

肖sir__ python自动化之selenium9.1
python+selenium
selenium是一个第三方库,python有很多库;
1、什么是ui自动化?
通过模拟手工操作用户ui页面的方式,用代码去实现自动化操作和验证的行为。
2、ui自动化的优点?
(1)解决重复性的功能测试和验证
(2)减少测试人员在回归测试时用例漏测和验证点的漏测
(3)减少冒烟测试,回归测试的人力成本,节省时间,提高测试效率
3、ui自动化缺点?
(1)需求不稳定,比如,敏捷开发速度快,ui频繁变更,定位不稳定,提高了用例维护的成本
(2)用例的覆盖率少,占用例总数的15%-30%
(3)场景覆盖占当前功能场景70%-80%
4、ui自动化和功能测试那个更重要?
都重要
原因:(1)功能测试是基础,在熟悉功能的前提下才能做好ui自动化





安装方法1:
1、安装selenium命令(在dos命令中cmd )
pip install selenium==3.141.0 (python3中pip.exe默认在python的Scripts路径下)
2、可使用以下命令查看是否安装成功:
pip list

2、直接把site--packages.rar包 selenium放进去


4、pycharm安装selenium


--------------------------------------------------------------------------
注意点:
1、如果安装报错:pip版本太低
解决方案:升级pip直接输入 : python -m pip install --upgrade pip
2、记得配置pip环境变量
3、安装出现pip 安装不是内部命令
解决:安装环境变量的问题,
---------------------------------------------------------------------------------------
1、谷歌驱动:放在C:\python37 下面

对应版本镜像链接1:http://chromedriver.storage.googleapis.com/index.html
对应版本镜像链接2:https://registry.npmmirror.com/binary.html?path=chromedriver/
谷歌下载低版本:https://downzen.com/en/windows/google-chrome/versions/ 不同版本的谷https://googlechromelabs.github.io/chrome-for-testing/#stable 最新版本Google驱动歌

查看谷歌的版本:

因为版本和驱动要对应

将驱动放在python下

注意点:
1、urllib3的版本过高 ,降低版本:1.26.10


2、谷歌和驱动不对应,
3、谷歌会自动更新,关闭自动更新
-------------------------------------------------------------------------------------------
调用语句格式:
第一步:导入 from selenium import webdriver
第二步:创建一个driver对象来打开浏览器,对浏览器实现操作
driver = webdriver.Chrome()
第三步:通过对象谷歌浏览器且输入网址,在用get方法来打开一个网站的url
driver.get('http://gz.duoceshi.cn')

