
5 使用ip代理池爬取糗事百科
从09年读本科开始学计算机以来,一直在迷茫中度过,很想学些东西,做些事情,却往往陷进一些技术细节而蹉跎时光。直到最近几个月,才明白程序员的意义并不是要搞清楚所有代码细节,而是要有更宏高的方向,要有更专注的目标。我高中的时候,数学很好,总是满分。高考低了些,135。我有个特点就是,什么题目,不算个三四遍不死心。这就是一种完美主义和自我强迫。导致我很多事情落下进度。本该写论文的时候,我却疯一样去看代码去学程序。看klee,看bap,看pintrace。等到要毕业的时候,整日整日抽烟到吐,自食恶果。完美主义使我不能忽略一点点碍眼的事情。
最近本来只是想写爬虫玩玩的,却遇到一个ip代理的问题,就学习了一个网上的开源项目,本来也只是想试下这个项目玩玩的,却发现需要深入了解一些东西。换做曾经,可能按部就班跟踪每个变量,搞清楚每个函数,很细很细致。比如,曾经为了一个污点分析的pintrace源码,写了将近四万字的文档,投了两篇很水的文章,完全就是程序游戏,为了混个毕业。
技术只是很小的一方面。有很多东西,就仅仅是想法而已。千万不要再做一个搞清楚一切技术细节的人,否则就类似于古代寻章摘句的腐儒。胸无大略,只爱好舞文龙墨。
1 起步
糗事百科的爬取,见精通python网络爬虫一书。
存在的问题,爬了几次以后,ip被封,远程服务器拒绝访问。
2 ip代理池
ip代理池的基本思路是去几个提供代理ip的网站获取ip,验证,存入数据库。不想动手。网上找开源项目。找到一个:https://github.com/jhao104/proxy_pool。另外一个辅助介绍的网址:
https://m.jb51.net/article/102185.htm?from=timeline
3 开源项目proxy_pool代码调试
熟悉main.py,会启动三个进程。
通过跟踪程序执行,由于多进程不能用spyder调试,分别进入到各个进程执行的模块py文件中,再进行调试。
确定出项目不能正确执行的原因是卡死在:
即从各个代理ip网站中获取代理以后,写入本地数据库的时候出现死机。这就说明本地没有安装db服务。
下面是作者在github上提供的配置。
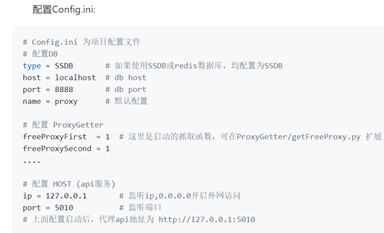
我决定不安装SSDB,而是直接将type改为我的mangodb(自己常用),然后看看能不能使用。
3.1 需要在源码中看看这个配置文件具体是怎么用的。
首先是主程序中的三大进程对应的模块是:

结合相关文档、调试、以及阅读代码,迅速确定出各个模块的功能:
- 第一个Api.ProxyApi是利用flask注册api服务,提供对数据库的操作接口。
- 第二个ProxyValidSchedule是不断从user_proxy数据表中删除无效ip代理地址。
- 另外一个ProxyRefreshSchedule是不断刷新代理ip网站,获取新ip,然后存入raw_proxy数据表。这个过程每10分钟执行一次。之后是从raw_proxy数据表中对每个ip进行验证,如果有效,则放入user_proxy数据表,无效则从表中删除。
后两个模块均继承ProxyManager类。
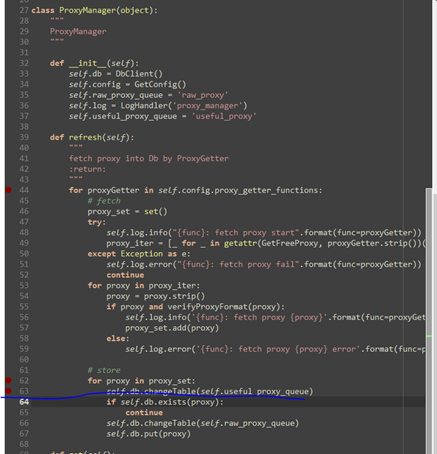
ProxyManager的init过程
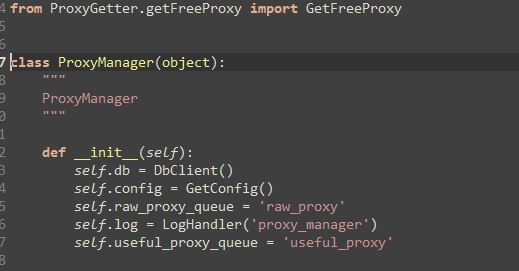
里面有一个init操作。调试以后,整个init都能执行。
我们初步猜测,DbClient是一种工厂模式,下面可以接各种类型的数据库。真正的处理在于self.db=DbClient()中。
DbClient类
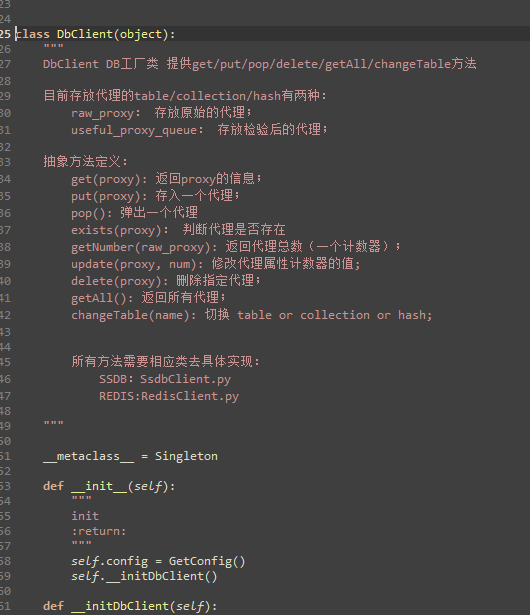
def __initDbClient(self):
"""
init DB Client
:return:
"""
__type = None
if "SSDB" == self.config.db_type:
__type = "SsdbClient"
elif "REDIS" == self.config.db_type:
__type = "RedisClient"
elif "MONGODB" == self.config.db_type:
__type = "MongodbClient"
else:
pass
assert __type, 'type error, Not support DB type: {}'.format(self.config.db_type)
