
2 模拟登录_Post表单方式(针对chinaunix有效,针对csdn失效,并说明原因)
参考精通Python网络爬虫实战
首先,针对chinaunix
import urllib.request #原书作者提供的测试url url="http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=LctlC" headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400") postdata=urllib.parse.urlencode({ "username":"xiaojieshisilang", "password":"XXXXX" }).encode('utf-8') req=urllib.request.Request(url,postdata) req.add_header(headers[0],headers[1]) data=urllib.request.urlopen(req).read() #print (data) fhandle=open("./8.html","wb") fhandle.write(data) fhandle.close() #设置要爬去的该网站下其他网页的网址 url2="http://bbs.chinaunix.net/forum.php?mod=guide&view=my"#这是从网页登录以后,才能进入的个人空间。 req2=urllib.request.Request(url2,postdata) req2.add_header(headers[0],headers[1]) data2=urllib.request.urlopen(req2).read() #print (data2) fhandle=open("./8_2.html","wb") fhandle.write(data2) fhandle.close()
上面的password需要你自己去注册。
关键点在于获取用于针对post用户名和密码信息之后的那个URL,以及构建PostData表单字典。
第一,如何获取URL呢?
F12打开调试界面。
输入错误的用户名add和密码add,可以看到URL信息如下:
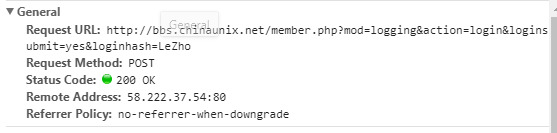
以及FormData信息如下:
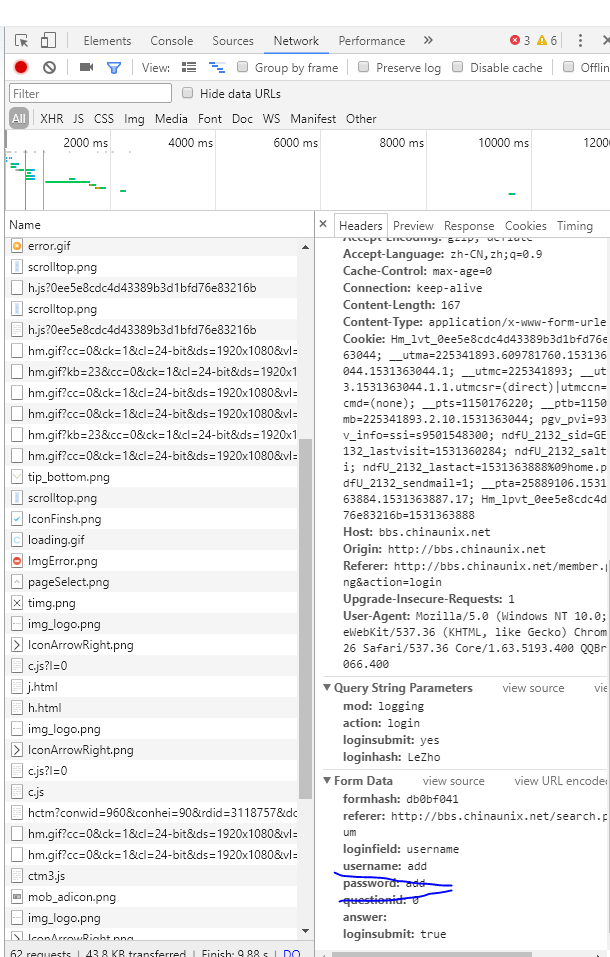
同时,我们就能构造出
postdata=urllib.parse.urlencode({
"username":"xiaojieshisilang",
"password":"XXXXXXXXXXX"
}).encode('utf-8')
这里要填入正确的用户名和密码。
最后代码的运行结果是:打开8_html
同时,8-2.html则是:
关于构建postData时的名称,除了用F12调试的方式。
