

mysql 原理
要掌握一个数据库,必须掌握基础的操作;要调优一个数据库,就必须掌握底层的原理。
mysql每一个表都对应了一棵B+数,那么他就会存在叶子节点和非叶子节点,所有的节点都对应了一个16K的页。所有的叶子节点都存储的真实数据,叶子直接通过双向链表连接。
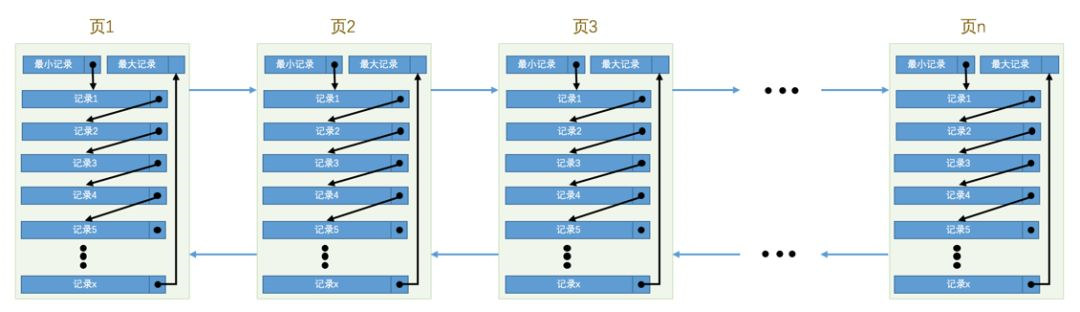
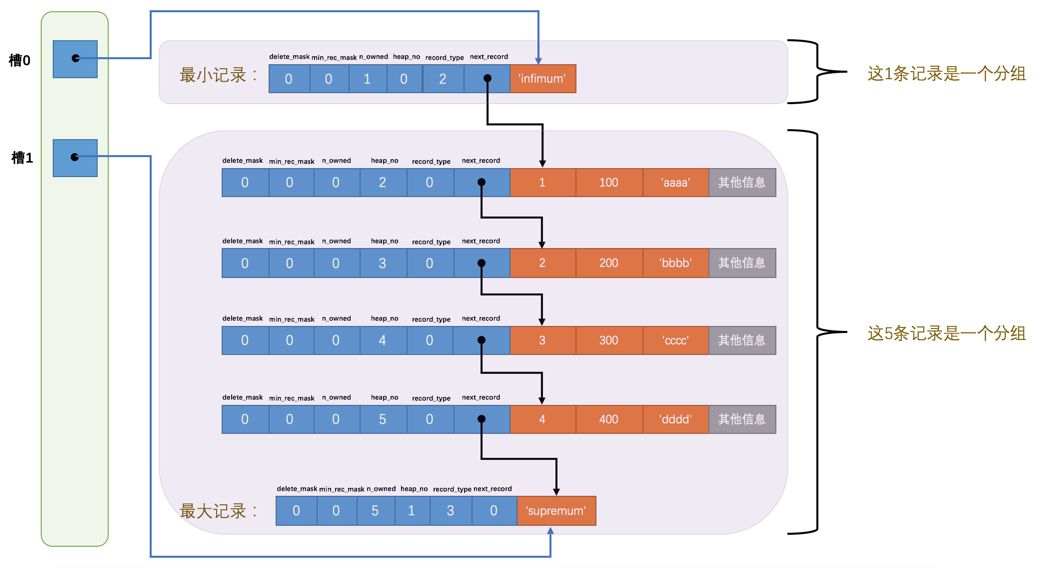
页内部所有数据通过单向链表连接,根据主键排序(没有主键会自动创建虚拟id),分为不同的分组(每一组叫一个槽)。
创建一个表的同时会创建一个聚簇索引,包含主键和所有列。用户创建的索引叫二级索引,包含某一列和主键,假如包含多个列叫联合索引。所有的索引都是一棵B+树,只是它不包含所有的信息。
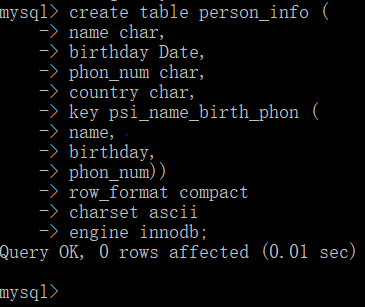
如图,用户创建表的同时创建了一个联合索引,不包含country

当用户用上述查询语句时,首先根据name的值,从索引树的根节点开始二分查询,到目录节点,再到叶子节点,定位到最终的叶子页。进入页之后,根据槽定位到对应的分组,然后定位到需要的数据。此时可以能有很多条,然后再匹配birthday,再匹配phon_num.
