Mongodb的锁 原子性 隔离性 一致性
读写锁
Mongodb使用读写锁来来控制并发操作:
当进行读操作的时候会加读锁,这个时候其他读操作可以也获得读锁。但是不能或者写锁。
当进行写操作的时候会加写锁,这个时候不能进行其他的读操作和写操作。
所以按照这个道理,是不会出现同时修改同一个文档(如执行++操作)导致数据出错的情况。
而且按照这个道理,因为写操作会阻塞读操作,所以是不会出现脏读的。
但是mongodb在分片和复制集的时候会产生脏读,后面在研究。
读写锁的粒度:
在2.2之前的版本,一个mongodb实例一个写锁,多个读锁,在2.2-3.0的版本,一个数据库一个写锁,多个读锁,在3.0之后的版本,WiredTiger提供了文档(不是集合)级别的锁。
findAndModify
findAndModify可以保证修改+返回结果(修改前或者修改后都可以)这两个步骤的原子性。
修改并返回单个文档。 默认情况下,返回的文档不包括对更新所做的修改。
db.collection.findAndModify({
query: <document>,
sort: <document>,
remove: <boolean>,
update: <document>,
new: <boolean>,
fields: <document>,
upsert: <boolean>,
bypassDocumentValidation: <boolean>,
writeConcern: <document>,
collation: <document>
});
query:
document。可选的。 使用这个查询来定位需要修改的记录。 虽然查询可能匹配多个文档,但findAndModify()只会选择一个要修改的文档。
sort:
document。可选的。以此参数指定的排序顺序修改第一个文档。
remove:
boolean。标识删除操作。update和remove必须选其一。
update:
document。更新操作。update和remove必须选其一。
new:
boolean。可选的。 当为true时,返回修改后的文档而不是原始文件。删除的时候,设置为true没有意义。
fields:
document。可选的。 要返回的字段的子集。 如:fields: {<field1>: 1, <field2>: 1, ... }
upsert:
boolean。适用于update,当没有query匹配的时候,是否插入。
writeConcern:
参考writeConcern的说明。
update和findAndModify
默认情况下,update()方法更新单个文档。 设置多参数以更新与查询条件匹配的所有文档。
update可以更新多个文档,但是Mongodb只保证单个文档的写入是原子性的。
update()方法返回一个包含操作状态的WriteResult对象。要返回更新的文档,请使用find()方法。但是,其他更新可能已经在更新和文档检索之间修改了文档。此外,如果更新仅修改了单个文档,但是多个文档匹配,则需要使用其他逻辑来标识更新的文档。
findAndModify可能引起的原子性问题:
当findAndModify()包含upsert:true选项,并且查询字段不是唯一索引时,该方法可能会在某些情况下多次插入文档。
如下:
db.people.findAndModify({
query: { name: "Andy" },
sort: { rating: 1 },
update: { $inc: { score: 1 } },
upsert: true
})
当多个客户端同时发出了这个指令,然后在服务端并行执行,而都没有找到query的匹配,可能同时执行了多个upsert操作。导致数据重复。
如果不使用upsert,就没有这种问题。
findAndModify在分片集群中的要求:
在分片环境中使用findAndModify时,查询必须包含分片键。
findAndModify示例:
实例说明了在一个相同的文档中如何确保嵌入字段关联原子操作(update:更新)的字段是同步的。
book = {
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly",
available: 3,
checkout: [ { by: "joe", date: ISODate("2012-10-15") } ]
}
你可以使用 db.collection.findAndModify() 方法来判断书籍是否可结算并更新新的结算信息。
在同一个文档中嵌入的 available 和 checkout 字段来确保这些字段是同步更新的:
db.books.findAndModify ( {
query: {
_id: 123456789,
available: { $gt: 0 }
},
update: {
$inc: { available: -1 },
$push: { checkout: { by: "abc", date: new Date() } }
}
} )
执行多个写入操作
首先,原则上说Mongdb没有事务的概念。
