
1.模块初识
getpass就是一个模块(输入时不显示密码)
1 import getpass 2 username = input("username:") 3 password = input("password:") 4 print(username,password)
模块,即库。就是别人写好的功能封装起来成一个名字,我们可以直接下载,导入就可以用,不用重复的造轮子。python一般分为2大库,标准库饿第三方库。
接下来,我们看2个库,sys,os库
我们自己的电脑,有系统的环境变量,而python也有自己的系统环境变量的。sys.path打印的就是python系统的环境。
1 import sys 2 print(sys.path)#打印环境变量
['G:\\python\\start\\ATM\\atm\\conf', 'G:\\python\\start', 'G:\\python\\start\\venv1\\Scripts\\python36.zip', 'G:\\python\\start\\venv1\\DLLs', 'G:\\python\\start\\venv1\\lib', 'G:\\python\\start\\venv1\\Scripts', 'G:\\anaconda\\Lib', 'G:\\anaconda\\DLLs', 'G:\\python\\start\\venv1', 'G:\\python\\start\\venv1\\lib\\site-packages']
注意点:python文件名不能和要导入库名一样(库文件也是一个py文件,也是存在Python的环境系统路径下面)
一样的话,会报错。
一般的标准库都是放在Lib下面的文件夹下面,而需要安装的第三方库都是在site-packages下面。
我们所需要经常使用的库和python自己内部调用的库,至少要存在上面路径之一下面。
导入模块有一个寻找的顺序:当前路径---》python全局的环境变量下面找;
import sys print(sys.argv) print(sys.argv[2])
argv:打印的是本文件的绝对路径。后面可以跟上参数,组成一个list,这样就可以根据参数,做出相应的判断。
import os
cmd_res = os.system("dir")#执行命令,不保存结果
print("------------》",cmd_res)
os:与系统交互的模块
os.system:打印当前文件夹下面的所有的文件,它不会保存结果,它执行就是直接输出到屏幕上面,而mcd_res的结果为0,os.system执行的返回结果为0,代表执行成功。
接下来我们看可以保存结果的:
1 import os 2 cmd_res = os.popen("dir").read() 3 print("------------》",cmd_res)
os.mkdir("new_dir")#创建目录
2.模块初识2
别人有写的第三方模块给我们用,我们自己也可以写第三方模块
username = input("username:") password = input("password:") _user = "alex" _passwd = "abc123" if username == _user and password == _passwd: print("welcome to {user}".format(user=username)) else: print("invaild username or pasword") print(username,password)
下面我们新建一个py文件,导入上面的login文件: import login 执行下面文件即可
但是当你将login文件移走,就会报错:
有2个解决办法:1:将login文件移动到site-packages文件夹下;2.修改Python的环境变量(接下下来会讲解)
3.pyc是什么?
或许大家在学python开始很多人都告诉你,python是一门解释型的语言,是的,我也会一直相信下去,直到我看到了.pyc的文件,这个是什么鬼?c不应该是编译的英文单词的首字母吗?
语言分为2种:
1.解释型语言
2.编译型语言
编译型语言:计算机识别不了我们的高级语言,所以我们要讲高级语言转换为计算机能够识别的机器语言(0101型),就需要中间的翻译器。一种我们用编译器,将高级语言编译成成二进制语言,下次运行时,直接载入已经编译好的文件,这样运行的效率是很快的。
解释型语言:边翻译成机器语言,边执行。边解释一条语句,边执行。
但是现在的语言又不能将语言纯粹的分为:编译型语言和解释型语言。
比如java是基于虚拟机的语言,是一种先编译后解释的语言,当大家用escpli软件运行java代码的时候,没有感觉,因为它是将预编译融合到一起的。但是如果你用命令行,是需要先编译的;java预编译后的结果是介于机器语言的一种字节码的文件,可以理解为半成品吧。同样Python也是先编译后执行的语言。他预编译后的语言也是字节码的文件,里面只完成了15%的工作。当你要运行Python的文件时,你要告诉解释器,嘿,哥们,开始工作了哦,其实在解释器开始工作之前,编译器是预先编译,然后解释器才开始解释。
Python解释器解释代码的时候,是将已经预编译完成的代码存放在内存的PyObjectCode中,解释器从内存中载入PyObjectCode进行解释执行,执行完成之后,Python解释器将PyObjectCode写入pyc的文件中,以便下次快速载入和执行。
Python的数据类型
1.整数
python2里分为整型和长整型
32位与64位有所不同
32位表示的最大的寻址空间为2**32,能够保存的最大的数据为40多个亿的数据
64位表示的最大的寻址空间为2**64,能够保存的最大的数据就太多了,用不完
Python3里都是整型
2.浮点数
浮点数的表示形式跟小数一样,但是浮点数并不是小数
3.布尔数
2个值,真(1),假(0)
数据运算
算术运算符
+:加
-:减
*:乘
%:取余
/:整除,10.0/3.0=3.3333333333.。。。
//:整除取商,10.0//3.0=3.0
比较运算符
==:等于
!=,<>:不等于
>:大于
<:小于
>=:大于等于
<=:小于等于
赋值运算符
=:赋值
+=:a=a+2 等价于 a+=2
-=:a=a-2 等价于 a-=2
/=:a=a/2 等价于 a/=2
*=:a=a*2 等价于 a*=2
%=:a=a%2 等价于 a%=2
//=:a=a//2 等价于 a//=2
**=:a=a**2 等价于 a**=2
逻辑运算符
and:条件都为ture时,结果才为真
or:只要条件有一个为真,结果就为真
not:假为真,真为假
成员运算
in:判断某个值是否在某个列表里面
>>> a=[1,2,3]
>>> 1 in a
True
not in:判断某个值是否不在某个列表里面
>>> a=[1,2,3]
>>> 7 not in a
True
身份运算
is :
>>> a=[1,2,3]
>>> type(a) is list
True
is not :
>>> a=[1,2,3]
>>> type(a) is not list
False
位运算
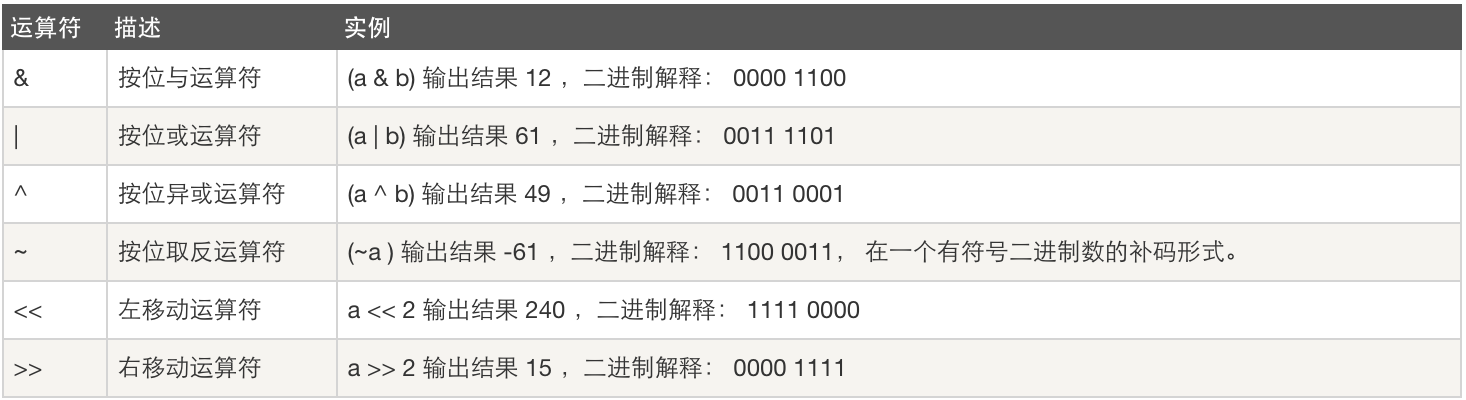
计算机的底层之中能够表示的最小单位就是0,1
计算底层也就是电流,电流就只有2种表示法,1种就是通电,宁外一种就是没有通电,,通电就用1表示,没有通电就有0表示。那么人们的需求又来了,如何用0,1表示跟多的数字呢?