mysql有很多的存储引擎,比如说Inoodb,MyISAM,Memory。这里主要讲Inoodb.
行结构
Innodb有很多种行结构,Compact,Redundant,Dynamic,Compressed,这里讲最常见的Compact。
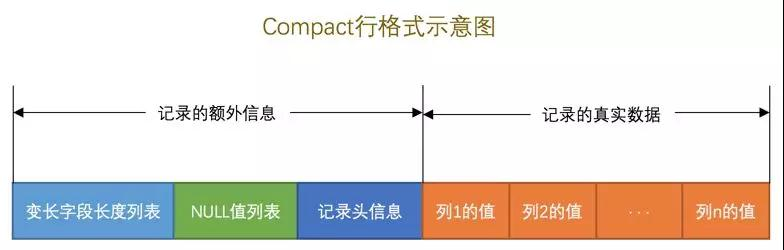
变长数据长度列表储存的是变长数据类型数据的字节数逆顺序,空值列不储存。
NULL值列表储存非主键和没有被NOT NULL 修饰的列,二进制位逆顺序进行储存。
记录头信息包括了偏移量,槽数量,本组数据量,是否被删除,数据类型,是不是B+树子节点等等信息。
页结构
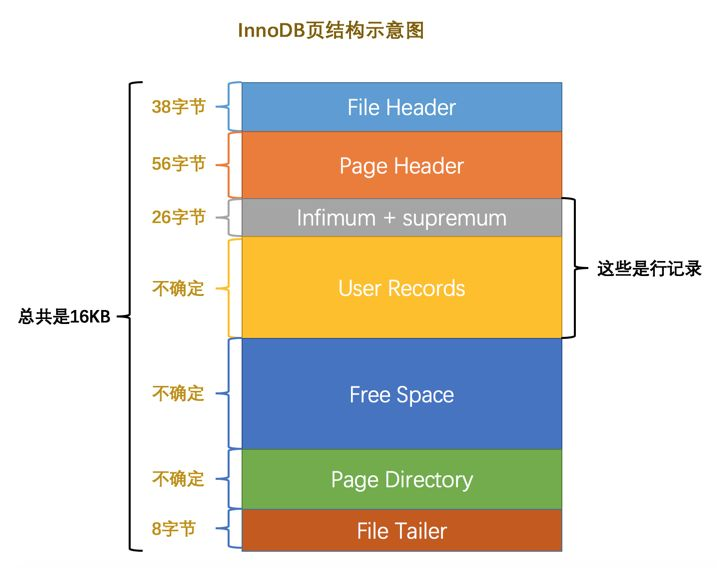
1.数据页由七部分组成,包括File Header(描述页的信息)、Page Header(描述数据的信息)、Infimum + Supremum(页中的虚拟数据最大值和最小值)、User Records(用户真实数据储存的部分)、Free Space(真实数据增加划分的部分空间)、Page Directory(页中记录相对位置,槽储存的位置)、File Trailer(检验16kb大小的数据页是否完整)。
2.每一个页中的数据都是单向链表,由数据的记录头信息next_record进行维护,记录的是相对于本数据下一条数据的距离字节数。内存中的页是双向链表的数据结构,由页信息的本页号码,上一页号码,下一页号码进行维护。
