


服务发现与负载均衡机制的实现
服务发现与负载均衡机制的实现
注册中心选型
服务消费者在发起 RPC 调用之前,需要知道服务提供者有哪些节点是可用的,而且服务提供者节点会存在上线和下线的情况。所以服务消费者需要感知服务提供者的节点列表的动态变化,在 RPC 框架中一般采用注册中心来实现服务的注册和发现。
目前主流的注册中心有 ZooKeeper、Eureka、Etcd、Consul、Nacos 等,选择一个高性能、高可用的注册中心对 RPC 框架至关重要。说到高可用自然离不开 CAP 理论,一致性 Consistency、可用性 Availability 和分区容忍性 Partition tolerance 是无法同时满足的,注册中心一般分为 CP 类型注册中心和 AP 类型注册中心。使用最为广泛的 Zookeeper 就是 CP 类型的注册中心,集群中会有一个节点作为 Leader,如果 Leader 节点挂了,会重新进行 Leader 选举,ZooKeeper 保证了所有节点的强一致性,但是在 Leader 选举的过程中是无法对外提供服务的,牺牲了部分可用性。Eureka 是典型的 AP 类型注册中心,在实现服务发现的场景下有很大的优势,整个集群是不存在 Leader、Flower 概念的,如果其中一个节点挂了,请求会立刻转移到其他节点上。可能会存在的问题是如果不同分区无法进行节点通信,那么可能会造成节点之间的数据是有差异的,所以 AP 类型的注册中心通过牺牲强一致性来保证高可用性 。
对于 RPC 框架而言,即使注册中心出现问题,也不应该影响服务的正常调用,所以 AP 类型的注册中心在该场景下相比于 CP 类型的注册中心更有优势。对于成熟的 RPC 框架而言,会提供多种注册中心的选择,接下来我们便设计一个通用的注册中心接口,然后每种注册中心的实现都按该接口规范行扩展。
注册中心接口设计
注册中心主要用于存储服务的元数据信息,首先我们需要将服务元数据信息封装成一个对象,该对象包括服务名称、服务版本、服务地址和服务端口号,如下所示:
@Data public class ServiceMeta { private String serviceName; private String serviceVersion; private String serviceAddr; private int servicePort; }
接下来我们提供一个通用的注册中心接口,该接口主要的操作对象是 ServiceMeta。
public interface RegistryService { void register(ServiceMeta serviceMeta) throws Exception; void unRegister(ServiceMeta serviceMeta) throws Exception; ServiceMeta discovery(String serviceName, int invokerHashCode) throws Exception; void destroy() throws IOException; }
RegistryService 接口包含注册中心四个基本操作:服务注册 register、服务注销 unRegister、服务发现 discovery、注册中心销毁 destroy。下面我们以 ZooKeeper 注册中心实现为例,逐一实现上面四个接口。
注册中心初始化和销毁
Zookeeper 常用的开源客户端工具包有 ZkClient 和 Apache Curator,目前都推荐使用 Apache Curator 客户端。Apache Curator 相比于 ZkClient,不仅提供的功能更加丰富,而且它的抽象层次更高,提供了更加易用的 API 接口以及 Fluent 流式编程风格。在使用 Apache Curator 之前,我们需要在 pom.xml 中引入 Maven 依赖,如下所示:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
<version>2.12.0</version>
</dependency>
需要注意的是,Apache Curator 需要和 Zookeeeper 版本搭配使用,本项目使用的是 Zookeeeper 3.4.14,关于版本兼容性你需要更多关注 Curator 官网(https://curator.apache.org)的版本更新说明。
首先我们需要构建 Zookeeeper 的客户端,使用 Apache Curator 初始化 Zookeeeper 客户端的基于用法大多都与如下代码类似:
public class ZookeeperRegistryService implements RegistryService { public static final int BASE_SLEEP_TIME_MS = 1000; public static final int MAX_RETRIES = 3; public static final String ZK_BASE_PATH = "/mini_rpc"; private final ServiceDiscovery<ServiceMeta> serviceDiscovery; public ZookeeperRegistryService(String registryAddr) throws Exception { CuratorFramework client = CuratorFrameworkFactory.newClient(registryAddr, new ExponentialBackoffRetry(BASE_SLEEP_TIME_MS, MAX_RETRIES)); client.start(); JsonInstanceSerializer<ServiceMeta> serializer = new JsonInstanceSerializer<>(ServiceMeta.class); this.serviceDiscovery = ServiceDiscoveryBuilder.builder(ServiceMeta.class) .client(client) .serializer(serializer) .basePath(ZK_BASE_PATH) .build(); this.serviceDiscovery.start(); } @Override public void unRegister(ServiceMeta serviceMeta) throws Exception { ServiceInstance<ServiceMeta> serviceInstance = ServiceInstance .<ServiceMeta>builder() .name(serviceMeta.getServiceName()) .address(serviceMeta.getServiceAddr()) .port(serviceMeta.getServicePort()) .payload(serviceMeta) .build(); serviceDiscovery.unregisterService(serviceInstance); } }
通过 CuratorFrameworkFactory 采用工厂模式创建 CuratorFramework 实例,构造客户端唯一需你指定的是重试策略,创建完 CuratorFramework 实例之后需要调用 start() 进行启动。然后我们需要创建 ServiceDiscovery 对象,由 ServiceDiscovery 完成服务的注册和发现,在系统退出的时候需要将初始化的实例进行关闭,destroy() 方法实现非常简单,代码如下所示:
@Override public void destroy() throws IOException { serviceDiscovery.close(); }
服务注册实现
初始化得到 ServiceDiscovery 实例之后,我们就可以将服务元数据信息 ServiceMeta 发布到注册中心,register() 方法的代码实现如下所示:
@Override public void register(ServiceMeta serviceMeta) throws Exception { ServiceInstance<ServiceMeta> serviceInstance = ServiceInstance .<ServiceMeta>builder() .name(RpcServiceHelper.buildServiceKey(serviceMeta.getServiceName(), serviceMeta.getServiceVersion())) .address(serviceMeta.getServiceAddr()) .port(serviceMeta.getServicePort()) .payload(serviceMeta) .build(); serviceDiscovery.registerService(serviceInstance); }
ServiceInstance 对象代表一个服务实例,它包含名称 name、唯一标识 id、地址 address、端口 port 以及用户自定义的可选属性 payload,我们有必要了解 ServiceInstance 在 Zookeeper 服务器中的存储形式,如下图所示。
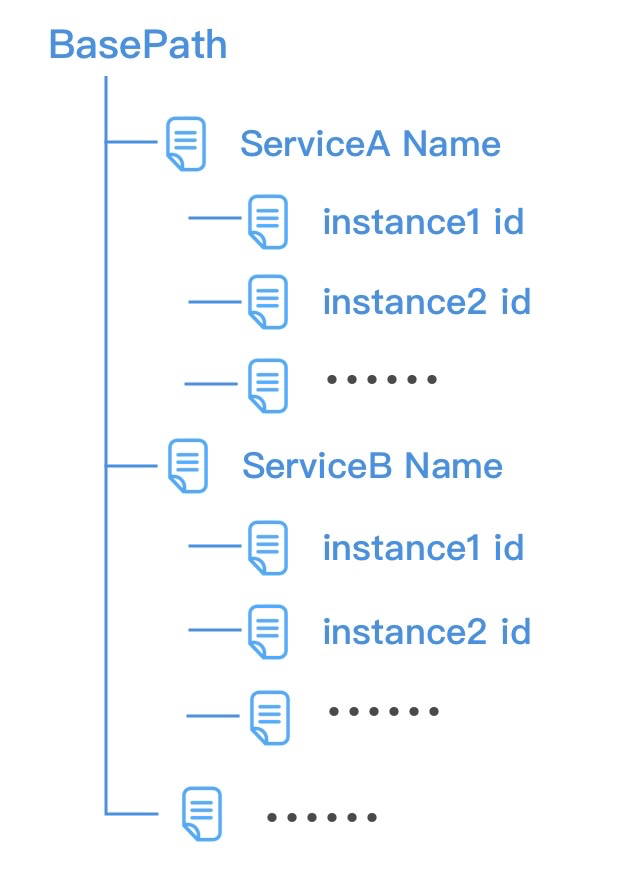
一般来说,我们会将相同版本的 RPC 服务归类在一起,所以可以将 ServiceInstance 的名称 name 根据服务名称和服务版本进行赋值,如下所示。
public class RpcServiceHelper { public static String buildServiceKey(String serviceName, String serviceVersion) { return String.join("#", serviceName, serviceVersion); } }
