

re模块
1.正则表达式
(1)正则表达式含义...........一种匹配字符串的规则
1来确认一个字符串是否符合规则
2从大段的字符串中找到符合规则的内容
(2)程序领域
1.登录注册页的表单验证
2.爬虫
(3)正则表达式的格式
元字符 字符组[ ]
[1bc]表示的是一个范围
[0-9][A-Z][a-z] 匹配三个字符
[abc0-9] 匹配一个字符
[0-9a-zA-Z]匹配一个字符
\d == [0-9]也表示匹配一个字符,匹配的诗歌数字
\w ==[0-9][A-Z][a-z]表示匹配一个数字字母下划线
\s ==[\n \t]包括回车 空格 和制表符
\n匹配回车
\t匹配制表符
\D匹配非数字
\W匹配非数字字母下划线
\S匹配非空白
[\d\D][\s\S][\w\W]匹配所有
^匹配字符串的开始
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配"海." |
$匹配字符串的结尾
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的"海.$" |
a|b匹配字符a或b,大数在前
()匹配括号内的表达式,也表示一个组
()...............用法()的用法 [1-9]\d{14}(\d{2}[1-9X])? 身份证号
\d+(\.\d+)? 小数或者整数
. 匹配除换行符以外的任意字符
2.量词
?.........在量词的后面跟一个 ? 取消贪婪匹配 非贪婪(惰性)模式
| 李.? | 李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符 |
+ ..........重复一次或更多次
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
* ..........重复零次或更多次
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
{n} {m} {n,m}
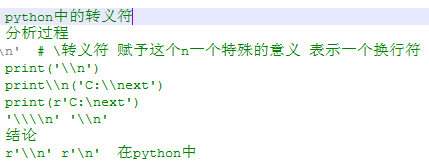
3转义符

4re模块
(1)匹配
1)findall....................参数 返回值类型:列表,返回值个数:1,返回值内容,所有匹配上的项
例子:
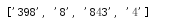
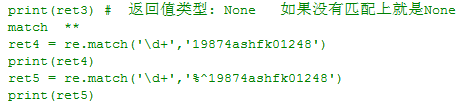
2)search.....................返回值类型 正则匹配结果的对象,返回值:1个,匹配上就返回对象.返回的对象通过group来获取匹配到的第一个结果
例子:
(2)替换 sup

(3)切割 split

split 遇到分组,会保留分组内被切割的内容
(4)进阶方法
1)compile 预编译 节省时间 只有在多次使用某一个相同的正则表达式时候这个compile才会帮助我们提高程序的效率

2)finditer
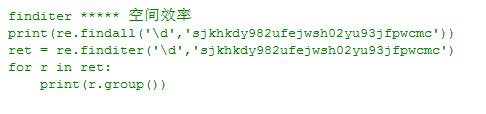
python中的正则表达式
findall 会优先显示分组中的 内容,要想取消分组优先,(?:正则表达式)用的匹配

search 如果search中有分组的话,通过group(n)就能拿到gronp中的匹配内容

分组表达式进阶
分组命名:
(?P<name>正则表达式)表示给分组起名字
(?P=name)表示使用这个分组,这里匹配到的内容应该和分组中的内容完全相等
通过索引使用分组
\1表示使用第一组,匹配到的内容必须和第一个组中的内容完全相同