self.client = getattr(__import__(__type), __type)(name=self.config.db_name,
host=self.config.db_host,
port=self.config.db_port)
可以看到,初始化DbClinet是可以选择底层数据库的。但是如果使用MongodbClient的话,需要实现专门的mongodbclient.py。即如果在config.in文件中设置type为Mongodb的话,会执行下面的语句
self.client=getattr((__import__(__type), __type)(name=self.config.db_name,
host=self.config.db_host,
port=self.config.db_port))
__import__动态加载模块,就是MongodbClient.py文件
getattr获取属性,就是py文件中的MongodbClient类。该类初始化传入三个参数,就是config.in文件中的配置信息。
查看MongodbClient.py文件
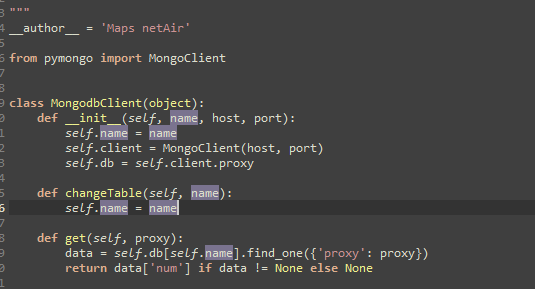
可以看到使用的是mongodb数据库官方提供的工具包pymongo
因此,我们需要对config.in文件中的host和port进行修改。因为本机常用的配置如下:
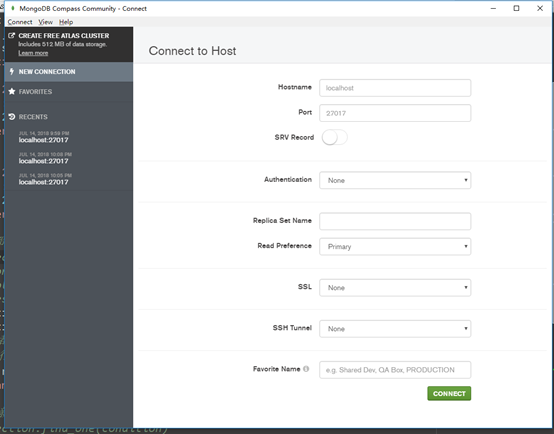
改为localhost和27017端口。
这个时候,我们修改config.in文件为

并且由于__init__中执行有self.db=self.client.proxy。我们需要手动创建一个proxy数据库。里面顺便添加上两个集合。就是存放代理的。
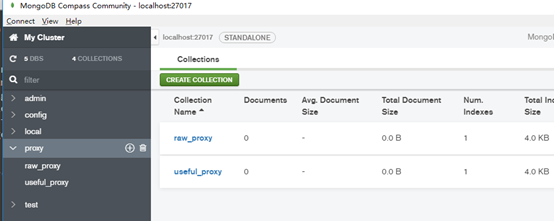
重新调试程序,程序正常执行。
数据库中可以看到:
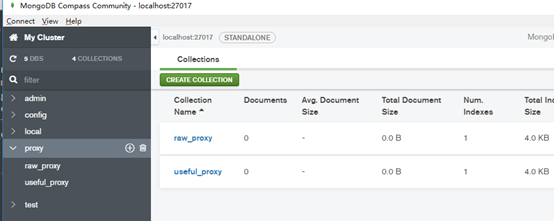
至此,一个开源项目调试通过。
3.2 flask提供的api接口访问数据库获取代理
在Api.ProxyApi模块中:
关键配置代码是:
在config.in文件中
注意:并不是说访问/0.0.0.0/:5010
flask中,host='0.0.0.0'表示让你的操作系统监听所有公开IP,并不是接口的ip地址。使用的时候,要用127.0.0.1。

4 使用代理池的方法
进入开源项目的源码D:\proxy_pool-master\Run下,命令行输入python main.py。就会运行前述的三个进程。当数据库的useful_proxy中有代理的时候,就能够使用了。注意,保证联网。此外,ProxyRefreshSchedule抓取代理,到放入useful_proxy数据表中,需要一定的实际。因为:
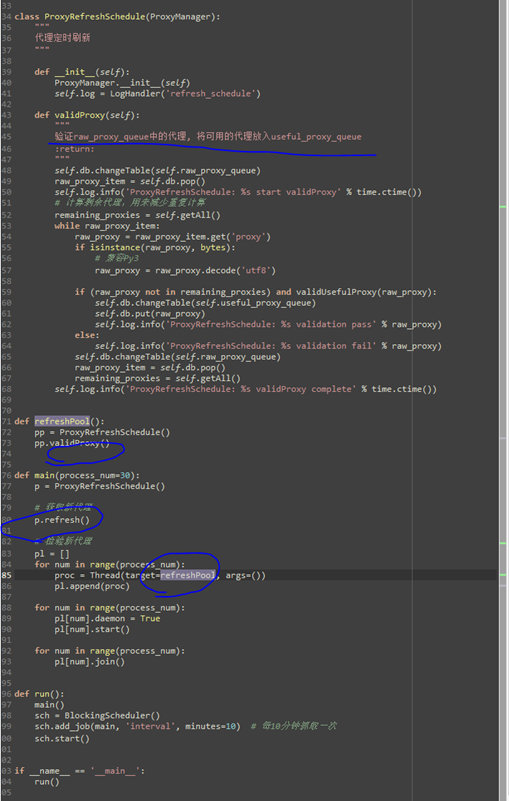
可以看到:先是refresh()从各个代理ip的提供网站中抓取代理放入raw_proxy数据表中,之后才是对raw_proxy中的ip地址进行验证,放入useful_proxy中(即有效ip代理地址的数据表)。而这个抓取的过程,会持续一段时间。
当数据库中有有效ip代理以后,可以使用下面的代码进行测试:
import requests
def get_proxy():
return requests.get("http://localhost:5010/get/").content
def delete_proxy(proxy):
requests.get("http://localhost:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy_addr = get_proxy().decode('utf-8')
print(proxy_addr)
import urllib.request
proxy=urllib.request.ProxyHandler({"http":"http://"+proxy_addr})
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400")
opener=urllib.request.build_opener(proxy)
opener.addheaders=[headers]