使用 RegistryService 接口的 register() 方法将识别出的服务进行发布了,完善后的 RpcProvider#postProcessAfterInitialization() 方法实现如下。
@Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { RpcService rpcService = bean.getClass().getAnnotation(RpcService.class); if (rpcService != null) { String serviceName = rpcService.serviceInterface().getName(); String serviceVersion = rpcService.serviceVersion(); try { ServiceMeta serviceMeta = new ServiceMeta(); serviceMeta.setServiceAddr(serverAddress); serviceMeta.setServicePort(serverPort); serviceMeta.setServiceName(serviceName); serviceMeta.setServiceVersion(serviceVersion); serviceRegistry.register(serviceMeta); rpcServiceMap.put(RpcServiceHelper.buildServiceKey(serviceMeta.getServiceName(), serviceMeta.getServiceVersion()), bean); } catch (Exception e) { log.error("failed to register service {}#{}", serviceName, serviceVersion, e); } } return bean; }
至此,服务提供者在启动后就可以将 @RpcService 注解修饰的服务发布到注册中心了。
负载均衡算法基础
服务消费者在发起 RPC 调用之前,需要感知有多少服务端节点可用,然后从中选取一个进行调用。之前我们提到了几种常用的负载均衡策略:Round-Robin 轮询、Weighted Round-Robin 权重轮询、Least Connections 最少连接数、Consistent Hash 一致性 Hash 等。本节课我们讨论的主角是基于一致性 Hash 的负载均衡算法,一致性 Hash 算法可以保证每个服务节点分摊的流量尽可能均匀,而且能够把服务节点扩缩容带来的影响降到最低。下面我们一起看下一致性 Hash 算法的设计思路。
在服务端节点扩缩容时,一致性 Hash 算法会尽可能保证客户端发起的 RPC 调用还是固定分配到相同的服务节点上。一致性 Hash 算法是采用哈希环来实现的,通过 Hash 函数将对象和服务器节点放置在哈希环上,一般来说服务器可以选择 IP + Port 进行 Hash,如下图所示。
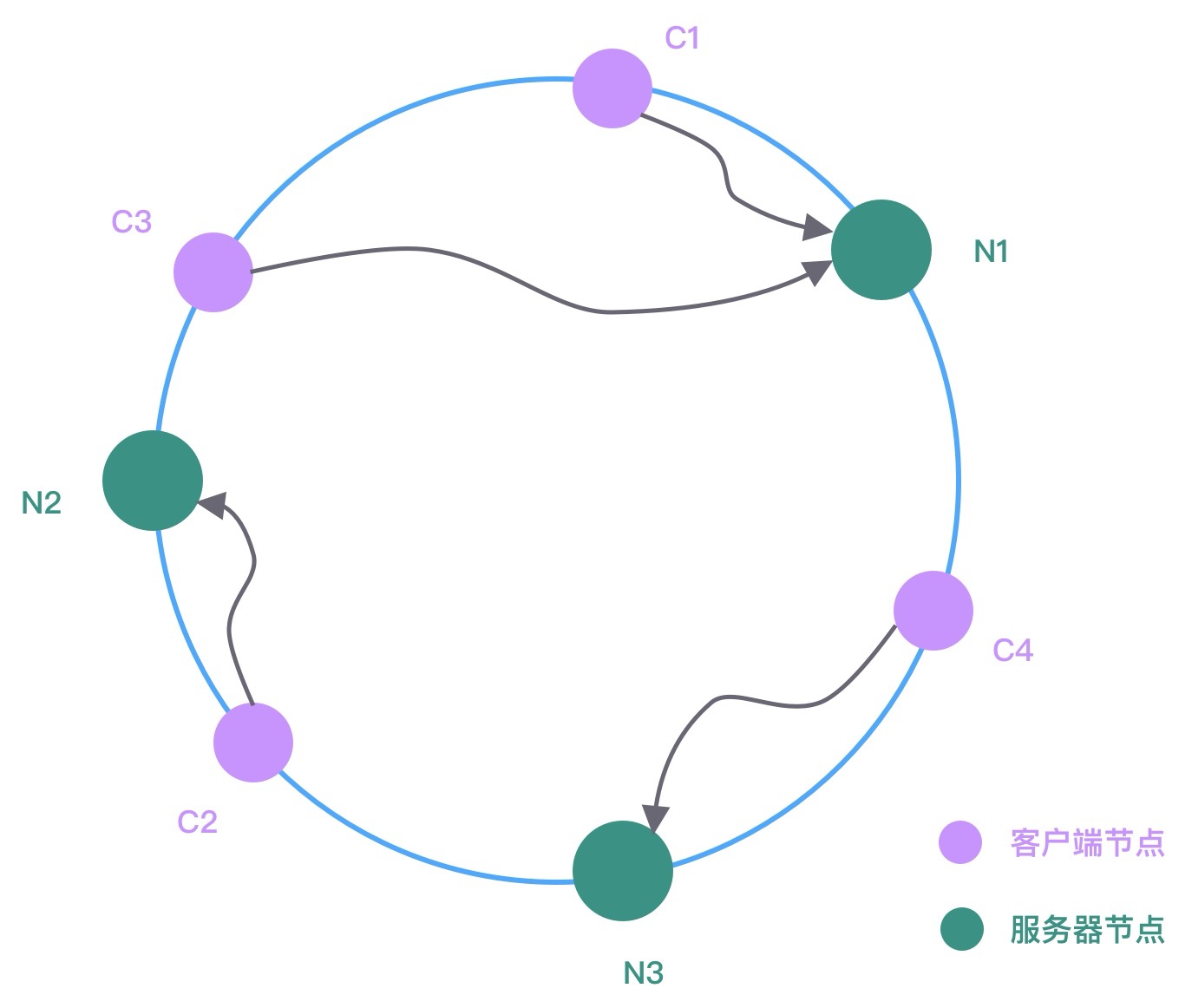
图中 C1、C2、C3、C4 是客户端对象,N1、N2、N3 为服务节点,然后在哈希环中顺时针查找距离客户端对象 Hash 值最近的服务节点,即为客户端对应要调用的服务节点。假设现在服务节点扩容了一台 N4,经过 Hash 函数计算将其放入到哈希环中,哈希环变化如下图所示。
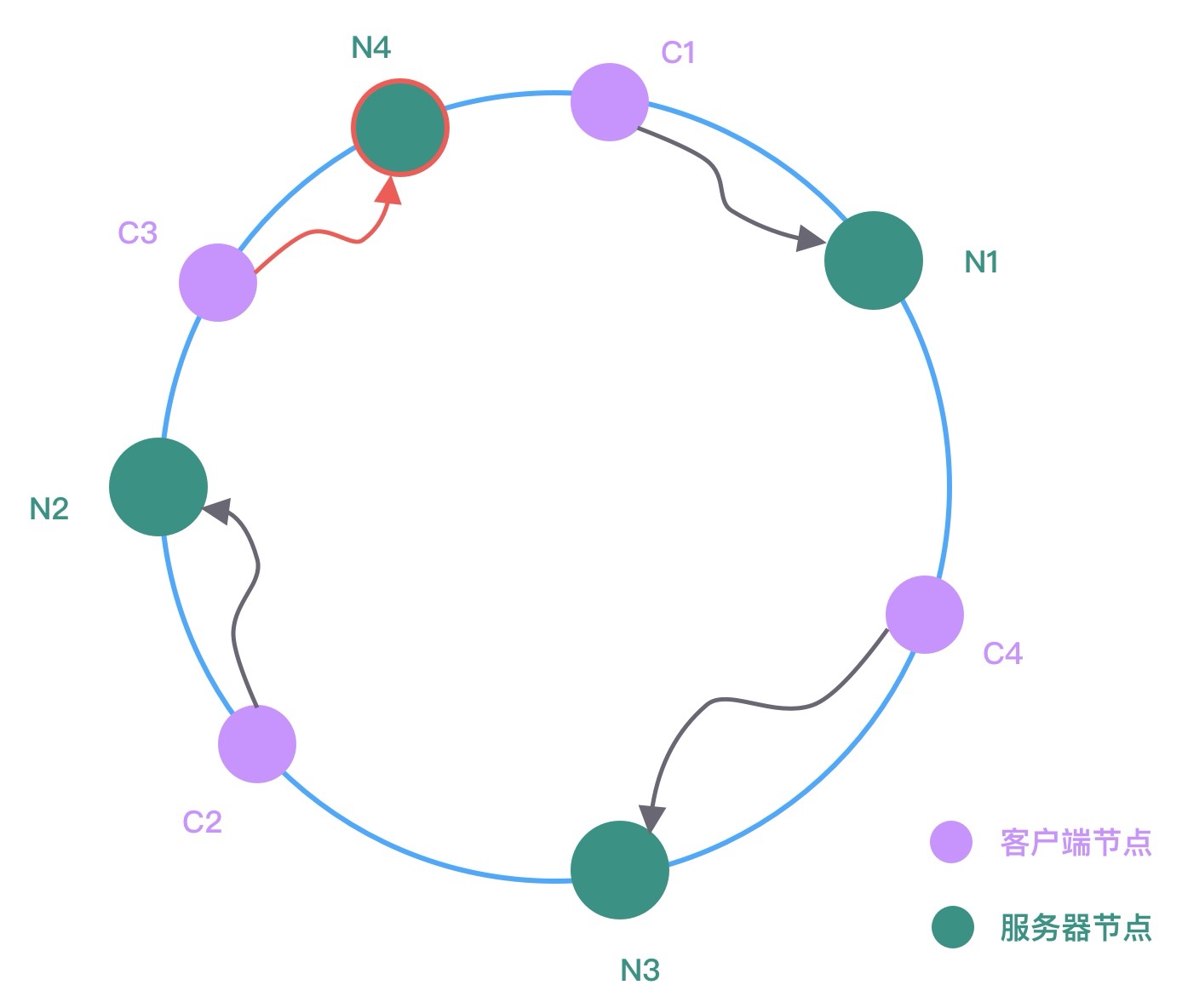
此时 N2 和 N4 之间的客户端对象需要重新进行分配,可以看出只有 C3 会被分配到新的节点 N4 上,其他的都保持不变。服务节点下线与上线的处理过程是类似的,你可以自行分析下服务节点下线时哈希环是如何变化的。
如果服务节点的数量很少,不管 Hash 算法如何,很大可能存在服务节点负载不均的现象。而且上图中在新增服务节点 N4 时,仅仅分担了 N1 节点的流量,其他节点并没有流量变化。为了解决上述问题,一致性 Hash 算法一般会引入虚拟节点的概念。如下图所示。
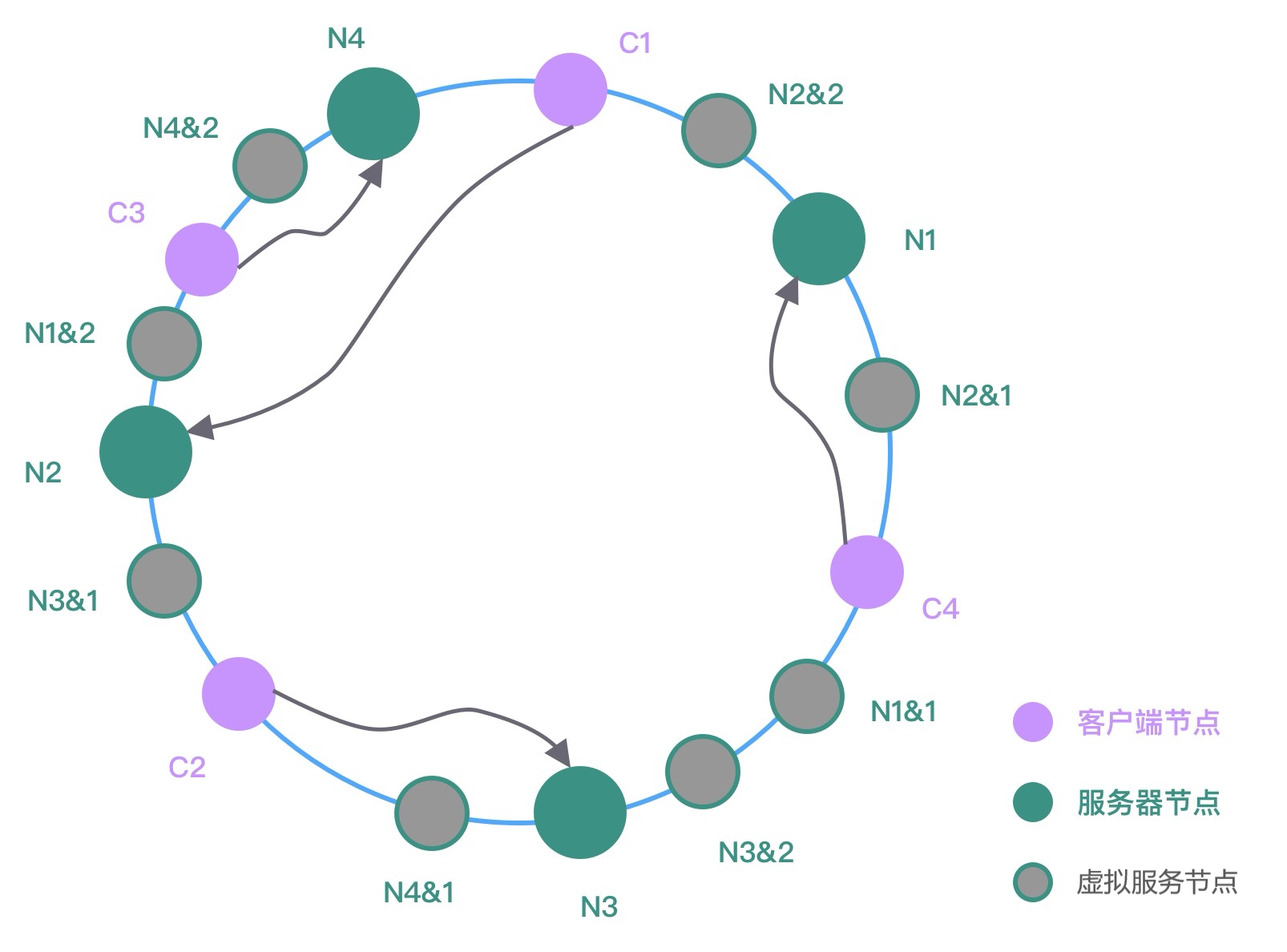
图中相同颜色表示同一组虚拟服务器,它们经过 Hash 函数计算后被均匀放置在哈希环中。如果真实的服务节点越多,那么所需的虚拟节点就越少。在为客户端对象分配节点的时候,需要顺时针从哈希环中找到距离最近的虚拟节点,然后即可确定真实的服务节点。
负载均衡算法实现
与注册中心类似,我们也首先定义一个通用的负载均衡接口,Round-Robin 轮询、一致性 Hash 等负载均衡算法都需要实现该接口,接口的定义如下所示:
public interface ServiceLoadBalancer<T> { T select(List<T> servers, int hashCode); }
