
模块
randon
随机小数
例子
随机整数
例子:
随机抽取
例子:
打乱顺序:
例子: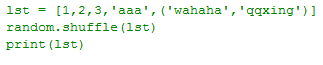
生成4位随机的验证码

生成6位随机的验证码

os模块
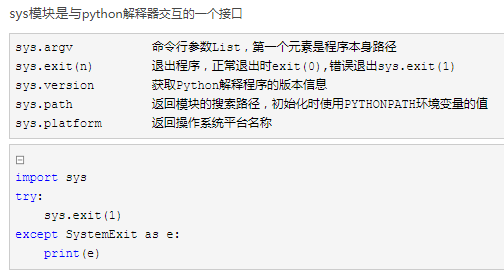
与操作系统交互的一个接口


sys模块
时间模块 time
时间戳时间
例子:print(time.time())
时间字符串
例子: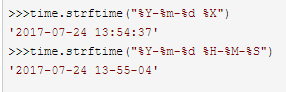
时间元组:localtime将一个时间转换为当前时区的struct_time
例子:
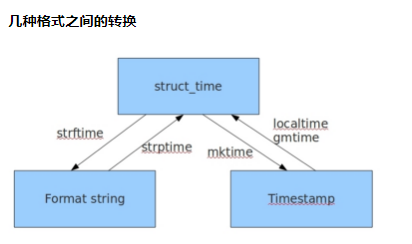
时间戳-->结构化时间
time.gmtime(时间戳) UTC时间,与伦敦当地时间一致
time.localtime(时间戳) 当地时间. 例如我们现在在北京执行这个方法:与UTC时间相差八小时 ==北京时间
例子
结构化时间-->时间戳
time.mktime(结构化时间)
例子 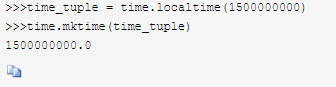
字符串时间-->结构化时间
time.srptime(时间字符串,字符串对应格式)
例子: 
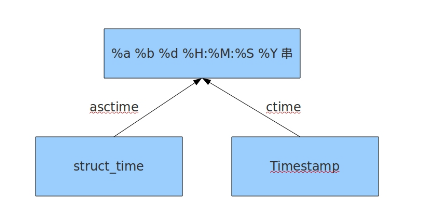
结构化时间 -->%a %b %d %H:%M:%S %Y串
time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
例子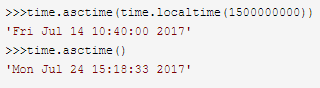
时间戳 -->%a %b %d %H:%M:%S %Y串
time.ctime(时间ch) 如果不传参数,直接返回当前时间的格式化串
例子 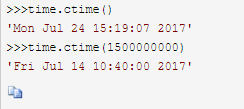
序列化模块
序列化................得到一个字符串的结果过程就叫序列化
字典 / 列表 / 数字 / 对象 -序列化->字符串
字符串 - 反序列化 ->字典 / 列表 / 数字 / 对象
为什么要序列化
1.要把内容写入文件 序列化
2.网络传输数据 序列化
方法
dic = {'k':'v'}
str_dic = str(dic)
print(dict(str_dic))
print([eval(str_dic)])
eval不能随便用
json.............用于字符串和python数据类型间进行转换
json模块提供四个功能 : dumps dump loads load
impore json
loads和dumps
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) #<class'str'>{''k3'':''v3'',''k2'':''v2'',''k1'':''v1''}
#注意: json转换完的字符串类型的字典中的字符串是由" "表示的
dic2 = json.loads(str.dic) #反序列化: 将一个字符串格式的字典转换成一个字典
#注意:要用jaon的loads功能处理的字符串类型的字典中的字符串必须由" "表示
print(type(dic2),dic2) #<class 'dict'>{'k1':'v1','k2':'v2','k3':'v3'}
list_dic = [1,['a','b','c'],3,{'k1':'v1':'k2':'v2'}]
str_dic = json.dumps(list_dic) #也可处理嵌套的数据类型
print(type(str_dic),str_dic) #<class 'list'>[1,["a","b","c"],3,{"k1":"v1","k2":"v2"}]
load和dumo
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法将接收一个句柄,直接将字典转换成json字符串写入文件
f.close()
f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据类型结构返回
f.close()
print(type(dic2)dic2)
ensure_ascii关键字参数
f = open('file','w')
json.dump({'国籍':'中国'},f)
ret = json.dumps({'国籍':'中国'})
f.write(ret+'\n')
json.dump({'国籍':'美国'},f,ensure_ascii=False)
ret = json. dumps({'国籍':'美国'},ensure_ascii=False)
f.write(ret+'\n')
f.close
其他参数说明
data = {'username':['李华','二愣子'],'sex':'male','age':16}
json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False)
print(json_dic2)
json &(与) pickle模块
用于序列化的两个模块
json,用于字符串和python数据类型间进行转换
pickle,用于python特有的类型和python的数据类型间进行转换
pichle模块提供了四个功能:dumps . dump(序列化,存).loads(反序列化,读).load (不仅可以序列化字典,列表...可以吧python中任意的数据类型序列化)
dic = {'k1':'v1','k2':'v2','k3':''v3}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) #字典
shelve
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些
shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似

 浙公网安备 33010602011771号
浙公网安备 33010602011771号