3-9 YOLO 算法
YOLO 算法(Putting it together: YOLO algorithm)
假设你要训练一个算法去检测三种对象,行人、汽车和摩托车,你还需要显式指定完整的背景类别。这里有 3 个类别标签,如果你要用两个 anchorbox,那么输出y就是 3×3×2×8,其中 3×3 表示 3×3 个网格, 2 是 anchor box 的数量, 8 是向量维度。你可以将它看成是 3×3×2×8,或者 3×3×16。要构造训练集,你需要遍历 9 个格子,然后构成对应的目标向量y。
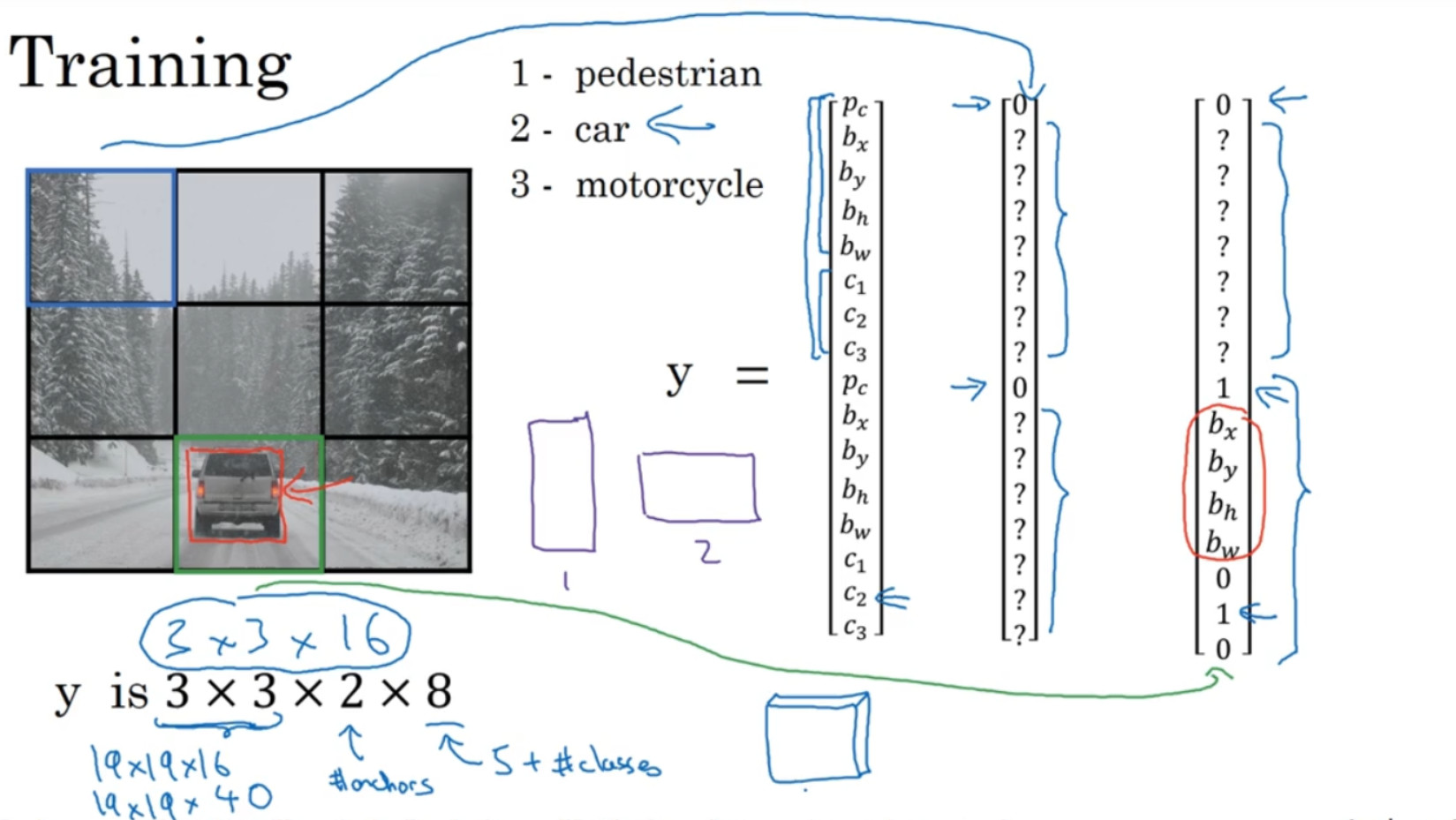
所以你这样遍历 9 个格子,遍历 3×3 网格的所有位置,你会得到这样一个向量,得到一个 16 维向量,所以最终输出尺寸就是 3×3×16。
实践中用的可能是 19×19×16,或者需要用到更多的 anchor box,可能是 19×19×5×8,即 19×19×40,用了 5 个 anchor box。这就是训练集,然后你训练一个卷积网络,输入是图片,可能是 100×100×3,然后你的卷积网络最后输出尺寸是,在我们例子中是 3×3×16 或者3×3×2×8。

最后你要运行一下这个非极大值抑制, 如果你使用两个 anchor box,那么对于 9 个格子中任何一个都会有两个预测的边界框,其中一个的概率${p_c}$很低。但 9 个格子中,每个都有两个预测的边界框,比如说我们得到的边界框是是这样的,注意有一些边界框可以超出所在格子的高度和宽度。接下来你抛弃概率很低的预测,去掉这些连神经网络都说,这里很可能什么都没有,所以你需要抛弃这些。
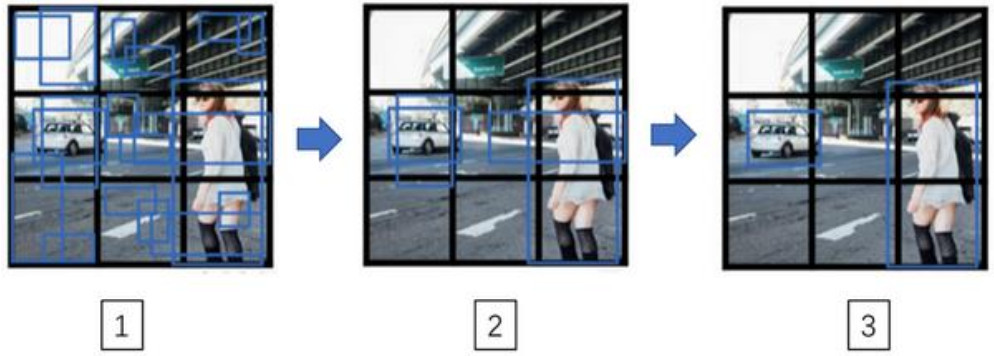
最后,如果你有三个对象检测类别,你希望检测行人,汽车和摩托车,那么你要做的是,对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,用非极大值抑制来处理行人类别,用非极大值抑制处理车子类别,然后对摩托车类别进行非极大值抑制,运行三次来得到最终的预测结果。所以算法的输出最好能够检测出图像里所有的车子,还有所有的行人。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号