select() 方法的传入参数是一批服务节点以及客户端对象的 hashCode,针对 Zookeeper 的场景,我们可以实现一个比较通用的一致性 Hash 算法。
public class ZKConsistentHashLoadBalancer implements ServiceLoadBalancer<ServiceInstance<ServiceMeta>> { private final static int VIRTUAL_NODE_SIZE = 10; private final static String VIRTUAL_NODE_SPLIT = "#"; @Override public ServiceInstance<ServiceMeta> select(List<ServiceInstance<ServiceMeta>> servers, int hashCode) { TreeMap<Integer, ServiceInstance<ServiceMeta>> ring = makeConsistentHashRing(servers);// 构造哈希环 return allocateNode(ring, hashCode);// 根据 hashCode 分配节点 } private ServiceInstance<ServiceMeta> allocateNode(TreeMap<Integer, ServiceInstance<ServiceMeta>> ring, int hashCode) { Map.Entry<Integer, ServiceInstance<ServiceMeta>> entry = ring.ceilingEntry(hashCode);// 顺时针找到第一个节点 if (entry == null) { entry = ring.firstEntry();// 如果没有大于 hashCode 的节点,直接取第一个 } return entry.getValue(); } private TreeMap<Integer, ServiceInstance<ServiceMeta>> makeConsistentHashRing(List<ServiceInstance<ServiceMeta>> servers) { TreeMap<Integer, ServiceInstance<ServiceMeta>> ring = new TreeMap<>(); for (ServiceInstance<ServiceMeta> instance : servers) { for (int i = 0; i < VIRTUAL_NODE_SIZE; i++) { ring.put((buildServiceInstanceKey(instance) + VIRTUAL_NODE_SPLIT + i).hashCode(), instance); } } return ring; } private String buildServiceInstanceKey(ServiceInstance<ServiceMeta> instance) { ServiceMeta payload = instance.getPayload(); return String.join(":", payload.getServiceAddr(), String.valueOf(payload.getServicePort())); } }
JDK 提供了 TreeMap 数据结构,可以非常方便地构造哈希环。通过计算出每个服务实例 ServiceInstance 的地址和端口对应的 hashCode,然后直接放入 TreeMap 中,TreeMap 会对 hashCode 默认从小到大进行排序。在为客户端对象分配节点时,通过 TreeMap 的 ceilingEntry() 方法找出大于或等于客户端 hashCode 的第一个节点,即为客户端对应要调用的服务节点。如果没有找到大于或等于客户端 hashCode 的节点,那么直接去 TreeMap 中的第一个节点即可。
至此,一个基本的一致性 Hash 算法已经实现完了。
服务发现实现
服务发现的实现思路比较简单,首先找出被调用服务所有的节点列表,然后通过 ZKConsistentHashLoadBalancer 提供的一致性 Hash 算法找出相应的服务节点。具体代码实现如下:
@Override public ServiceMeta discovery(String serviceName, int invokerHashCode) throws Exception { Collection<ServiceInstance<ServiceMeta>> serviceInstances = serviceDiscovery.queryForInstances(serviceName); ServiceInstance<ServiceMeta> instance = new ZKConsistentHashLoadBalancer().select((List<ServiceInstance<ServiceMeta>>) serviceInstances, invokerHashCode); if (instance != null) { return instance.getPayload(); } return null; }