另外一种是,直接放在文本框,用右键检查的方式,从而定位到相应的源码,取出表单的名称,比如:username和password。
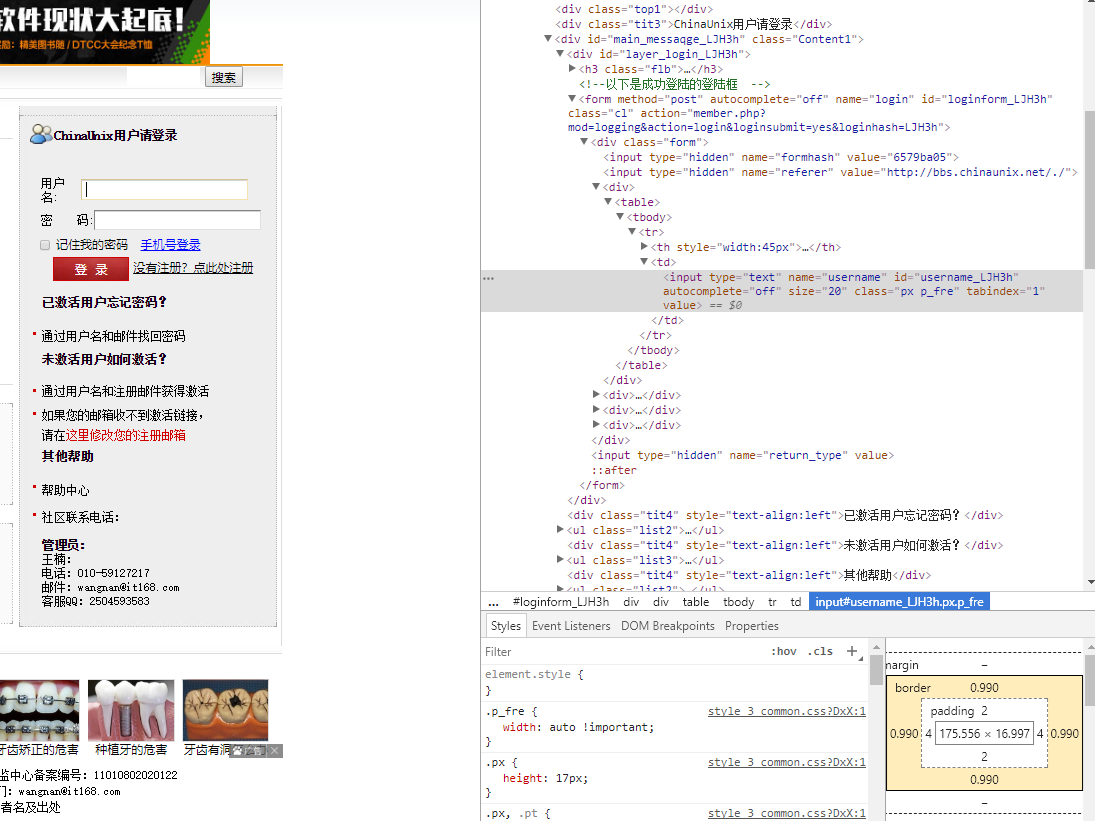
下面针对CSDN进行类似操作
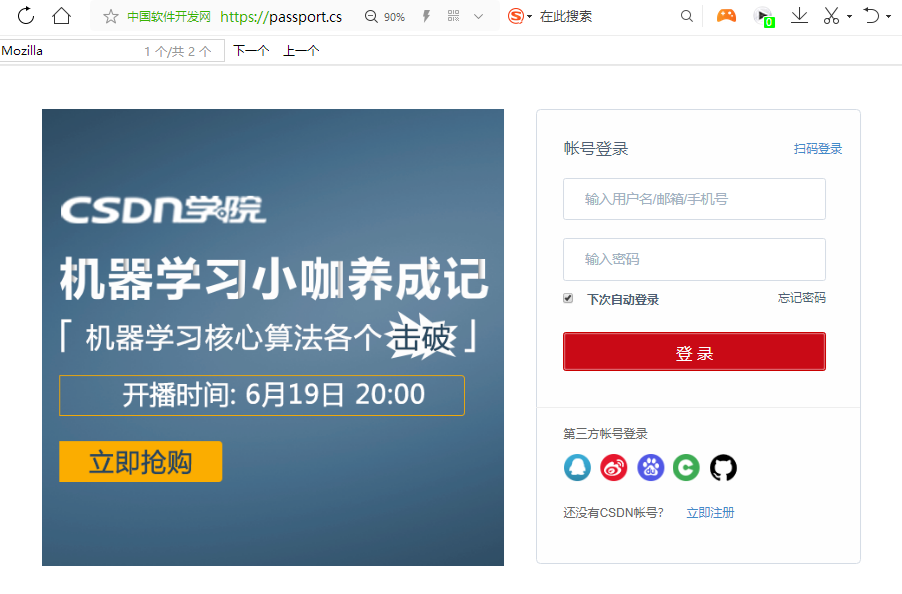
输入错误的用户名和密码
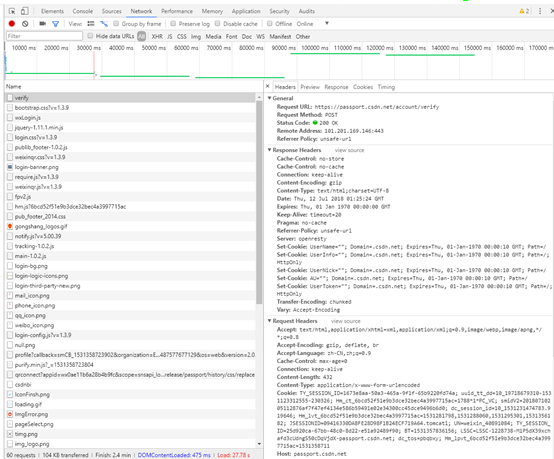
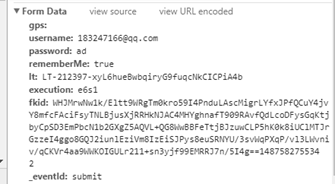
这个时候,查看Form Data,即表单数据。

import urllib.request url="https://passport.csdn.net/account/verify" headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400") postdata=urllib.parse.urlencode({ "username":"183247166@qq.com", "password":"XXXXXX" }).encode('utf-8') req=urllib.request.Request(url,postdata) req.add_header(headers[0],headers[1]) data=urllib.request.urlopen(req).read() #print (data) fhandle=open("./8.html","wb") fhandle.write(data) fhandle.close() #设置要爬去的该网站下其他网页的网址 url2="https://download.csdn.net/my"#这是从网页登录以后,才能进入的个人空间。 req2=urllib.request.Request(url2,postdata) req2.add_header(headers[0],headers[1]) data2=urllib.request.urlopen(req2).read() #print (data2) fhandle=open("./8_2.html","wb") fhandle.write(data2) fhandle.close()
结果是:
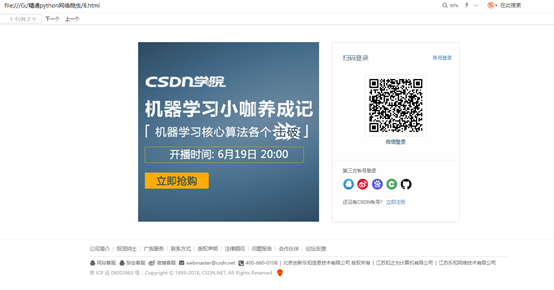
不能正确登录csdn,并且爬虫。
这说明,csdn的验证机制,不是简单的一个post就能完成的。
失败原因分析
https://blog.csdn.net/yanggd1987/article/details/52127436
这个链接是前人的博客。大家同时可以参考Python3网络爬虫开发实战一书中的观点,要先获取隐藏表单中的值,然后再构造post数据,用python模拟登录。