256 128 64 32 16 8 4 2 1
0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1
ASCII表由此的出来
计算机中能够表示的最小的单位是,一个二进制位
计算机中能够存储的最小的单位是,一个二进制位
一个二进制位能够表示一个信息,这个信息肯定能够存储在内存或者硬盘里面
一个二进制位是用1一个bit表示,但是1bit太小了,8位的二进制才能表示255个数据(包括0),所以我们表示数据都是用byte=8bit
所以我们真正去存储或者表示的时候,我们用一个叫byte
8bit=byte(字节)一个英文字符至少用1byte存储
1024=1kbyte
1024kbytes=1mbyte
1024mb=1gb
1024gb=1T
256 128 64 32 16 8 4 2 1
0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1
--------------------------------------------------------------------------------
0 0 1 1 1 1 0 0 =60
-------------------------------------------------------------------------------~
1 1 0 0 0 0 1 1 =195-256=-61
0 0 0 0 1 1 0 1 =13
------------------------------------------------------------------------------^
0 0 1 1 0 0 0 1 =49(相同为0,不同为1)
-------------------------------------------------------------------------------|
0 0 1 1 1 1 0 1 =61
-----------------------------------------------------&
0 0 0 0 1 1 0 0 =12
64>>2=16
64<<2=256
左移和右移,比真正的除法要快的,因为它是二进制的除(左移一位除以2,右移1位乘以2)
bytes的数据类型
python2中的str的数据类型与二进制的字节的数据类型是混用的,二者就是一样的,没有区分。
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。这是件好事。
什么东西使用字节的数据类型存储呢?音视频的文件。
python3中的socket网络编程中,传输的数据类型必须是二进制的byte字节类型,而在python2中str数据类型也可以传输。所以在python3中如果你要从一台机器上将数据传输到宁外一台的机器上时,你就必须转换成二进制的byte的数据类型。
二者是如何转换的呢?

记住上面这个美丽的图片就可以了
str转换为bytes需要encode()(编码)
bytes转换为str需要decode()(解码)
>>> msg='我爱北京天安门'
>>> msg.encode("utf-8")
b'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8'
>>> msg.encode("utf-8").decode('utf-8')
'我爱北京天安门'
二、三元运算
1.result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
三、进制
二进制,01
八进制,01234567
十进制,0123456789
十六进制,0123456789ABCDEF 二进制到16进制转换http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1,
1)16进制的表示方法:
0 1 2 3 4 5 6 7 8 9 A B C D E F
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16进制与二进制的对应关系:
2)每4位的二进制代表一个16进制,为什么是4位呢?因为2进制的4位最大表示15。
再来掌握二进制数与十六进制数之间的对应关系表,如图2所示。只有牢牢掌握的对应关系,在转换的过程中才会事半功倍。
0 1 2 3
0000 0001 0010 0011
4 5 6 7
0100 0101 0110 0111
8 9 A B
1000 1001 1010 1011
C D E F
1100 1101 1110 1111
3)二进制转换成十六进制的方法是,取四合一法,即从二进制的小数点为分界点,向左(或向右)每四位取成一位.
1011 1001 1011.1001
组分好以后,对照二进制与十六进制数的对应表(如下图所示),将四位二进制按权相加,得到的数就是一位十六进制数,然后按顺序排列,小数点的位置不变哦,最后得到的就是十六进制数哦
1011 1001 1011.1001
B 9 B . 9
注意16进制的表示法,用字母H后缀表示,比如BH就表示16进制数11;也可以用0X前缀表示,比如0X23就是16进制的23。
BH H---->是后缀
0X53 0X---->是前缀
4)这里需要注意的是,在向左(或向右)取四位时,取到最高位(最低位)如果无法凑足四位,就可以在小数点的最左边(或最右边)补0,进行换算.
10111.011
0001 0111 . 0110
1 7 6
5)下面看看将16进制转为二进制,反过来啦,方法就是一分四,即一个十六进制数分成四个二进制数,用四位二进制按权相加,最后得到二进制,小数点依旧就可以啦.
B F 4 . B 5
1011 1111 0010 . 1011 0011
每4个二进制表示一个16进制,为什么是每4个呢?因为2**4最大表示到15从0-15,16个数字,所以用4位.
列表的使用
列表可以增删改查
# name = ['alex','Jack','apple']
# 增
# name.append("Guncun")
# name.insert(2,'GodV')
# name2 = [1,2,3]
# name.extend(name2)
# print(name)
# name = ['alex','Jack','apple','Gucun','Godv']
# 删
# name.remove("apple")
# del name[2] 等价于 name.pop(4)
# name.pop()
# print(name)
# name = ['alex','Jack','apple','Gucun','Godv']
# 查
# print(name[0])
# print(name[:])
# print(name[1:3])
# print(name[::2])
# print(name[-3:-1])切片是从左往右数
# name = ['alex','Jack','apple','Gucun','Godv']
# 改
# name[1]='jack'
# print(name)
name = ['alex','Jack','apple','Gucun','Godv']
# name.reverse() //列表反转
# name.sort() //列表按照ASCII表排序
# name.clear() //清除列表中的元素,只剩下空列表
# name.insert(2,"alex")
# print(name.count("alex"))//元素的个数计数
# print(name.index("alex"))//元素的索引查询
# name1 = name.copy()//复制列表里面有坑
# print(name1)
列表的深浅copy
name = ['alex','WuPeiQi','ChenRongHua',['jack','GUN','Aili'],'XieDi','Anple']
name1 = name.copy()
name[2] = "陈华华"
name[3][0] = 'Jack'
print(name)
print(name1)
-----------》结果
['alex', 'WuPeiQi', '陈华华', ['Jack', 'GUN', 'Aili'], 'XieDi', 'Anple']
['alex', 'WuPeiQi', 'ChenRongHua', ['Jack', 'GUN', 'Aili'], 'XieDi', 'Anple']
大家可以发现name1这个列表咋是选择性的修改呢?