while retry_count > 0:
try:
# 使用代理访问
response=opener.open("http://httpbin.org/get")
data=response.read().decode('utf-8')
print ("使用代理成功")
return data
except Exception:
retry_count -= 1
# 出错5次, 删除代理池中代理
print ("使用代理失败,代理ip无效")
delete_proxy(proxy)
return None
if __name__ == '__main__':
print (getHtml())
其中,用到了一个很有趣的地址,http://httpbin.org/get,其返回的页面数据中会包括访问该网址的客户端所用的真正的地址。

http://httpbin.org/get是专门用来测试访问服务器的实际ip地址的。
这里面有一个不属于技术问题的问题,就是我用华为mifi开的热点,会提示404 found,同时在浏览器中访问http://httpbin.org/get会提示404 Not Found
而使用手机移动流量开的热点,则不存在这种问题。能够正常访问。记录的origin也和使用的代理一致。
5 蹲了个大号,ip代理数据库空了
蹲坑看书是我的一个习惯。曾经蹲坑看完整本隋唐演义。蹲坑回来,ip代理数据库空了。一阵吃惊。
曾经看代码,会搞清楚每个细节。现在不会了。所以对待这个ip代理池的开源项目,就是结合文档和源码,搞清楚各个模块之间的关系,整体的结构,业务流程以及各个模块具体的功能。再往下就不会深入了。毕竟马上就是要三十的人,不是九年前那个看代码死去活来的少年。所以,突然间没了,真的是。。。滋味比较酸爽。
追踪代码大致观察到:
ProxyRefreshSchedule会不断从代理服务ip的各大网站抓取ip地址,填充到Raw_proxy中,但是由于上面对ip的验证过程存在的网络问题,所以一直验证失效。最后就会发现,没有数据进入raw_proxy表中。此外,另外一个进程ProxyValidShedule也会一直从useful_proxy中抓取ip地址,进行验证,将无效的删除。这两大模块使用的一个关键验证代理的过程如下:
# noinspection PyPep8Naming
def validUsefulProxy(proxy):
"""
检验代理是否可用
:param proxy:
:return:
"""
if isinstance(proxy, bytes):
proxy = proxy.decode('utf8')
proxies = {"http": "http://{proxy}".format(proxy=proxy)}
try:
# 超过20秒的代理就不要了
r = requests.get('http://httpbin.org/ip', proxies=proxies, timeout=10, verify=False)
if r.status_code == 200:
# logger.info('%s is ok' % proxy)
return True
except Exception as e:
# logger.error(str(e))
return False
我上厕所的时候,手机流量开的wifi热点跟着走了,电脑没了网络。于是,所有的ip代理地址均验证不通过,返回的状态码不可能是200,所以,数据库中的ip都被删除,就这样,回来惊见数据库空了,顿时凉凉的感觉。
6 避免被各大代理网站限制的方法
如果你一直从各大代理等网站反复抓取ip,你会发现:
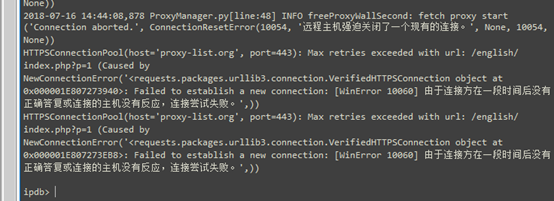
为了解决糗事百科限制ip的问题,你去抓ip代理地址。但是,ip代理地址的提供网站也会限制ip。
因此,不用源项目作者提供的方法。在数据库中积累一定的ip代理地址量以后,可以直接启动flask接口服务。不要一直在那抓取。
7 抓取糗事百科的数据(xpath)
源代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Jul 14 15:24:51 2018
@author: a
"""
import urllib.request
import re
from urllib.error import HTTPError
from urllib.error import URLError
import os
import time
import random
from lxml import etree
import requests
import sys
from threading import Thread
sys.path.append('D:\proxy_pool-master')
from Util.utilFunction import validUsefulProxy
class MySpider:
pagenum=0
def headers(self):
headers_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400",
"Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0",
"Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)",
"Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1",
"Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TencentTraveler4.0)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Maxthon2.0)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;360SE)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1)",
]
ua_agent = random.choice(headers_list)
return ua_agent
def load_page(self, url, header):
print ("进入load_page函数")
print("load_url:",url)
#获取有效能使用的代理
proxy=self.get_proxy()
print("暂取出的代理是:",proxy)
success=validUsefulProxy(proxy)
print("代理是否有效的验证结果:",success)
while ((proxy==None)|(success==False)):
proxy=self.get_proxy()
print("暂取出的代理是:",proxy)
success=validUsefulProxy(proxy)
print("代理是否有效的验证结果:",success)
continue
print("获取有效能使用的代理是:",proxy)
proxy=urllib.request.ProxyHandler({"http":"http://"+str(proxy)})
headers=("User-Agent",header)
opener=urllib.request.build_opener(proxy)
opener.addheaders=[headers]
try:
response=opener.open(url)
data=response.read()
except HTTPError as e:
print(("访问%s出现HTTP异常")%(url))
print(e.code)
print(e.reason)
return None
except URLError as e:
print(("访问%s出现URL异常")%(url))
print(e.reason)
return None
finally:
pass
#read返回的是bytes。
print ("使用代理成功加载url:",url)
print ("退出load_page函数")
return data
#使用代理加载网页
def parse(self, html,switch):
print ("进入parse函数")
if switch==1:
print("这里是糗事百科的网页解析规则")
data=html.decode('utf-8')
# print (data)
xpath_value='//*/div[1]/a[2]/h2'
#注意xpath选择器返回的是列表
selector = etree.HTML(data)
userlist=[value.text for value in selector.xpath(xpath_value)]
#print ("用户名:",userlist)
#xpath_value2='//*/a[1]/div/span/text()'
#contentlist=[value for value in selector.xpath(xpath_value2)]
#糗事百科有一个特点,使用上面的xpath取出的用户发表的内容,如果用户
#发表的内容,就有各种换行,那么取出来的本身就会是一种列表。一行内容对应一个元素
#用下面的方法
xpath_value2='//*/a[1]/div[@class="content"]'
contentlist=[]
for value in selector.xpath(xpath_value2):
info = value.xpath('string(.)')
contentlist.append(info)
#print(contentlist)
f=open('糗事百科爬取的的内容.txt', 'a',encoding='utf8')
x=1
#通过for循环遍历段子内容并将内容分别赋给对应的变量
for content in contentlist:
content=content.replace("\n","")
#用字符串作为变量名,先将对应字符串赋给一个变量
name="content"+str(x)
#通过exec()函数实现用字符串作为变量名并赋值
exec(name+'=content')
x+=1
y=1
#通过for循环遍历用户,并输出该用户对应的内容
for user in userlist:
content=content.replace("\n","")
name="content"+str(y)
f.write("----第%d页第%d个用户是:%s"%(self.pagenum,y,user))
f.write("----内容是:\n")
exec("f.write("+name+")")
f.write("\n")
y+=1
f.close()
else:
print("尚未制定解析规则")
print ("退出parse函数")
def get_proxy(self):
return requests.get("http://localhost:5010/get/").content
def delete_proxy(self,proxy):
requests.get("http://localhost:5010/delete/?proxy={}".format(proxy))
def main(self):
if(os.path.isfile('糗事百科爬取的的内容.txt')):
os.remove("糗事百科爬取的的内容.txt")
for page in range(1,30):
#如果超出糗事百科热门内容的页数,均会被导向第一页。
header = self.headers()
#url="https://www.qiushibaike.com"
url="https://www.qiushibaike.com/8hr/page/"+str(page)
self.pagenum=page
html = self.load_page(url, header)
self.parse(html,1)
if __name__ == "__main__":
myspider = MySpider()
myspider.main()
其中,使用代理池项目的对ip代理地址进行验证的过程。
代码解决了两个问题:
1. 代理ip的问题。我最初抓取的时候,遇到了:
RemoteDisconnected: Remote end closed connection without response
2. 用户发表的内容在span标签中被多个<br>隔开。这个时候,要用string方法。
最后抓取的结果:

有一个问题:糗事百科中还会有:
1.查看全文按钮;2.图片 3.其它用户的评论。
对于这些,很简单。
查看全文,用selenium框架模拟点击过程,取出即可。
图片,不用多言。
其它用户的评论,你构建xpath表达式即可。
8 总结
也许是偷懒。搞清楚一个项目,千万不要太寻章摘句了。还是大处着手,浅尝辄止,调通算求。搞清楚这个代理池项目,只花了两个小时左右。
9 其它问题
python的编码机制问题。从bytes(gbk,utf等)到str(unicode)之间的encode和decode转换。不再赘述。