但是,最新版本,截止到当前时间2018年7月13日09:54:03时,csdn的验证机制变了。具体如下:
用F12进行调试时,追踪post请求数据,可以看到,相比于以前各个博文中的多了一个fkid值。
之前的:
values = {
"username":"用户名",
"password":"密码",
"lt":lt,
"execution":execution,
"_eventId":"submit"
}
现在的:
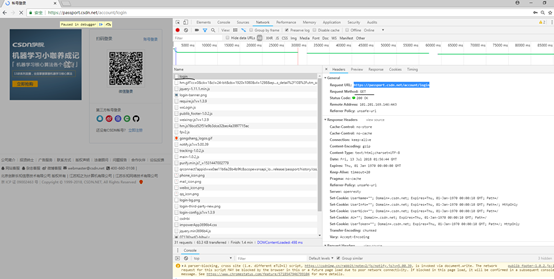
尝试抓取隐藏表单数据。我们F12调试的时候,选择Preseve log选项,选择chrome浏览器。
刷新csdn的登录界面,可以看到开发者模式记录的第一个请求实Get请求,访问的是https://passport.csdn.net/account/login,类似于github的机制,这个时候,访问这个页面,会忘隐藏表单中填入相关的数据。具体请求的信息如下:
服务器会Response一些set_cookie的信息,要求浏览器客户端设置cookie文件。
这些暂时不用考虑。
我们点击“扫码登录”,然后鼠标放在密码的文本框上,右键选择检查,可以看到:
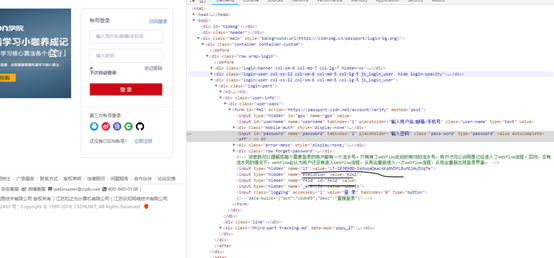
FORM中隐藏表单中的lt,execution等都已经填入了相关值。你可以进一步做实验,每次刷新login页面,这些值都会变化。我们发现fkid这个新属性(csdn最新添加的属性)并没有值。仍是value。我们参考Python3网络爬虫开发实战中的方法编写如下代码取出隐藏表单的值:
这里面用到XPATH。
如何知道XPATH,直接在F12模式的表单input位置,右键选择copy XPATH即可。
import urllib.request
import requests
from lxml import etree
#获取加载的it/execution/fkid等的值
headers = {
'Referer': 'https://www.csdn.net/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400',
'Host': 'passport.csdn.net'
}
login_url="https://passport.csdn.net/account/login"
session = requests.Session()
response = session.get(login_url, headers=headers)
selector=etree.HTML(response.text)
execution=selector.xpath('//input[@name="execution"]/@value')[0]
print (execution)
_eventId=selector.xpath('//input[@name="_eventId"]/@value')[0]