服务消费者通过动态代理发起 RPC 调用之前,需要通过服务发现接口获取到可调用的节点。
动态代理
动态代理基础
为什么需要代理模式呢?代理模式的优势是可以很好地遵循设计模式中的开放封闭原则,对扩展开发,对修改关闭。你不需要关注目标类的实现细节,通过代理模式可以在不修改目标类的情况下,增强目标类功能的行为。Spring AOP 是 Java 动态代理机制的经典运用,我们在项目开发中经常使用 AOP 技术完成一些切面服务,如耗时监控、事务管理、权限校验等,所有操作都是通过切面扩展实现的,不需要对源代码有所侵入。
动态代理是一种代理模式,它提供了一种能够在运行时动态构建代理类以及动态调用目标方法的机制。为什么称为动态是因为代理类和被代理对象的关系是在运行时决定的,代理类可以看作是对被代理对象的包装,对目标方法的调用是通过代理类来完成的。所以通过代理模式可以有效地将服务提供者和服务消费者进行解耦,隐藏了 RPC 调用的具体细节,如下图所示。
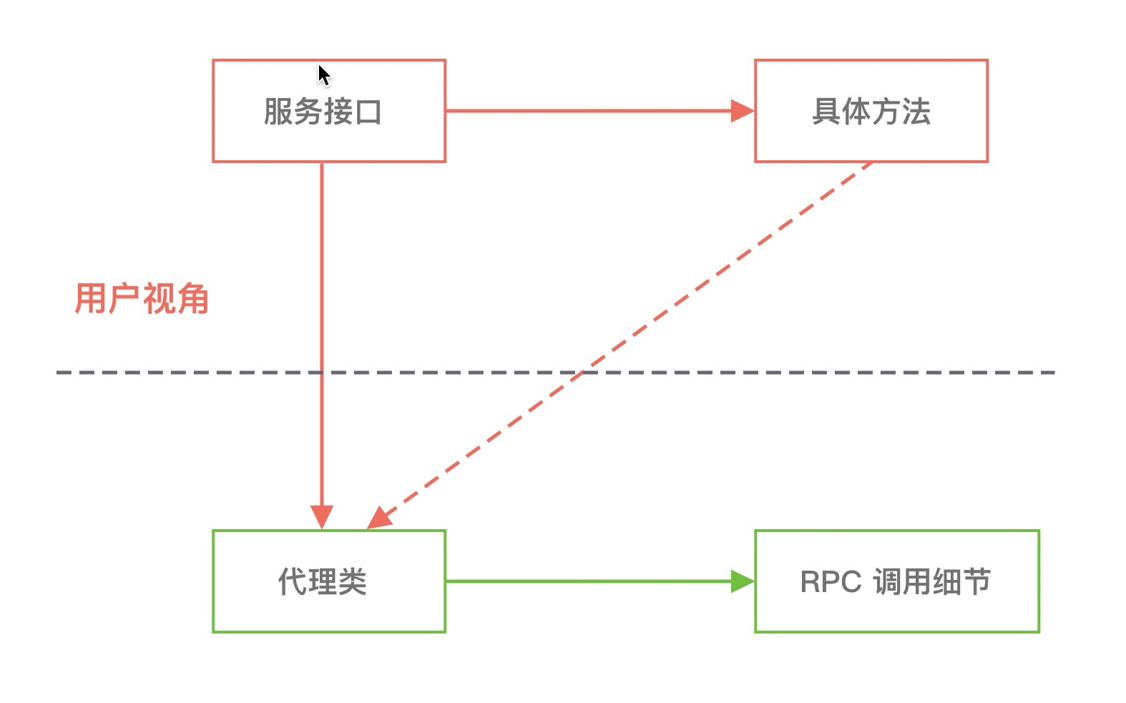
JDK 动态代理
JDK 动态代理实现依赖 java.lang.reflect 包中的两个核心类:InvocationHandler 接口和Proxy 类。
- InvocationHandler 接口
JDK 动态代理所代理的对象必须实现一个或者多个接口,生成的代理类也是接口的实现类,然后通过 JDK 动态代理是通过反射调用的方式代理类中的方法,不能代理接口中不存在的方法。每一个动态代理对象必须提供 InvocationHandler 接口的实现类,InvocationHandler 接口中只有一个 invoke() 方法。当我们使用代理对象调用某个方法的时候,最终都会被转发到 invoke() 方法执行具体的逻辑。invoke() 方法的定义如下:
public interface InvocationHandler { public Object invoke(Object proxy, Method method, Object[] args) throws Throwable; }
其中 proxy 参数表示需要代理的对象,method 参数表示代理对象被调用的方法,args 参数为被调用方法所需的参数。
- Proxy 类
Proxy 类可以理解为动态创建代理类的工厂类,它提供了一组静态方法和接口用于动态生成对象和代理类。通常我们只需要使用 newProxyInstance() 方法,方法定义如下所示。
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) { Objects.requireNonNull(h); Class<?> caller = System.getSecurityManager() == null ? null : Reflection.getCallerClass(); Constructor<?> cons = getProxyConstructor(caller, loader, interfaces); return newProxyInstance(caller, cons, h); }
其中 loader 参数表示需要装载的类加载器 ClassLoader,interfaces 参数表示代理类实现的接口列表,然后你还需要提供一个 InvocationHandler 接口类型的处理器,所有动态代理类的方法调用都会交由该处理器进行处理,这是动态代理的核心所在。
Cglib 动态代理
Cglib 动态代理是基于 ASM 字节码生成框架实现的第三方工具类库,相比于 JDK 动态代理,Cglib 动态代理更加灵活,它是通过字节码技术生成的代理类,所以代理类的类型是不受限制的。使用 Cglib 代理的目标类无须实现任何接口,可以做到对目标类零侵入。
Cglib 动态代理是对指定类以字节码的方式生成一个子类,并重写其中的方法,以此来实现动态代理。因为 Cglib 动态代理创建的是目标类的子类,所以目标类必须要有无参构造函数,而且目标类不要用 final 进行修饰。
在我们使用 Cglib 动态代理之前,需要引入相关的 Maven 依赖,如下所示。如果你的项目中已经引入了 spring-core 的依赖,则已经包含了 Cglib 的相关依赖,无须再次引入。
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
Cglib 动态代理的实现需要依赖两个核心组件:MethodInterceptor 接口和 Enhancer 类,类似于 JDK 动态代理中的InvocationHandler 接口和Proxy 类。
- MethodInterceptor 接口