其实name.copy只是浅copy,就是将name进行了一次一层的浅复制,而列表里面的列表,只是复制的是它的内存地址,也就是一个内存指针而已,指向的是它真正存储的位置,所以name1里面的小列表和name里面的小列表其实指向的是同一个位置,所以name修改了里面的值,那么name1也就会跟着改变。
有3种浅复制的方法
name1 = name.copy()
name2 = name[:]
name3 = list(name)//工厂函数
要想深复制,完全复制一个列表就用copy模块
import copy
name1 = copy.copy(name)//浅复制
name2 = copy.deepcopy(name)//深复制
字典
补充,上次说在sit-packages里面没有找到sys.py的文件,是因为sys的模块是paython解释器的内置模块,他是用c语言写的,所以你是不会找到一个sys.py的文件的。
浅copy也并不是完全没有用处比如
比如联合账号:
1 import copy 2 name = ['name',['saving',100]] 3 name[0] = 'alex' 4 p1 = copy.copy(name) 5 p2 = copy.copy(name) 6 p1[1][1] = 50 7 print(p1) 8 print(p2)
元组
元组和列表是一样,只是元组有一个特性,元组是不可变的,只要一旦创建就无法改变,只能查看。比如当你在配置数据库的连接时,你就不希望数据库的连接被更改。而且同时当别人看见你的代码的时候,知道元组里面的元素不能被更改的。如果一旦被改也会出错。
元组只有2个方法,count,index。
程序练习
请闭眼写出以下程序。
程序:购物车程序
需求:
启动程序后,让用户输入工资,然后打印商品列表
允许用户根据商品编号购买商品
用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
可随时退出,退出时,打印已购买商品和余额
1 msg = [['Iphone',5800], 2 ['Mac Pro',12000], 3 ['bar coffee',38], 4 ['book',35], 5 ['bike',800]] 6 buy_list = [] 7 salary = input("请输入您的工资:") 8 if salary.isdigit(): 9 salary=int(salary) 10 while True: 11 for i,k in enumerate(msg): 12 print(i+1,k) 13 buy_pro = input("请选择商品号:") 14 if buy_pro.isdigit(): 15 buy_pro = int(buy_pro) 16 if buy_pro > 0 and buy_pro <=len(msg): 17 if msg[buy_pro-1][1] <= salary : 18 salary -= msg[buy_pro-1][1] 19 buy_list.append(msg[buy_pro-1]) 20 else: 21 print("买个毛线,你还有%s钱"%salary) 22 else: 23 print("你输入的不正确") 24 elif buy_pro == 'q': 25 print("----您所购买的商品列表如下--------") 26 print(buy_list) 27 print("你还剩下%s"%salary) 28 break 29 else: 30 print("invaild input") 31 else: 32 print("invaild input")
字符串的使用
1 name = "my name is {name},{year} old" 2 # print(name.capitalize())#首字母改为大写 3 # print(name.center(50,"#"))#50个字符,不够以#填充,将name居中 4 # print(name.count("m"))#计数 5 # print(name.encode())#将str编码成二进制 6 # print(name.expandtabs(tabsize=50))#将字符串里面的\t转换成多少个空格 7 # print(name.endswith("ex"))#判断字符串以什么结尾 8 # print(name.format(name='alex',year='22'))#格式化 9 # print(name.format_map({'name':'alex','year':'22'}))#以字典的形式格式化 10 # print(name.find('name')) 11 # print(name.index("m"))找索引 12 # print('aA12'.isalnum())#判断是不是以纯阿拉伯字母和数字组成 13 # print('Alex li'.istitle())#判断是不是标题,首字母大写 14 # print('ALEX'.isupper())#判断字符串是不是大写 15 # print('alex'.islower())#判断字符串是不是小写 16 # print('1sa'.isidentifier())#判断是不是合法的标识符,即是不是合法的变量名 17 # print('21'.isdecimal())#判断是不是十进制 18 # print('ab1'.isalpha())#判断是不是纯英文字符 19 # print('sds'.isprintable())#判断是不是可以打印的,字符串都是可以打印的,除了Linux上的tty,drive文件不可以打印 20 # print('2121'.isdigit())#判断字符串是不是整数类型 21 # print('12'.isnumeric())#判断字符串是不是纯整数类型 22 # print(' '.isspace())#判断是不是空格 23 # print(''.join(['1','2']))#字符串的拼接 24 # print(name.rjust(50,'-')) 25 # print(name.ljust(50,'-')) 26 # print('ALEX'.lower())#大写变小写 27 # print('alex'.upper())#小写变大写 28 # print('\n alex'.lstrip())#去掉左边的空格和回车 29 # print('alex\n'.rstrip())#去掉右边的空格和回车 30 ''' 31 p = str.maketrans('abcdef','123456') 32 name1 = 'alex li '.translate(p) 33 print(name1) 34 35 ''' 36 print('alex li'.replace('l','L')) 37 print('alex li'.rfind('l')) 38 print('alex li'.split('l'))#字符串分割成列表 39 print('alex li'.startswith("a")) 40 print('alex LI'.swapcase())#大写变小写 小写变大写 41 print('alex \nli'.splitlines())#以换行符分割 42 print('alex li'.title()) 43 print('123'.zfill(50))#左边填充为0
字典的使用
字典是key-value的键值对的数据类型
字典无序,key必须唯一,所以字典天生去重
1 info = { 2 'stu1101': "TengLan Wu", 3 'stu1102': "LongZe Luola", 4 'stu1103': "XiaoZe Maliya", 5 } 6 #增加 7 # info['stu1104'] = 'alex' 8 # print(info) 9 #修改 10 # info['stu1101'] = '武藤兰' 11 # print(info) 12 #del 13 # del info#del功能是python解释器自带的功能,不是列表或者字典特有的 14 # del info['stu1101'] 15 # info.pop('stu1101')#pop必须要有一个参数,与列表不同 16 # info.popitem()#随机删除,感觉没有意义,随机删??? 17 # print(info) 18 # 查 19 # 'stu1101' in info 20 # print(info['stu1101']) 21 ''' 22 print(info['stu1104])#用这个查询字典里面不存在的key的值会报错,但是用下面这个查询就不会 23 print(info.get('stu1104')) 24 ''' 25 # print(info.items())#将字典变成一个列表,里面的元素是key-value的一个元组 26 # print(info.keys())#查询字典里面的key的值 27 # print(info.values())#查询字典里的vaule值 28 29 # info.setdefault('stu1101','alex') 30 # info.setdefault('stu1104','alex')这个方法先去字典里面查找,如果存在,保持原有的不修改,如果不存在,就插入 31 # print(info) 32 33 #update 合并2个列表,交叉的就更新,多的就合并 34 # b = {'stu1101':'alex',2:4,6:8} 35 # info.update(b) 36 # print(info) 37 38 #fromkeys,主要初始化一个字典,但是里面有坑啊,根浅copy一样,第一层还好,但是里面的小字典,就是用的是同一个内存空间 39 # b = info.fromkeys([1,2,3],['jack',{'name':'alex'},123]) 40 # b[1][1]['name'] = 'ALEX' 41 # print(b) 42 43 # for i in info: 44 # print(i) 45 # 下面2种的效果是一样的,但是呢上面比下面效率高 46 # 因为上面的是通过key的索引直接找到对应的值 47 # 下面是需要把字典转换列表再赋值,如果数据小还好,但是上百万条的数据就可以耗时很久 48 # for i in info: 49 # print(i,info[i]) 50 # for i,k in info.items(): 51 # print(i,k)
字典的嵌套
1 av_catalog = { 2 "欧美": { 3 "www.youporn.com": ["很多免费的,世界最大的", "质量一般"], 4 "www.pornhub.com": ["很多免费的,也很大", "质量比yourporn高点"], 5 "letmedothistoyou.com": ["多是自拍,高质量图片很多", "资源不多,更新慢"], 6 "x-art.com": ["质量很高,真的很高", "全部收费,屌比请绕过"] 7 }, 8 "日韩": { 9 "tokyo-hot": ["质量怎样不清楚,个人已经不喜欢日韩范了", "听说是收费的"] 10 }, 11 "大陆": { 12 "1024": ["全部免费,真好,好人一生平安", "服务器在国外,慢"] 13 } 14 } 15 # av_catalog['taiwan']={'www.baidu.com':['真的是笨','可以做镜像啊']} 16 17 print(av_catalog)
