2-8 数据扩充
数据扩充(Data augmentation)
大部分的计算机视觉任务使用很多的数据,所以数据扩充是经常使用的一种技巧来提高计算机视觉系统的表现。在实践中,更多的数据对大多数计算机视觉任务都有所帮助,不像其他领域,有时候得到充足的数据,但是效果并不怎么样。但是,当下在计算机视觉方面,计算机视觉的主要问题是没有办法得到充足的数据。所以这就意味着当你训练计算机视觉模型的时候,数据扩充会有所帮助,这是可行的,无论你是使用迁移学习,使用别人的预训练模型开始,或者从源代码开始训练模型。
最简单的数据扩充方法就是垂直镜像对称:

另一个经常使用的技巧是随机裁剪:
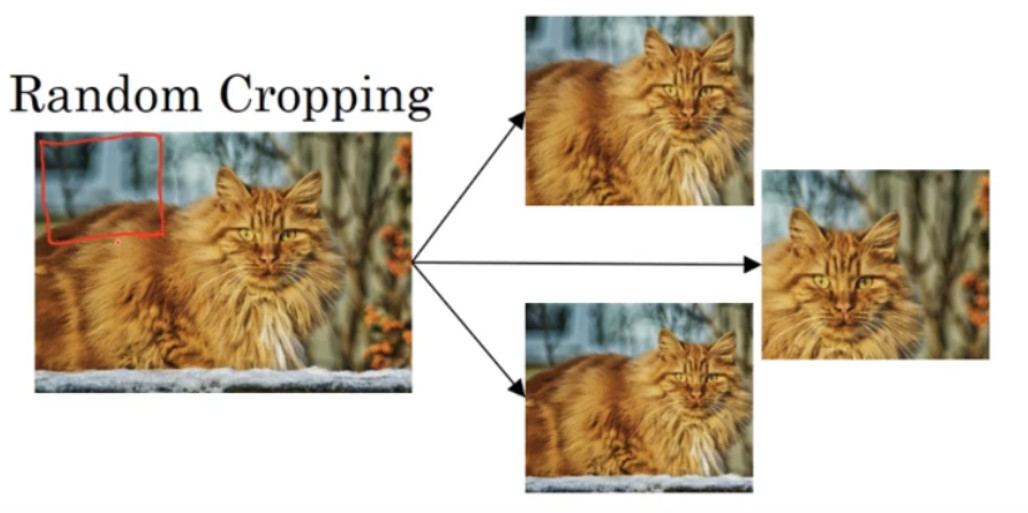
当然,理论上,你也可以使用旋转,剪切(shearing:此处并非裁剪的含义,图像仅水平或垂直坐标发生变化)图像,可以对图像进行这样的扭曲变形,引入很多形式的局部弯曲等等。
第二种经常使用的方法是彩色转换,有这样一张图片,然后给 R、 G 和 B 三个通道上加上不同的失真值。
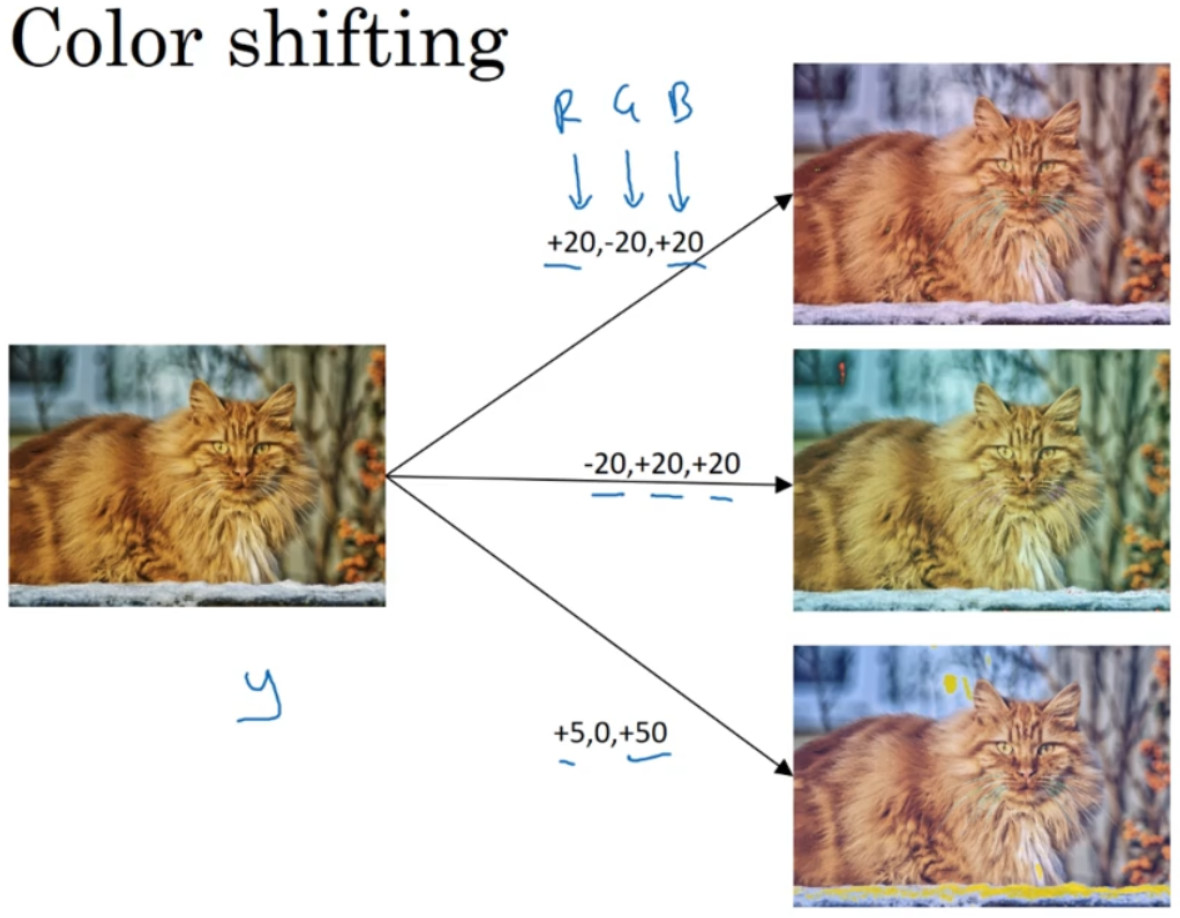
这么做的理由是,可能阳光会有一点偏黄,或者是灯光照明有一点偏黄,这些可以轻易的改变图像的颜色,但是对猫的识别,或者是内容的识别,以及标签y,还是保持不变的。所以介绍这些,颜色失真或者是颜色变换方法,这样会使得你的学习算法对照片的颜色更改更具鲁棒性。
对 R、G 和 B 有不同的采样方式,其中一种影响颜色失真的算法是 PCA,即主成分分析。但具体颜色改变的细节在 AlexNet 的论文中有时候被称作 PCA 颜色增强, PCA 颜色增强的大概含义是,比如说,如果你的图片呈现紫色,即主要含有红色和蓝色,绿色很少,然后 PCA 颜色增强算法就会对红色和蓝色增减很多,绿色变化相对少一点,所以使总体的颜色保持一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号