print (_eventId)
lt=selector.xpath('//input[@name="lt"]/@value')[0]
print (lt)
fkid=selector.xpath('//*[@id="fkid"]/@value')[0]
print (fkid)
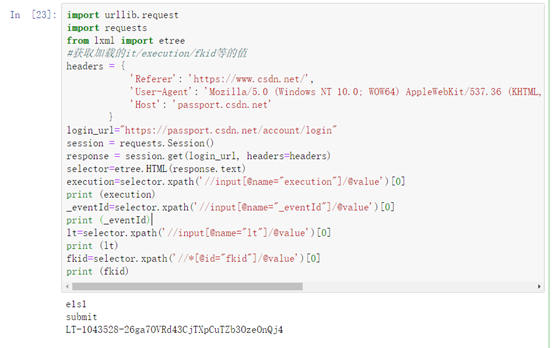
可以看到,fkid的值根本不存在。这个时候,我们就要思考post数据中明明发出了fkid值,为什么这里不存在。(因为运行js代码更新的表单数据是不能通过在网页中抓取的。)
我们查看网页预加载的几个js文件,找到如下js代码:
https://csdnimg.cn/release/passport/history/js/apps/login.js?v=1.3.9
它里面有:
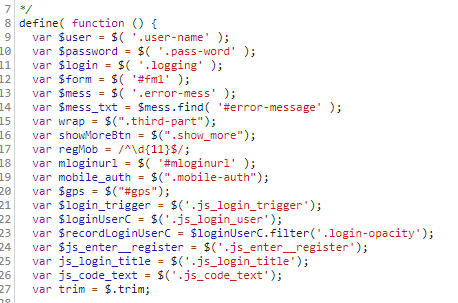

也即初始化的时候,就为登录按钮注册了一个onclick函数,执行的内容是,检查用户名,检查密码,然后计算fkid的值。
我们下断点,然后在浏览器中随便输入abd作为用户名,随便输入abd作为密码。
然后跟踪到81行代码处。
到达断点位置以后,在console控制台取出真正的fkid值。

SMSdk是csdn开发者加入到window属性中的。
将鼠标放在SMSdk上,会显示其中的getDeviceId方法,
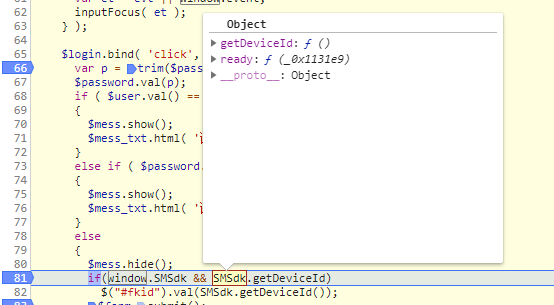
鼠标放在getDeviceId上,右键show function definition

可以看到代码被混淆了,目的的就是防止被别人看。
用python写一个功能完全相同的代码不太现实。如果知道机制,还可以用python从网页中取出某些元素,然后算出fkid,传回服务器,同用户名、密码一起形成验证。但是现在不知道机制,就连计算的js代码都被混淆了。
于是:第一,输入是什么,也就是从页面中取出哪些值进行计算,这个不确定。我猜测csdn取得就是webflow的流水号,你可以看csdn的登录页面的源码。第二,运算过程怎么样,也不知道。
这个时候,只能用python执行js程序。这个时候想到了node.js。
具体过程不在展开。你会发现遇到一个问题,就是直接调用混淆化后的js代码,会提示window没有定义。因为node.js中使用的是global作为全局属性,而window则是浏览器中才有的。
也就是说,会发现没法用node.js执行这些js代码。所以这种直接用python去模拟这么复杂的验证过程,比较困难。选择采用一些能够模拟浏览器的框架。注意,不单纯是模拟发送请求,接收返回的urllib包,而是模拟浏览器行为!这些就是针对类似csdn这种有复杂验证机制的爬虫。
于是就产生了第三篇博文,
3 使用selenium模拟登录csdn
用selenium进行模拟登录,保存cookie。