------------------------------------------------------------------------------------------
打开页面方法:
方法一:格式 driver.get( " url")
场景1:driver.get("www.baidu.com")
方法二: 格式:driver.execute_script("window.open('url')")
场景1:driver.execute_script("window.open('http://www.jd.com')")
场景2:和场景1一样的
window='window.open("http://www.jd.com")'#可以通过变量来接收
driver.execute_script(window)#执行脚本
1 2 3 4 5 6 7 8 9 10 | # from selenium import webdriver #导入selenium 模块中webdriver# from time import * #导入时间模块# dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器# dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址# sleep(2) #休眠2秒# # dx.get("https://www.jd.com/")# w="window.open('https://www.jd.com/')" #重开窗口# dx.execute_script(w) #执行重开窗口脚本呢# sleep(10)# dx.close() #关闭当前窗口 |
拓展知识:
window.open()支持环境: JavaScript1.0+/JScript1.0+/Nav2+/IE3+/Opera3+
格式:window.open(pageURL,name,parameters)
pageURL 为子窗口路径 ,name 为子窗口句柄,parameters 为窗口参数(各参数用逗号分隔)
------------------------------------------------------------------------------------------
1、时间等待中的三种
1.1强制等待 sleep(xx) 例如:time.sleep(10)
1.2.隐性等待 implicitly_wait(xx) 例如:driver.implicitly_wait(10)
1.3.显性等待 WebDriverWait
1 2 3 4 5 6 7 | # from selenium import webdriver #导入selenium 模块中webdriver# from time import * #导入时间模块# dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器# dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址# sleep(10) #强制等待# # dx.implicitly_wait(10) #隐性等待# print(1) |
UI自动化测试中的等待方式主要有三种:强制等待、隐性等待和显性等待。下面将分别对这三种等待方式进行详细介绍:
### 1. 强制等待
* **定义**:强制性让代码等待固定的时间,等待时间结束后继续执行下一步操作。
* **实现方式**:通常使用Python的内置time模块提供的`time.sleep()`方法。例如,`time.sleep(5)`表示强制性等待5秒时间。
* **优缺点**:强制等待的缺点是显而易见的,即不管页面元素是否加载完成,都会等待指定的时间,这可能会导致不必要的等待时间,增加程序的执行时间。其优点则是实现简单,不需要额外的条件判断。
### 2. 隐性等待
* **定义**:设置最长的等待时间,等待页面元素加载完成。若在最长等待时间内完成加载,则继续下一步操作;若超过最长等待时间,则跳出等待继续下一步。
* **实现方式**:隐性等待通常使用Selenium库中的`WebDriver`对象的`implicitly_wait()`方法。例如,`driver.implicitly_wait(20)`表示设置隐性等待时间为20秒。
* **优缺点**:隐性等待的优点是设置一次后全局生效,不需要在每个元素等待时都进行设置。此外,当元素加载完成时,会立即继续执行,不会浪费时间。但其缺点是只能用于等待元素的出现,不能用于等待元素的其他状态(如可见、可点击等)。此外,窗口切换的等待不能引用隐性等待。
### 3. 显性等待
* **定义**:在某个已设定的特定条件中,等待指定的时间,并在等待期间不断检查条件是否满足。若条件满足,则跳入下一步操作;若超过最大等待时间,则抛出异常。
* **实现方式**:显性等待通常使用Selenium库中的`WebDriverWait`类。例如,`WebDriverWait(driver, timeout, poll_frequency).until(EC.visibility_of_element_located(locator))`表示等待最长`timeout`时间,每隔`poll_frequency`秒检查一次条件`EC.visibility_of_element_located(locator)`是否满足(即元素是否可见)。
* **优缺点**:显性等待的优点是灵活性强,可以根据需要设置不同的等待条件和等待时间。同时,它还可以等待元素的其他状态(如可见、可点击等),提高了测试的准确性。但其缺点是相对复杂,需要编写更多的代码。
在实际应用中,可以根据测试需求和页面元素加载的特点选择合适的等待方式。例如,对于简单的页面加载,可以使用强制等待或隐性等待;对于复杂的页面交互和元素状态检查,则建议使用显性等待。
2、drivere.refresh( ) 页面刷新
案例:
1 2 3 4 5 | from time import * #导入时间模块dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址sleep(3)dx.refresh() #刷新 |
3、3.1driver.back( ) #返回上一页
1 2 3 4 5 6 7 8 | from selenium import webdriver #导入selenium 模块中webdriverfrom time import * #导入时间模块dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址sleep(3)dx.get("https://www.jd.com/")sleep(3)dx.back() # 返回上一页 |
3.2 driver.forward( )#切换到下一页
1 2 3 4 5 6 7 8 9 10 | from selenium import webdriver #导入selenium 模块中webdriverfrom time import * #导入时间模块dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址sleep(3)dx.get("https://www.jd.com/")sleep(3)dx.back() # 返回上一页sleep(3)dx.forward() #切换到下一页 |
4、driver.set_window_size( 530,960) #设置指定窗口的大小
1 2 3 4 5 6 | from selenium import webdriver #导入selenium 模块中webdriverfrom time import * #导入时间模块dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址sleep(3)dx.set_window_size(500,500) |
5、driver.maxmize_window( ) #窗口最大化
1 2 3 4 5 6 | from selenium import webdriver #导入selenium 模块中webdriverfrom time import * #导入时间模块dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址sleep(3)dx.maximize_window() |
7、driver.get_screenshot_as_file(保存路径,图片名称) 截屏
1 2 3 4 5 6 | from selenium import webdriver #导入selenium 模块中webdriverfrom time import * #导入时间模块dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址sleep(3)dx.get_screenshot_as_file(r"E:\ls\aa.png") |
8、退出的两种方式:一种是close ,另一种:quit
from selenium import webdriver #导入selenium 模块中webdriver
from time import * #导入时间模块
dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器
dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址
sleep(3)
w="window.open('https://www.jd.com/')" #重开窗口
dx.execute_script(w) #执行重开窗口脚本呢
# dx.close() # 关闭当前窗口
dx.quit()
-------------------------------------------------------------------------------------------
定位方法:

讲解实例
查看定位属性:
F12或者开发者工具查看页面元素

场景1:id 定位,比如定位百度的输入框
格式:driver.find_element_by_id('id值')
|
1
2
3
|
from selenium import webdriverdriver=webdriver.Chrome()driver.get("http://www.baidu.com")driver.find_element_by_id('kw') #定位iddriver.find_element_by_id("kw").send_keys("我是name定位") |
场景2:name定位方法,比如百度输入框中找name
格式:driver.find_element_by_name("name值")


from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_name("wd")
time.sleep(3)
driver.find_element_by_name("wd").send_keys("杭州dcs")
场景3:class定位,以百度中class为例
格式:driver.find_element_by_class_name('class值')
|
1
2
3
4
5
|
from selenium import webdriverimport timedriver=webdriver.Chrome()driver.get("http://www.baidu.com")driver.find_element_by_class_name('s_ipt').send_keys("class定位") |
场景4:link_text定位 #使用click()点击方法 准确的匹配 点击a标签
格式:driver.find_element_by_link_text('值').click()
|
1
2
3
4
|
from selenium import webdriverdriver=webdriver.Chrome()driver.get('http://www.baidu.com')driver.find_element_by_link_text('hao123').click() |
场景5:partial_link_text 标签模糊定位
格式:driver.find_element_by_partial_link_text('模糊值').click()
|
1
2
3
4
|
from selenium import webdriverdriver=webdriver.Chrome()driver.get('http://www.baidu.com')driver.find_element_by_partial_link_text('ao').click() |
场景6:javascript 定位
格式:driver.execute_script('document.getElementById("id值").value="输入的值"')
|
1
2
3
4
5
6
|
from selenium import webdriverfrom time import sleepdriver=webdriver.Chrome()driver.get('http://www.baidu.com')js ='document.getElementById("kw").value="js定位方法"'driver.execute_script(js) |
拓展知识:(不讲解)
|
1
2
3
4
5
|
id定位:document.getElementById()name定位:document.getElementsByName()tag定位:document.getElementsByTagName()class定位:document.getElementsByClassName()css定位:document.querySelectorAll() |
场景7:tag_naem定位(标签定位)
格式:drvier.find_elements_by_tag_name('input')
|
1
2
3
4
5
6
7
8
9
|
# from selenium import webdriver# import time# driver=webdriver.Chrome()# driver.get("http://www.baidu.com")inputs =drvier.find_elements_by_tag_name('input')# # 通过elements来找到当前百度中所有的input标签for i in inputs: #遍历input标签 if i.get_attribute('name')=='wd': i.send_keys('多测师name') |
-------------------------------------------------------------------------------------------------------------------
场景8:xpath定位 (详解)
格式:driver.find_element_by_xpath(xpath表达式)
两个定位:
1、绝对定位:
特点:1.以单斜杠/开头;2.从页面根元素(HTML标签)开始,严格按照元素在HTML页面中的位置和顺序向下查找
如:/html/body/div[2]/div[1]/div[5]/div/div/form/span[1]/input
2、相对定位:(我们一般都是用相对定位来定位的)
特点:1.以双斜杠//开头;2.不考虑元素在页面当中的绝对路径和位置;3.只考虑是否存在符合表达式的元素即可。
2.1使用标签名+节点属性定位
语法://标签名[@属性名=属性值]