事务有ACID的概念,比如原子性,一个事务要么全部成功,要么全部失败。
如,考虑一个转账的业务,从A转账100到B,将分为两步:
A = A - 100;
B = B + 100;
在Mongdb中,如果A = A - 100;执行完,将会直接入库生效,没有回滚段的概念,所以如果此时B = B + 100;出现了问题,是不能回滚上一步A的操作的。
Mongdb在执行多个更新的时候是没有原子性的。
一个写入操作更新了多个文档:
当单个写入操作修改多个文档时,每个文档的修改是原子的,但整个操作不是原子的,而其他操作可能会交错。 但是,您可以使用$ isolation操作符隔离影响多个文档的单个写入操作。
当Mongodb执行影响多个文档的写入操作的时候,如果在中间某一个文档出现了错误,那么不会回滚之前的提交。之前的提交已经入库了。
MongoDB不隔离多文档写入操作,具有以下特点:
非时间点读操作。其中一假设读取操作在时间t1开始,并开始读取文档。写操作然后在稍后的时间t2向个文档提交更新。读操作可能会看到写操作的更新版本,因此读取操作没有时间点的概念。
读取可能会丢失在读取操作过程中更新的匹配文档。
使用$ isolation来保证隔离性:
使用$isolated操作符可以保证单个写入操作修改多个文档的时候不被交错。
$isolated其实是在整个数据库(Mongodb的手册对这点说明不清楚,也可能是在集合层面加独占锁,但是有一点文档中是说明的,不论在哪个层面加独占锁,都会导致真个数据库单线程化)加独占锁(即使是对于WiredTiger存储引擎也是),在这期间不能进行其他任何的读写操作。所以如果$isolated的操作执行的时间过长,会大大的影响系统的并发性能。
例子:
db.foo.update(
{ status :
"A" , $isolated :
1 },
{ $inc : { count :
1 } },
{ multi:
true }
)
注:上面说的影响不是说可以保证多个文档更新的原子性,$ isolation隔离操作符不为写入操作提供"all-or-nothing"原子性(原子性的定义是要么全部成功,要么全部失败,$isolation不能保证出错回滚)。没有$isolation运算符,多更新将允许其他操作与此更新交错。 如果这些交错操作包含写入,则更新操作可能会产生意外的结果。 通过指定$ isolated,您可以保证整个多重更新的隔离。
总结如下:
- $ isolation不保证多个文档操作的原子性。
- $ isolation保证多个文档操作不会被跟其他操作交错。
- $ isolation保证此操作在进行到某一个文档的更新的时候,在不提交或者回滚之前,不会被客户端看到。也就是说不会导致这个文档的查询产生脏读。(这一段是我的理解 不一定对)
$isolated使用的场景很苛刻。
由于单个文档可以包含多个嵌入文档,单个文档的原子性对于许多实际使用情况是足够的。 对于一系列写入操作必须在单个事务中操作的情况,您可以在应用程序中实现两阶段提交。
但是,两阶段的提交只能提供类似事务的语义。 使用两阶段提交确保数据一致性,但是在两阶段提交或回滚期间,应用程序可以返回中间数据。
副本集中使用readConcern:
在使用副本集的时候,写入操作只写入到master节点,slaver节点从master节点同步数据,所以读操作可能读取到没有同步到其他slaver的数据。
readConcern:读隔离(New in version 3.2.):
readConcern: { level: <"majority"|"local"|"linearizable"> }
readConcern选项可用于以下操作:
- find command
- aggregate command and the db.collection.aggregate() method
- distinct command
- count command
- parallelCollectionScan command
- geoNear command
- geoSearch command
用于副本集和副本集分片的readConcern查询选项确定从查询返回哪些数据。
readConcern级别:
"local":默认。该查询返回实例的最新数据。不保证数据已写入大多数副本集成员(即可以回滚)。
"majority":该查询会将实例的最新数据确认为已写入副本集中的大多数成员。要使用majority级别,您必须使用--enableMajorityReadConcern命令行选项启动mongod实例(如果使用配置文件,则将replication.enableMajorityReadConcern设置为true)。
"linearizable"(add in version3.4):该查询返回反映所有成功写入的数据。
这么说如果配置了linearizable 那么针对一个集合的查询就可以避免脏读了。因为Mongdb没有事务,所以也就不存在幻读和不可重复读的定义了。不过这个功能是在当前最新的3.4版本才有的。
readConcern 解决什么问题?