MethodInterceptor 接口只有 intercept() 一个方法,所有被代理类的方法执行最终都会转移到 intercept() 方法中进行行为增强,真实方法的执行逻辑则通过 Method 或者 MethodProxy 对象进行调用。
- Enhancer 类
Enhancer 类是 Cglib 中的一个字节码增强器,它为我们对代理类进行扩展时提供了极大的便利。Enhancer 类的本质是在运行时动态为代理类生成一个子类,并且拦截代理类中的所有方法。我们可以通过 Enhancer 设置 Callback 接口对代理类方法执行的前后执行一些自定义行为,其中 MethodInterceptor 接口是我们最常用的 Callback 操作。
服务消费者动态代理实现
之前讲解了 @RpcReference 注解的实现过程。通过一个自定义的 RpcReferenceBean 完成了所有执行方法的拦截,RpcReferenceBean 中 init() 方法就是代理对象的创建入口,代理对象创建如下所示。
public void init() throws Exception { RegistryService registryService = RegistryFactory.getInstance(this.registryAddr, RegistryType.valueOf(this.registryType)); this.object = Proxy.newProxyInstance( interfaceClass.getClassLoader(), new Class<?>[]{interfaceClass}, new RpcInvokerProxy(serviceVersion, timeout, registryService)); }
RpcInvokerProxy 处理器是实现动态代理逻辑的核心所在,其中包含 RPC 调用时底层网络通信、服务发现、负载均衡等具体细节,我们详细看下如何实现 RpcInvokerProxy 处理器,代码如下所示:
@Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 构造 RPC 协议对象 MiniRpcProtocol<MiniRpcRequest> protocol = new MiniRpcProtocol<>(); MsgHeader header = new MsgHeader(); long requestId = MiniRpcRequestHolder.REQUEST_ID_GEN.incrementAndGet(); header.setMagic(ProtocolConstants.MAGIC); header.setVersion(ProtocolConstants.VERSION); header.setRequestId(requestId); header.setSerialization((byte) SerializationTypeEnum.HESSIAN.getType()); header.setMsgType((byte) MsgType.REQUEST.getType()); header.setStatus((byte) 0x1); protocol.setHeader(header); MiniRpcRequest request = new MiniRpcRequest(); request.setServiceVersion(this.serviceVersion); request.setClassName(method.getDeclaringClass().getName()); request.setMethodName(method.getName()); request.setParameterTypes(method.getParameterTypes()); request.setParams(args); protocol.setBody(request); RpcConsumer rpcConsumer = new RpcConsumer(); MiniRpcFuture<MiniRpcResponse> future = new MiniRpcFuture<>(new DefaultPromise<>(new DefaultEventLoop()), timeout); MiniRpcRequestHolder.REQUEST_MAP.put(requestId, future); // 发起 RPC 远程调用 rpcConsumer.sendRequest(protocol, this.registryService); // TODO hold request by ThreadLocal // 等待 RPC 调用执行结果 return future.getPromise().get(future.getTimeout(), TimeUnit.MILLISECONDS).getData(); }