|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# from selenium import webdriver<br># from time import sleep #导入time模块引用sleep线程等待<br># driver=webdriver.Chrome() #创建一个对象公司用谷歌那么就调用谷歌浏览器<br># url='http://www.baidu.com' # 测试环境地址<br># driver.get(url) #通过谷歌浏览器打开百度网站<br># driver.maximize_window() #窗口最大化<br># sleep(2) #线程等待#直接复制的方法xpath=drvier.find_element_by_xpath('//*[@id="kw"]')xpath.send_keys('直接id复制是xpath')# 直接手写且引用当前标签中已有的元素# 引用:id 除了xpath元素中必须要添加单或者双引号其它都不需要xpath =drvier.find_element_by_xpath('//*[@id="kw"]')xpath.send_keys('直接id复制是xpath')# 通过标签名称来xpath =drvier.find_element_by_xpath('//input[@id="kw"]')xpath.send_keys('通过input标签名')# 通过name元素来实现xpath =drvier.find_element_by_xpath('//*[@name="wd"]')xpath.send_keys('xpath中name定位')# 通过class元素来定位xpath=drvier.find_element_by_xpath('//*[@class="s_ipt"]')xpath.send_keys('xpath中class元素定位!')# 通过:autocomplete="off"元素来定位xpath=drvier.find_element_by_xpath('//*[@autocomplete="off"]')xpath.send_keys('xpath中其他属性定位')# 通过and来实现定位xpath=drvier.find_element_by_xpath('//*[@name="wd" and @class="s_ipt"]')xpath.send_keys('多个组合属性定位xpath') |
1 2 3 | ##from://*[@id="form"]#span://*[@id="form"]/span[1]# //*[@id="kw"] #'''xpath定位的写法'''<br># # 找父级的方法(通过标签找到指定定位的元素)<br># # 当前输入框的标签是:input标签-我要定位的地址在这个地址中输入文本<br># # input标签的上一级是:span标签<br># # 当找父级无法找到的时候:找父级的爷爷级# xpath=driver.find_element_by_xpath('//*[@id="form"]/span/input')<br># xpath.send_keys('根据层级查找定位')<br>#xpath=driver.find_element_by_xpath('//*[@id="form"]/span[1]/a[1]')<br># xpath.send_keys('多测师!!!')<br><br>索引值从1开始, |
----------------------------------------------------------------------------------------------------------------------
场景9:css定位(详解)
格式:driver.find_element_by_css_selector('值')
9.1场景css中使用
from selenium import webdriver from time import sleep #导入time模块引用sleep线程等待 driver=webdriver.Chrome() #创建一个对象公司用谷歌那么就调用谷歌浏览器 url='http://www.baidu.com' # 测试环境地址 driver.get(url) #通过谷歌浏览器打开百度网站 driver.maximize_window() #窗口最大化 sleep(2) #线程等待
from selenium import webdriver #导入selenium 模块中webdriver
from time import * #导入时间模块
dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器
dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址
sleep(3)
dx.maximize_window()
sleep(2)
dx.find_element_by_css_selector("#form>span>input").send_keys("层级定位上两级")
# dx.find_element_by_css_selector("#form > span.bg.s_ipt_wr.new-pmd.quickdelete-wrap>input").send_keys("层级上一级定位")
# dx.find_element_by_css_selector('[name="wd"][class="s_ipt"]').send_keys("css中的组合属性")
# dx.find_element_by_css_selector('[name="wd"]').send_keys("css中的name定位")
# dx.find_element_by_css_selector('[class="s_ipt"]').send_keys("css中的class全称定位")
# dx.find_element_by_css_selector(".s_ipt").send_keys("css中的class简写定位")
# dx.find_element_by_css_selector('[id="kw"]').send_keys("css中的id全称定位")
# dx.find_element_by_css_selector("#kw").send_keys("css中的id简写定位")
总结:
拓展知识:(不讲解)

elements是复数,返回的是一个列表
|
1
2
3
4
5
6
7
8
|
0.id复数定位find_elements_by_id(self, id_)1.name复数定位find_elements_by_name(self, name)2.class复数定位find_elements_by_class_name(self, name)3.tag复数定位find_elements_by_tag_name(self, name)4.link复数定位find_elements_by_link_text(self, text)5.partial_link复数定位find_elements_by_partial_link_text(self, link_text)6.xpath复数定位find_elements_by_xpath(self, xpath)7.css复数定位find_elements_by_css_selector(self, css_selector |
方法一:driver.find_elements("css selector", ".mnav")[5].click()
方法二:driver.find_elements_by_class_name("mnav")[5].click()
注意从索引0开始
----------------------------------------------------------------------------------------------------------------------

|
1
2
3
4
5
6
7
8
9
10
11
|
成功登陆cms案例(输入账号,输入密码,点击登陆)<br>from selenium import webdriverfrom time import sleepdriver=webdriver.Chrome()url="http://cms.duoceshi.cn/cms/manage/login.do"driver.get(url)sleep(3)driver.find_element_by_id("userAccount").send_keys("admin")sleep(3)driver.find_element_by_id("loginPwd").send_keys("123456")sleep(2)driver.find_element_by_id("loginBtn").click() |