readConcern 的初衷在于解决『脏读』的问题,比如用户从 MongoDB 的 primary 上读取了某一条数据,但这条数据并没有同步到大多数节点,然后 primary 就故障了,重新恢复后 这个primary 节点会将未同步到大多数节点的数据回滚掉,导致用户读到了『脏数据』。
当指定 readConcern 级别为 majority 时,能保证用户读到的数据『已经写入到大多数节点』,而这样的数据肯定不会发生回滚,避免了脏读的问题(这段话不是来自官方文档,是阿里的一篇文章,这句话我不太认可,即使写入了大部分的节点,也不代表不会回滚,因为可能选举出来新节点正好没有同步这部分数据)。
需要注意的是,readConcern 能保证读到的数据『不会发生回滚』,但并不能保证读到的数据是最新的,这个官网上也有说明:
在使用副本集的时候,无论读取关注级别如何,节点上的最新数据可能不会反映系统中最新版本的数据。
有用户误以为,readConcern 指定为 majority 时,客户端会从大多数的节点读取数据,然后返回最新的数据。
实际上并不是这样,无论何种级别的 readConcern,客户端都只会从『某一个确定的节点』(具体是哪个节点由 readPreference 决定)读取数据,该节点根据自己看到的同步状态视图,只会返回已经同步到大多数节点的数据。
注意事项
- 目前 readConcern 主要用于跟 mongos 与 config server 的交互上,参考MongoDB Sharded Cluster 路由策略
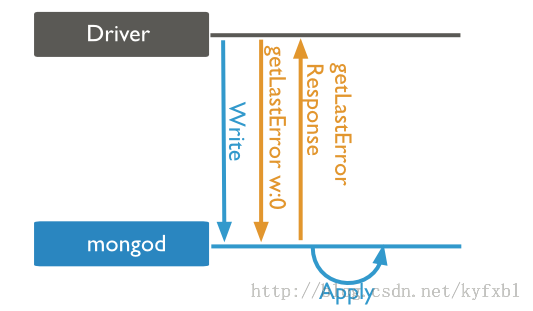
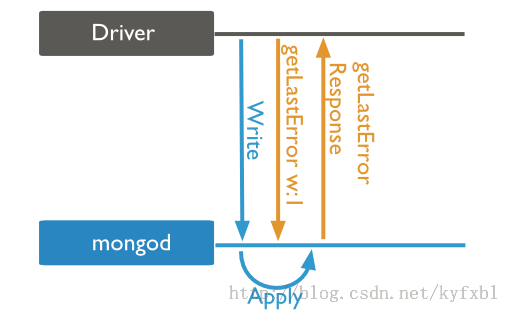
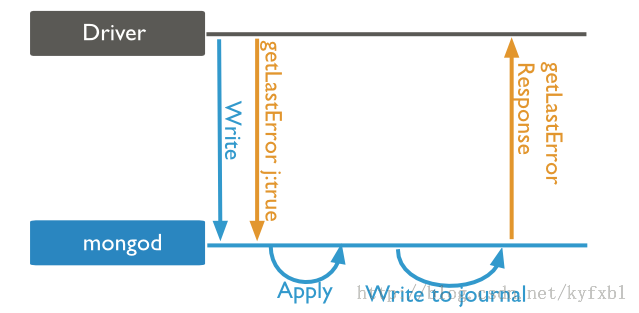
writeConcern:{ w: <value>, j: <boolean>, wtimeout: <number> }
write concern:0(Unacknowledged)
write concern:1 & journal:true(Jounaled)
write concern:2(Replica Acknowledged)
隔离级别:
Read uncommitted是默认隔离级别,适用于mongod独立实例以及复制集和分片集群。
我们上面看到通过读写锁可以保证单个实例不会看到脏读的数据,为什么这里说在单个实例上的隔离级别也是为提交读呢?看看Mongodb官方文档的解释:
单个文档的写入操作是原子的; 即如果写入正在更新文档中的多个字段,则读取器将永远不会看到只更新了一些字段的文档。
然而,虽然度去操作可能看不到部分更新的文档,但读取未提交意味着并发读取可能仍然会看到更新后的文档,但是这些文档还没有持久化。
如果是副本集,那么就不能保证已提交读,因为主节点发生故障后,其他节点接替它作为主节点,接替它的节点可能还没有同步上一个主节点的所有数据,这部分没有同步的数据就成了脏数据。
并行处理的控制
并行处理的控制允许多个应用同时运行而不会造成数据的不一致或者冲突。
一个方法是在字段上创建一个唯一性的索引。这样就可以阻止插入或者更新重复的数据。在多个字段上创建唯一性索引将保证多个字段组合的唯一性。
另外一种方法是通过在写操作中使用查询断言来指定期望的字段当前值。两阶段提交模式除了提供查询断言以外还额外可以指定期望的数据写的状态。
两阶段提交模式
尽管当文档原子操作很强大,但是仍然有需要多文档事务的情况。当执行一个由连续操作组成的事务时,某些问题出现了,比如:
- 原子性:如果一个操作失败,事务内的之前的操作必须 " 回滚 "到之前的状态(就是 "all or nothing" 里面的 "nothing")。
- 一致性:如果一个严重的故障(比如网络或者硬件)打断了事务,数据库必须可以恢复到一致的状态。
对于需要多文档事务的情景,你可以在你的应用里实现两阶段提交以提供这些多文档更新的支持。使用两阶段提交保证数据是一致的,并且在发生错误的情况下,执行事务之前的状态是 recoverable (可恢复的) 。然而,在执行过程中,文档可以展示未确定的(事务提交之前的)数据和状态。
以下例子来自mongodb文档:
概述
假设一个情景,你想从账户 A 转钱到账户 B 。在关系型数据库系统里,你可以在一个多语句事务内从 A账户上减去钱并且为 B 账户添加上钱。在MongoDB里,你可以模仿两阶段提交以达到一个类似的结果。