3.页中的数据都会进行分组,虚拟最小数据是一组,最大数据组最多存在8条数据,满额是二分成普通分组数据。每个分组的最后一条数据相对于页的偏移量就是槽的数据。本页中数据的查找采用的就是二分法,通过槽确定数据所在的分组,然后在进行搜索。
索引
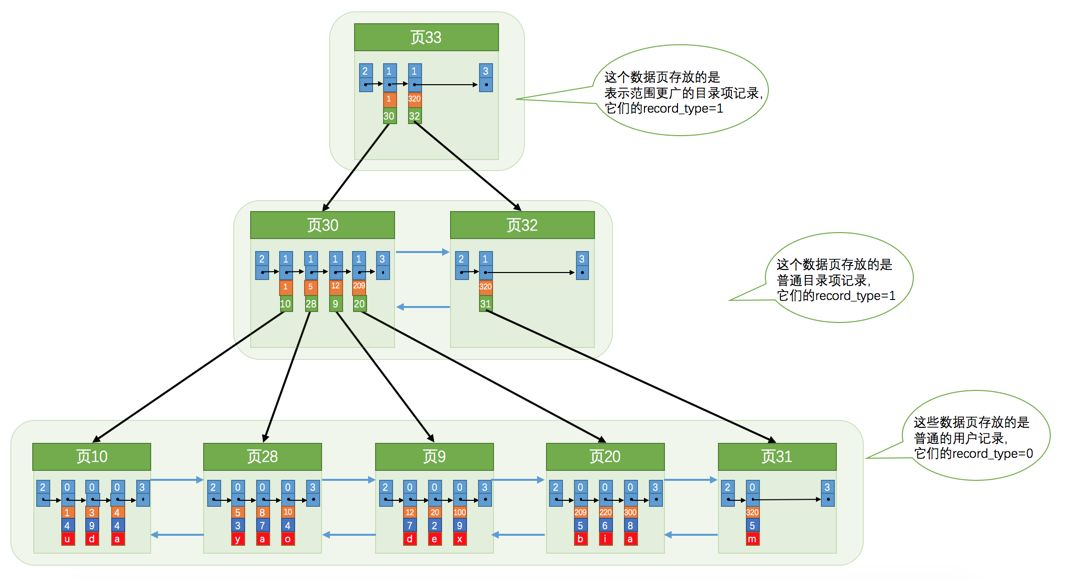
1.一个索引对应一颗B+树,所有的真实记录都是存在叶子节点里面的,所有的项目录都存在内节点或者说根节点上。
2.innodb会为我们的表格主键添加一个聚簇索引,如果没有主键的话数据库是会为我们自动添加row_id这一列的。聚簇索引的叶子节点包含完整的用户记录。
3.我们是可以为自己感兴趣的列添加二级索引的,二级索引的叶子节点没有用户完整的信息,只是拥有对应列和主键的信息,如果想要拥有完整的信息是需要进行回表操作用二级索引找到的主键去聚簇索引寻找完整信息。假如添加了多个列,那就是联合索引,联合索引的搜索规则是,先按第一列取搜索,匹配到了相同的,再按后面的列搜索
4.B+树的每一层节点都是按照索引列的大小信息进行排序而组成的双向链表,每个页里里面的记录也是按照索引列大小信息组成的单向链表。如果是联合索引的话,先按照前面的列进行排序,如果是相同的情况下再根据其他的列进行排序。
5.每个索引的搜索都是从根节点进行的,由于每个页面都按照索引列的值建立了Page Directory,所以在确定了具体页面信息的情况下是可以根据二分法进行快速的定位的。
老规矩,附上干货:
行结构:https://www.cnblogs.com/zslli/p/8855634.html
页结构:https://www.cnblogs.com/zslli/p/8888285.html