RpcInvokerProxy 处理器必须要实现 InvocationHandler 接口的 invoke() 方法,被代理的 RPC 接口在执行方法调用时,都会转发到 invoke() 方法上。invoke() 方法的核心流程主要分为三步:构造 RPC 协议对象、发起 RPC 远程调用、等待 RPC 调用执行结果。
RPC 协议对象的构建,只要根据用户配置的接口参数对 MiniRpcProtocol 类的属性依次赋值即可。构建完MiniRpcProtocol 协议对象后,就可以对远端服务节点发起 RPC 调用了,所以 sendRequest() 方法是我们需要重点实现的内容。
public void sendRequest(MiniRpcProtocol<MiniRpcRequest> protocol, RegistryService registryService) throws Exception { MiniRpcRequest request = protocol.getBody(); Object[] params = request.getParams(); String serviceKey = RpcServiceHelper.buildServiceKey(request.getClassName(), request.getServiceVersion()); int invokerHashCode = params.length > 0 ? params[0].hashCode() : serviceKey.hashCode(); ServiceMeta serviceMetadata = registryService.discovery(serviceKey, invokerHashCode); if (serviceMetadata != null) { ChannelFuture future = bootstrap.connect(serviceMetadata.getServiceAddr(), serviceMetadata.getServicePort()).sync(); future.addListener((ChannelFutureListener) arg0 -> { if (future.isSuccess()) { log.info("connect rpc server {} on port {} success.", serviceMetadata.getServiceAddr(), serviceMetadata.getServicePort()); } else { log.error("connect rpc server {} on port {} failed.", serviceMetadata.getServiceAddr(), serviceMetadata.getServicePort()); future.cause().printStackTrace(); eventLoopGroup.shutdownGracefully(); } }); future.channel().writeAndFlush(protocol); } }
发起 RPC 调用之前,我们需要找到最合适的服务节点,直接调用注册中心服务 RegistryService 的 discovery() 方法即可,默认是采用一致性 Hash 算法实现的服务发现。这里有一个小技巧,为了尽可能使所有服务节点收到的请求流量更加均匀,需要为 discovery() 提供一个 invokerHashCode,一般可以采用 RPC 服务接口参数列表中第一个参数的 hashCode 作为参考依据。找到服务节点地址后,接下来通过 Netty 建立 TCP 连接,然后调用 writeAndFlush() 方法将数据发送到远端服务节点。
再次回到 invoke() 方法的主流程,发送 RPC 远程调用后如何等待调用结果返回呢?之前介绍了如何使用 Netty 提供的 Promise 工具来实现 RPC 请求的同步等待,Promise 模式本质是一种异步编程模型,我们可以先拿到一个查看任务执行结果的凭证,不必等待任务执行完毕,当我们需要获取任务执行结果时,再使用凭证提供的相关接口进行获取。
服务提供者反射调用实现
之前介绍了服务提供者的 Handler 处理器,RPC 请求数据经过 MiniRpcDecoder 解码成 MiniRpcProtocol 对象后,再交由 RpcRequestHandler 执行 RPC 请求调用。一起先来回顾下 RpcRequestHandler 中 channelRead0() 方法的处理逻辑:
@Slf4j public class RpcRequestHandler extends SimpleChannelInboundHandler<MiniRpcProtocol<MiniRpcRequest>> { private final Map<String, Object> rpcServiceMap; public RpcRequestHandler(Map<String, Object> rpcServiceMap) { this.rpcServiceMap = rpcServiceMap; } @Override protected void channelRead0(ChannelHandlerContext ctx, MiniRpcProtocol<MiniRpcRequest> protocol) { RpcRequestProcessor.submitRequest(() -> { MiniRpcProtocol<MiniRpcResponse> resProtocol = new MiniRpcProtocol<>(); MiniRpcResponse response = new MiniRpcResponse(); MsgHeader header = protocol.getHeader(); header.setMsgType((byte) MsgType.RESPONSE.getType()); try { Object result = handle(protocol.getBody()); response.setData(result); header.setStatus((byte) MsgStatus.SUCCESS.getCode()); resProtocol.setHeader(header); resProtocol.setBody(response); } catch (Throwable throwable) { header.setStatus((byte) MsgStatus.FAIL.getCode()); response.setMessage(throwable.toString()); log.error("process request {} error", header.getRequestId(), throwable); } ctx.writeAndFlush(resProtocol); }); } }
因为 RPC 请求调用是比较耗时的,推荐的做法是将 RPC 请求提交到自定义的业务线程池中执行。其中 handle() 方法是真正执行 RPC 调用的地方,是我们这节课需要实现的内容,handle() 方法的实现如下所示:
private Object handle(MiniRpcRequest request) throws Throwable { String serviceKey = RpcServiceHelper.buildServiceKey(request.getClassName(), request.getServiceVersion()); Object serviceBean = rpcServiceMap.get(serviceKey); if (serviceBean == null) { throw new RuntimeException(String.format("service not exist: %s:%s", request.getClassName(), request.getMethodName())); } Class<?> serviceClass = serviceBean.getClass(); String methodName = request.getMethodName(); Class<?>[] parameterTypes = request.getParameterTypes(); Object[] parameters = request.getParams(); FastClass fastClass = FastClass.create(serviceClass); int methodIndex = fastClass.getIndex(methodName, parameterTypes); return fastClass.invoke(methodIndex, serviceBean, parameters); }
rpcServiceMap 中存放着服务提供者所有对外发布的服务接口,我们可以通过服务名和服务版本找到对应的服务接口。通过服务接口、方法名、方法参数列表、参数类型列表,我们一般可以使用反射的方式执行方法调用。为了加速服务接口调用的性能,我们采用 Cglib 提供的 FastClass 机制直接调用方法,Cglib 中 MethodProxy 对象就是采用了 FastClass 机制,它可以和 Method 对象完成同样的事情,但是相比于反射性能更高。
FastClass 机制并没有采用反射的方式调用被代理的方法,而是运行时动态生成一个新的 FastClass 子类,向子类中写入直接调用目标方法的逻辑。同时该子类会为代理类分配一个 int 类型的 index 索引,FastClass 即可通过 index 索引定位到需要调用的方法。
至此,整个 RPC 框架的原型我们已经实现完毕。你可以在本地先启动 Zookeeper 服务器,然后启动 rpc-provider、rpc-consumer 两个模块,通过 HTTP 请求发起测试,如下所示:


