day 07 字符处理与grep
sort 排序
PS: 将相同的行排序在一起 指定某一列继续排序 默认以第一列进行排序
选项:
-t #指定分隔符 默认分隔符为空白字符
-k #指定以哪一列进行排序
-n #以数值大小进行排序
-r #倒叙排序
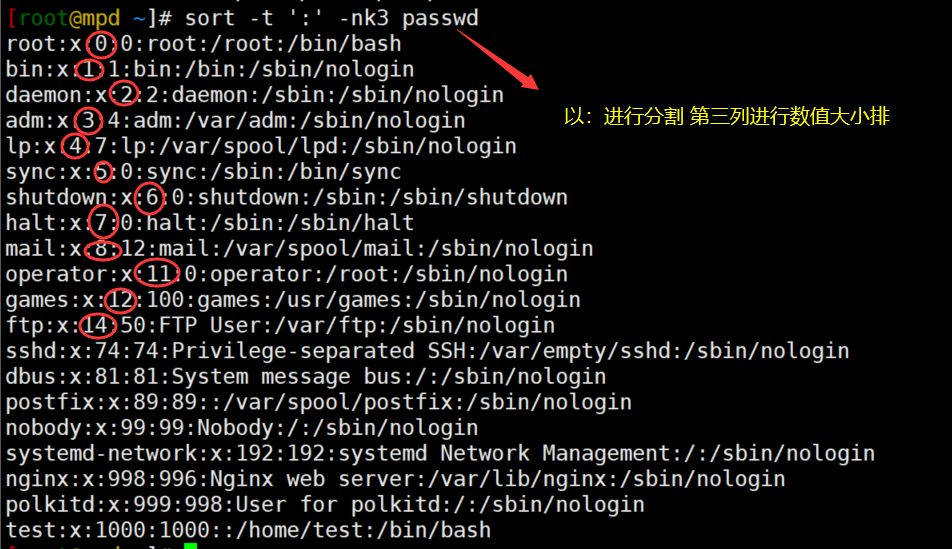
实例: # 以:进行分割 第三列进行数字大写排序
[root@mpd ~]# sort -t ':' -nk3 passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
nginx:x:998:996:Nginx web server:/var/lib/nginx:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
test:x:1000:1000::/home/test:/bin/bash
实例:
uniq 去重 统计
PS:把相邻相同的行进行去重 统计重复的次数
选项:
-c #统计重复的次数
实例:# 把文件相同的行进行排序 默认第一行 让后去重统计每行出现的次数
[root@mpd ~]# cat file.txt
123
abc
123
edf
456
123
abc
[root@mpd ~]# sort file.txt | uniq -c | sort -n
1 456
1 edf
2 abc
3 123
cut 取列
选项:
-d #指定分隔符 默认分隔符为tab键
-f #取出指定的列,取出不连续的列使用逗号分割,取出连续的列使用短横杠进行分割
-c #取出你指定的字符 取出不连续的列使用逗号分割,取出连续的列使用短横杠进行分割 取出的每一行
实例: # 以冒号:分割符取出第6列到第7列的内容
[root@mpd ~]# cut -d ':' -f 6-7 passwd
/root:/bin/bash
/bin:/sbin/nologin
/sbin:/sbin/nologin
/var/adm:/sbin/nologin
/var/spool/lpd:/sbin/nologin
/sbin:/bin/sync
/sbin:/sbin/shutdown
/sbin:/sbin/halt
/var/spool/mail:/sbin/nologin
/root:/sbin/nologin
/usr/games:/sbin/nologin
/var/ftp:/sbin/nologin
/:/sbin/nologin
/:/sbin/nologin
/:/sbin/nologin
/:/sbin/nologin
/var/empty/sshd:/sbin/nologin
/var/spool/postfix:/sbin/nologin
/var/lib/nginx:/sbin/nologin
/home/test:/bin/bash
实例:
tr 替换和删除 只能单对单的进行替换
PS:只能单对单的进行替换 替换或者删除的只是内存中的内容 tr的操作并不会影响源文件
选项:
-d #删除指定的字符
语法:
tr 旧的字符 新的字符 < 文件名
实例: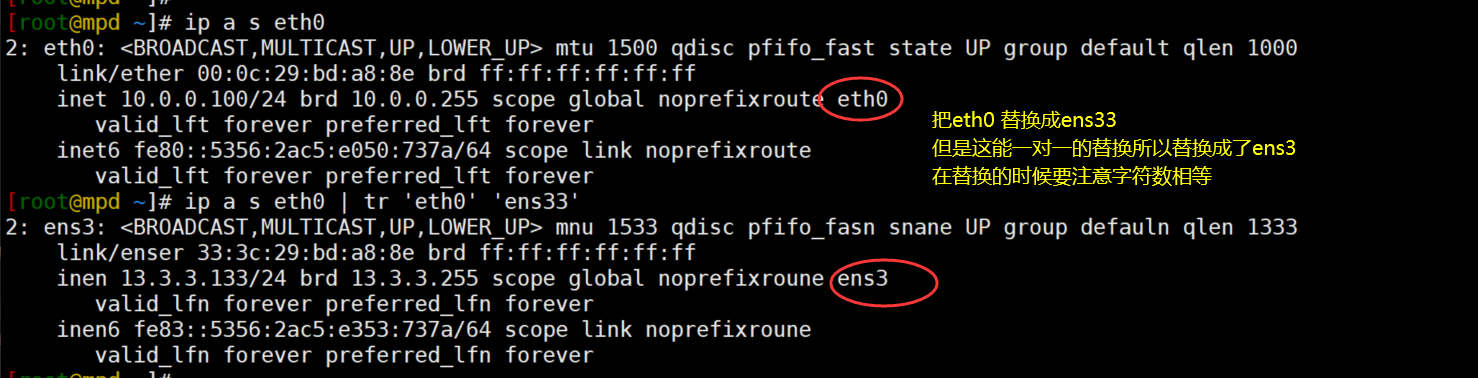
wc 统计
选项:
-l #统计行数
-w #统计列数 默认以空白字符为分隔符
-c #统计字节的大小
-L #统计文件中最长的行的长度 字符的数量
grep 过滤
PS: 给过滤出来的内容加上颜色(--color)
选项:
-n #给过滤出来的内容显示所在文件的行号
-v #排除,取反
-i #过滤的时候,忽略大小写
-c #统计过滤出来的内容的行数
-o #只显示过滤出来的内容
-w #精确匹配,之过滤你要过滤的字符串,而不是包含这个字符串的字符串
-r #递归过滤 针对目录进行操作
-E #支持扩展正则使用
-A #显示过滤出来的内容及向下多少行
-B #显示过滤出来的内容及向上多少行
-C #显示过滤出来的内容向上向下各多少行
-q #静默模式,没有任何输出,得用$?来判断执行成功没有,即有没有过滤 到想要的内容
-l #如果匹配成功,则只将文件名打印出来,失败则不打印
-P #非贪婪修饰符支持.*?
正则符:
^ #以什么为开头
$ #以什么为结尾
| #或者 扩展正则
. #除换行符以外的任意一个字符
* #匹配前面的字符出现0次或者0次以上
.* #所有 包括空行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号