这个教程里的例子使用下面的两个集合:
- 命名为 accounts 的集合存储账户信息。
- 命名为 transactions 的集合存储有关转账事务的信息。
初始化源账户和目的账户
db.accounts.insert(
[
{ _id: "A", balance: 1000, pendingTransactions: [] },
{ _id: "B", balance: 1000, pendingTransactions: [] }
]
)
初始化转账记录
db.transactions.insert(
{ _id: 1, source: "A", destination: "B", value: 100, state: "initial", lastModified: new Date() }
)
注:我的理解:初始化操作应该是在第一次做事务的时候插入的,为了防止出现重复数据,那么需要在相应的列上加上唯一索引。如,这里应该是source和destination作为唯一索引。而且value不应该出现在transactions表中才对。

检索事务开始:
var t = db.transactions.findOne( { state: "initial" , source: "A", destination: "B"} )
Update transaction state to pending:
db.transactions.update(
{ _id: t._id, state: "initial" },
{
$set: { state: "pending" },
$currentDate: { lastModified: true }
}
)
该操作返回具有操作状态的WriteResult()对象。 成功更新后,n次和nModified显示1。
在更新语句中,状态:"初始"条件确保没有其他进程已更新此记录。 如果nMatched和nModified为0,则返回到第一步以获取其他事务并重新启动该过程。
Apply the transaction to both accounts.
db.accounts.update(
{ _id: t.source, pendingTransactions: { $ne: t._id } },
{ $inc: { balance: -t.value }, $push: { pendingTransactions: t._id } }
)
db.accounts.update(
{ _id: t.destination, pendingTransactions: { $ne: t._id } },
{ $inc: { balance: t.value }, $push: { pendingTransactions: t._id } }
)
Update transaction state to applied
db.transactions.update(
{ _id: t._id, state: "pending" },
{
$set: { state: "applied" },
$currentDate: { lastModified: true }
}
)
remove both accounts' list of pending transactions
db.accounts.update(
{ _id: t.source, pendingTransactions: t._id },
{ $pull: { pendingTransactions: t._id } }
)
db.accounts.update(
{ _id: t.destination, pendingTransactions: t._id },
{ $pull: { pendingTransactions: t._id } }
)
Update transaction state to done.
db.transactions.update(
{ _id: t._id, state: "applied" },
{
$set: { state: "done" },
$currentDate: { lastModified: true }
}
)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号