案例:
1 2 3 4 5 6 7 8 9 10 | 链接点击<br>from selenium import webdriver<br>from time import sleep<br>dx=webdriver.Chrome()<br>dx.get("http://baidu.com")<br>dx.maximize_window()<br>dx.find_element_by_link_text("hao123").click()<br><br>按钮的点击:from selenium import webdriverfrom time import sleepdx=webdriver.Chrome()dx.get("http://baidu.com")dx.maximize_window()dx.find_element_by_id("kw").send_keys("dcs")sleep(2)dx.find_element_by_id("su").click() # 按钮的点击 |

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
案例1:
from selenium import webdriver 案例2:(非悬停动作)
from selenium import webdriver 案例3:
from selenium import webdriver '''ActionChains()括号中接当前浏览器对象move_to_element()括号中接当前你要模拟悬停的具体元素位置.perform()对当前的位置进行点击悬停(类似于鼠标放在上面的动作)'''sleep(4)<br>driver.find_element_by_link_text('搜索设置').click() |
拓展知识:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
ActionChains类(鼠标操作)常用于模拟鼠标的行为,比如单击、双击、拖拽等行为 click(on_element=None) --- 鼠标单击 double_click(on_element=None) --- 双击 context_click(on_element=None) --- 右击 click_and_hold(on_element=None) --- 鼠标单击并且按住不放 drag_and_drop(source,target) --- 拖拽 drag_and_drop_by_offset(source,xoffset,yoffset) --- 将目标拖动到指定的位置 key_down(value,element=None) --- 按下某个键盘上的键 key_up(value,element=None) --- 松开某个键 move_by_offset(xoffset,yoffset) --- 鼠标从当前位置移动到某个坐标 move_to_element(to_element) --- 鼠标移动到某个元素 move_to_element_with_offset(to_element,xoffset,yoffset) --- 移动到距某个元素(左上角坐标)多少距离的位置 perform() --- 执行链中的所有动作 release(on_element=None) --- 在某个元素位置松开鼠标左 |
1 2 3 4 5 6 7 8 9 10 11 | 获取文本from selenium import webdriverfrom time import sleepdx=webdriver.Chrome()dx.get("http://baidu.com")wb=dx.find_element_by_name("tj_briicon").textprint(wb)if wb=="更多!": print("ok")else: print("no")<br><br>获取当前标题<br>案例1:(覆盖窗口)显示标题# from selenium import webdriver<br># from time import sleep<br># dx=webdriver.Chrome()<br># dx.get("http://baidu.com")<br># print(dx.title) #print(dx.title) #<br># sleep(2)<br># dx.get("http://jd.com")<br># print(dx.title) #京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!案例2:(重开窗口,显示标题,title同一个)from selenium import webdriver<br>from time import sleep<br>dx=webdriver.Chrome()<br>dx.get("http://baidu.com")<br>print(dx.title) #print(dx.title) #<br>sleep(2)<br>w="window.open('https://www.jd.com/')" #重开窗口<br>dx.execute_script(w) #执行重开窗口脚本呢<br>print(dx.title)a=5<br>assert a<1 #assert 错误就直接抛异常,正确就执行下一句语句<br>print("成功")<br><br><br>下拉框定位:<br>案例网址:https://yz.chsi.com.cn/zsml/zyfx_search.jsp 考试网<br>案例:https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/select<br>案例:html <br>file:///E:/dcs/two/selenium/select.html<br>导入一个类:from selenium.webdriver.support.select import Select<br>案例:from selenium import webdriver<br>from selenium.webdriver.support.select import Select<br>dx=webdriver.Chrome()<br>dx.get("https://yz.chsi.com.cn/zsml/zyfx_search.jsp")<br>wz=dx.find_element_by_id("ssdm")<br>Select(wz).select_by_index(2) #通过索引定位,从0开始计算<br># Select(wz).select_by_visible_text("(14)山西省") #通过文本定位<br># Select(wz).select_by_value("15") #通过value值定位 |
作用:判断表达式的条件成不成立,如果不成立就会立刻返回错误,而不用等到程序执行完成崩溃后,<br>其相当于if not 表达式<br><br>assert()方法,断言成功,则程序继续执行,断言失败,则程序报<br>案例一:

弹框的讲解:
1 | alert弹框;<br>file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/alert%E5%BC%B9%E6%A1%86.html<br>案例1: |
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import *
dx=webdriver.Chrome()
dx.get("file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/alert%E5%BC%B9%E6%A1%86.html")
# sleep(2)
tk=dx.switch_to.alert # 切换弹框
tk.dismiss() # 点击取消
sleep(2)
tk.accept() #点击确定
案例2:确认型弹框
file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/enter.html
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import *
dx=webdriver.Chrome()
dx.get("file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/enter.html")
sleep(2)
dx.find_element_by_class_name("alert").click() #点击确认按钮
sleep(2)
tk=dx.switch_to.alert #切换大弹框中
tk.accept()
案例3:输入型弹框
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import *
dx=webdriver.Chrome()
dx.get("file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/prompt.html")
sleep(2)
dx.find_element_by_class_name("alert").click() #点击确认按钮
sleep(2)
tk=dx.switch_to.alert #切换大弹框中
tk.send_keys("dcs")
tk.accept()
案例4:上传文件类型
url="file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/upload_file.html"
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import *
dx=webdriver.Chrome()
dx.get("file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/upload_file.html")
sleep(2)
dx.find_element_by_id("file").send_keys(r"E:\dcs\two\selenium\弹框") #点击确认按钮
案例5:frame框

from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import *
dx=webdriver.Chrome()
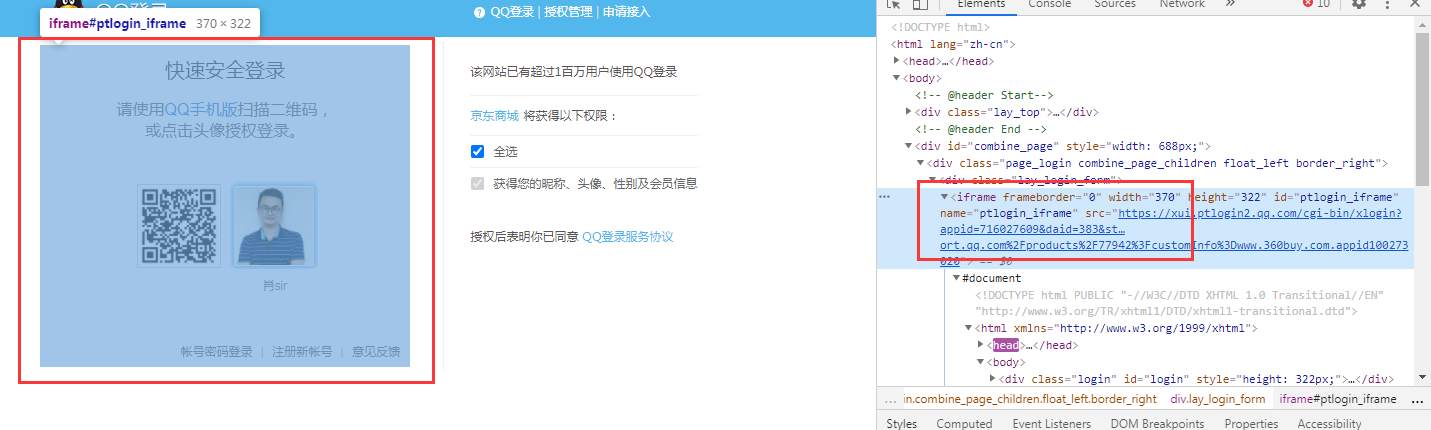
dx.get("https://graph.qq.com/oauth2.0/show?which=Login&display=pc&response_type=code&state=BA37720A1FA67A45EE4FD5112589FA446813433F240AE3CA836176C96D0C3E51F1E922097B5EF30226679AF8197B94F0&client_id=100273020&redirect_uri=https%3A%2F%2Fqq.jd.com%2Fnew%2Fqq%2Fcallback.action%3Fuuid%3Df13bd6404a7044b4af0324d73b026ca7")
sleep(2)
wz=dx.find_element_by_id("ptlogin_iframe")
dx.switch_to.frame(wz)
sleep(2)
dx.find_element_by_link_text("密码登录").click()
sleep(2)
dx.switch_to.default_content()#退框
dx.find_element_by_link_text("服务协议").click()
1 | 表单讲解:<br>案例6:<br>url:file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/table.html<br>案例: |
表单:

selenium import webdriver
from selenium.webdriver.support.select import Select
from time import *
dx=webdriver.Chrome()
dx.get("file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/table.html")
dx.find_element_by_name("user").send_keys("admin")
dx.find_element_by_name("passwd").send_keys("123456")
sleep(2)
dx.find_element_by_name("conpasswd").send_keys("123456")
sleep(2)
dx.find_element_by_xpath("/html/body/form/table/tbody/tr[5]/td[2]/input[1]").click()
sleep(2)
dx.find_element_by_xpath("/html/body/form/table/tbody/tr[6]/td[2]/input[2]").click()
sleep(2)
wz=dx.find_element_by_xpath("/html/body/form/table/tbody/tr[7]/td[2]/select")
Select(wz).select_by_visible_text("北京大学")
sleep(2)
dx.find_element_by_xpath("/html/body/form/table/tbody/tr[8]/th/input[2]").click()

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
场景一:<br>from selenium import webdriverfrom time import sleepdrvier=webdriver.Chrome()drvier.get('http://www.jd.com')drvier.maximize_window()sleep(4)# # 滚动条定位j ='window.scrollTo(0,10000)'# # 0表示为顶端,1000表示从顶端往下滑动的距离# # (距离没有参考自己把握)drvier.execute_script(j)sleep(2)j ='window.scrollTo(0,0)' #返回顶端drvier.execute_script(j)方法2:
from selenium import webdriver 场景二: '''先把上面的滑动语法吸收:<br># 根据我们之前所学的Python 来实现自动增加的滑动<br># 设置一个值为:5000 从0开始依次加1000 当满足5000的时候终止<br>from selenium import webdriver |

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
场景二:模拟键盘操作(from selenium.webdriver.common.keys import Keys #导入Keys类)from selenium import webdriverimport timefrom selenium.webdriver.common.keys import Keys #导入Keys类driver=webdriver.Chrome()url='http://www.baidu.com'driver.get(url)driver.maximize_window()time.sleep(4)# Keys:模拟我们电脑的键盘操作(快捷键,全部选择,剪切,粘贴,空格,回车。。。)driver.find_element_by_id('kw').send_keys('duoceshi')time.sleep(3)# # control+a全部选择driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'a')time.sleep(3)# control+x剪切driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'x')time.sleep(3)# control+v粘贴driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'v')# enter回车driver.find_element_by_id('kw').send_keys(Keys.ENTER)# 把以上的代码进行通过函数来封装from selenium import webdriver |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
'''练习:1、将论坛的登录还有点击模块管理 通过类来进行封装(给实参)2、将论坛的登录还有点击模块管理 用例封装(给形参)且通过类的传递完成调用 加一个断言 '''# from selenium import webdriver# from time import sleep# class Discuz: #定义一个类# def __init__(self):# self.drvier=webdriver.Chrome()# self.drvier.get('http://192.168.254.129/bbs/forum.php')# self.drvier.maximize_window()# self.drvier.implicitly_wait(10)# def login(self,name,pwd): #登录模块# self.drvier.find_element_by_id('ls_username').send_keys(name)# self.drvier.find_element_by_id('ls_password').send_keys(pwd)# sleep(2)# self.drvier.find_element_by_css_selector('.pn').click()# def mk_login(self): #模块管理# self.login('admin','123456')# self.drvier.find_element_by_link_text('模块管理').click()# sleep(2)# title=self.drvier.title# # print(title)# if title=='门户 - Discuz! Board - Powered by Discuz!':# print('模块管理中心OK') #模块管理中心OK# else:# print('NO')# sleep(4)# self.drvier.close()# if __name__ == '__main__':# D=Discuz()# # D.login()# D.mk_login() |
|
1
2
3
|
##from://*[@id="form"]#span://*[@id="form"]/span[1]# //*[@id="kw"] #'''xpath定位的写法'''<br># # 找父级的方法(通过标签找到指定定位的元素)<br># # 当前输入框的标签是:input标签-我要定位的地址在这个地址中输入文本<br># # input标签的上一级是:span标签<br># # 当找父级无法找到的时候:找父级的爷爷级# xpath=driver.find_element_by_xpath('//*[@id="form"]/span/input')<br># xpath.send_keys('根据层级查找定位')<br>#xpath=driver.find_element_by_xpath('//*[@id="form"]/span[1]/a[1]')<br># xpath.send_keys('多测师!!!')<br><br>索引值从1开始, |
1 | 切换窗口<br>1、当出现两个窗口的情况 ,根据索引切换from selenium import webdriver #导入selenium 模块中webdriver<br>from time import * #导入时间模块<br>dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器<br>dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址<br>sleep(2) #休眠2秒<br>print(dx.title) #百度一下,你就知道<br>w="window.open('https://www.jd.com/')" #重开窗口<br>dx.execute_script(w) #执行重开窗口脚本呢<br>print(dx.title) #百度一下,你就知道<br>jb=dx.current_window_handle #获取当前的句柄 #CDwindow-246A6B6A2F463B2A191CAFDAAB53937A<br>print(jb)<br>jbs=dx.window_handles #获取所有句柄<br>print(jbs) #['CDwindow-D076EFACCD6A9182BA3C91A6D18116DB', 'CDwindow-BAE5ACF1978628B382687DDD68DC2351'<br>dx.switch_to.window(jbs[1]) # 索引是0开始,京东索引是1<br>dx.find_element_by_id("key").send_keys("笔记本")2、当出现三个窗口以上的情况 ,根据索引切换 (不是012,多个窗口021)from selenium import webdriver #导入selenium 模块中webdriver<br>from time import * #导入时间模块<br>dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器<br>dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址<br>sleep(2) #休眠2秒<br>print(dx.title) #百度一下,你就知道<br>w="window.open('https://www.hao123.com/')" #重开窗口<br>dx.execute_script(w) #执行重开窗口脚本呢<br>print(dx.title) #百度一下,你就知道<br>w="window.open('https://www.jd.com/')" #重开窗口<br>dx.execute_script(w) #执行重开窗口脚本呢<br>print(dx.title) #百度一下,你就知道<br>jb=dx.current_window_handle #获取当前的句柄 #CDwindow-246A6B6A2F463B2A191CAFDAAB53937A<br>print(jb)<br>jbs=dx.window_handles #获取所有句柄<br>print(jbs)<br>dx.switch_to.window(jbs[1]) # 索引是0开始,京东索引是1<br>dx.find_element_by_id("key").send_keys("笔记本")<br><br>3、多窗口,通过for循环,判断tille 切换窗口from selenium import webdriver #导入selenium 模块中webdriver<br>from time import * #导入时间模块<br>dx=webdriver.Chrome() #创建一个对象来打开浏览器webdriver 接对应的浏览器<br>dx.get("https://www.baidu.com/") #通过父对象中的get方法去打开网址<br>sleep(2) #休眠2秒<br>w="window.open('https://www.hao123.com/')" #重开窗口<br>dx.execute_script(w) #执行重开窗口脚本<br>w="window.open('https://www.jd.com/')" #重开窗口<br>dx.execute_script(w) #执行重开窗口脚本<br>jbs=dx.window_handles #获取所有句柄<br>for i in jbs:<br> dx.switch_to.window(i)<br> if '京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!' in dx.title:<br> break<br>print(dx.title)<br>dx.find_element_by_id("key").send_keys("笔记本") |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!