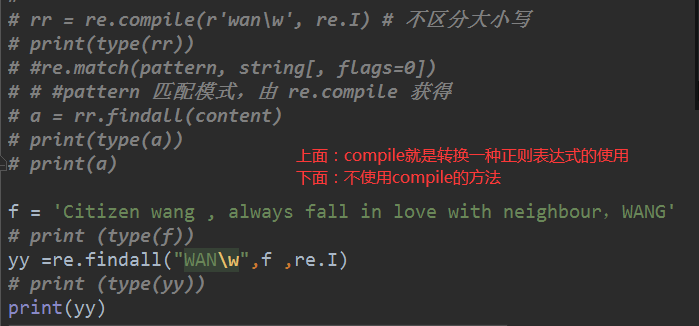
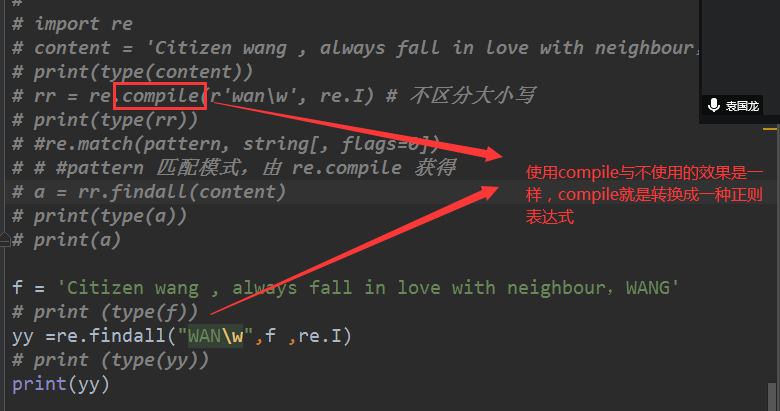
# import re
# content = 'Citizen wang , always fall in love with neighbour,WANG'
# print(type(content))
# rr = re.compile(r'wan\w', re.I) # 不区分大小写
# print(type(rr))
# #re.match(pattern, string[, flags=0])
# # #pattern 匹配模式,由 re.compile 获得
# a = rr.findall(content)
# print(type(a))
# print(a)
f = 'Citizen wang , always fall in love with neighbour,WANG'
# print (type(f))
yy =re.findall("WAN\w",f ,re.I)
# print (type(yy))
print(yy)
import re
pattern = re.compile(r'[a-z]+')
res = pattern.findall('123abc456cde')
print(res)
text="JGod is a handsome boy ,but he is a ider"
regex=re.compile(r'\w*o\w*')
print (regex.findall(text))
备注拓展:
# re.I(re.IGNORECASE)
# 使匹配对大小写不敏感
# re.L(re.LOCAL)
# 做本地化识别(locale-aware)匹配
# re.M(re.MULTILINE)
# 多行匹配,影响 ^ 和 $
# re.S(re.DOTALL)
# 使 . 匹配包括换行在内的所有字符
# re.U(re.UNICODE)
# 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
# re.X(re.VERBOSE)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号