2-3 残差网络为什么有用?
残差网络为什么有用?( Why ResNets work?)
一个网络深度越深,它在训练集上训练的效率就会有所减弱,这也是有时候我们不希望加深网络的原因。而事实并非如此,至少在训练 ResNets网络时,并非完全如此,举个例子:
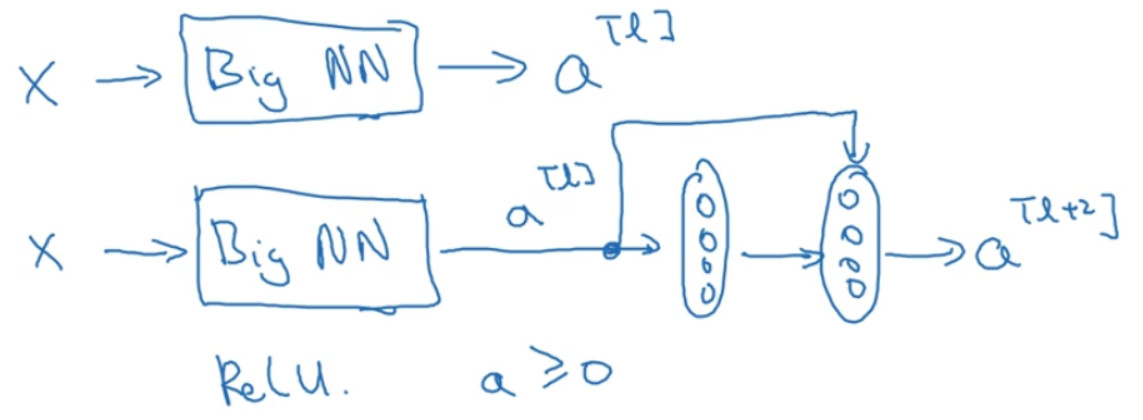
设有一个大型神经网络,其输入为X,输出激活值${a^{[l]}}$ 。假如你想增加这个神经网络的深度,那么用 Big NN 表示,输出为${a^{[l]}}$ 。再给这个网络额外添加两层,依次添加两层,最后输出为${a^{[l+2]}}$ ,可以把这两层看作一个 ResNets 块,即具有捷径连接的残差块。为了方便说明,假设我们在整个网络中使用 ReLU 激活函数,所以激活值都大于等于 0,包括输入X的非零异常值。因为 ReLU 激活函数输出的数字要么是 0,要么是正数。
${{\rm{a}}^{[l + 2]}} = g({{\rm{z}}^{[l + 2]}} + {{\rm{a}}^{[l]}})$
展开:
${{\rm{a}}^{[l + 2]}} = g({{\rm{z}}^{[l + 2]}}) = g({W^{[l + 2]}}{a^{[l + 1]}} + {b^{[l + 2]}} + {{\rm{a}}^{[l]}})$
这里的W是关键项,如果:
${W^{[l + 2]}} = 0$,为方便起见,假设${b^{[l + 2]}} = 0$
那么:
${W^{[l + 2]}}{a^{[l + 1]}} + {b^{[l + 2]}} = 0$
因为我们假定使用 ReLU 激活函数,并且所有激活值都是非负的,从而:
${{\rm{a}}^{[l + 2]}} = g({{\rm{a}}^{[l]}}) = {{\rm{a}}^{[l]}}$
结果表明,残差块学习这个恒等式函数并不难,跳跃连接使我们很容易得出:
${{\rm{a}}^{[l + 2]}} = {a^{[l]}}$
这意味着,即使给神经网络增加了这两层,它的效率也并不逊色于更简单的神经网络,因为学习恒等函数对它来说很简单。尽管它多了两层,也只把${a^{[l]}}$ 的值赋值给${{\rm{a}}^{[l + 2]}}$ 。所以给大型神经网络增加两层,不论是把残差块添加到神经网络的中间还是末端位置,都不会影响网络的表现。

当然,我们的目标不仅仅是保持网络的效率,还要提升它的效率。想象一下,如果这些隐藏层单元学到一些有用信息,那么它可能比学习恒等函数表现得更好。而这些不含有残差块或跳跃连接的深度普通网络情况就不一样了,当网络不断加深时,就算是选用学习恒等函数的参数都很困难,所以很多层最后的表现不但没有更好,反而更糟。
我认为残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,你能确定网络性能不会受到影响,很多时候甚至可以提高效率,或者说至少不会降低网络的效率,因此创建类似残差网络可以提升网络性能。
关于残差网络,另一个值得探讨的细节是,假设${{\rm{z}}^{[l + 2]}}$ 与${{\rm{a}}^{[l]}}$
具有相同维度,所以 ResNets 使用了许多 same 卷积,所以这个${{\rm{a}}^{[l]}}$ 的维度等于这个输出层的维度。之所以能实现跳跃连接是因为 same 卷积保留了维度,所以很容易得出这个捷径连接,并输出这两个相同维度的向量。
如果输入和输出有不同维度,比如输入的维度是 128,${{\rm{a}}^{[l + 2]}}$ 的维度是 256,再增加一个矩阵,这里标记为${W_s}$,${W_s}$是一个 256×128 维度的矩阵,所以${W_s}{a^{[l]}}$ 的维度是 256,这个新增项是 256 维度的向量。你不需要对${W_s}$做任何操作,它是网络通过学习得到的矩阵或参数,它是一个固定矩阵, padding 值为 0,用 0 填充${a^{[l]}}$ ,其维度为 256。
这是一个普通网络,我们给它输入一张图片,它有多个卷积层,最后输出了一个 Softmax。

如何把它转化为 ResNets 呢?只需要添加跳跃连接。这里我们只讨论几个细节,这个网络有很多层 3×3 卷积,而且它们大多都是 same 卷积,这就是添加等维特征向量的原因。所以这些都是卷积层,而不是全连接层,因为它们是 same 卷积,维度得以保留,这也解释了添加项:${{\rm{z}}^{[l + 2]}} + {{\rm{a}}^{[l]}}$ (维度相同所以能够相加)。
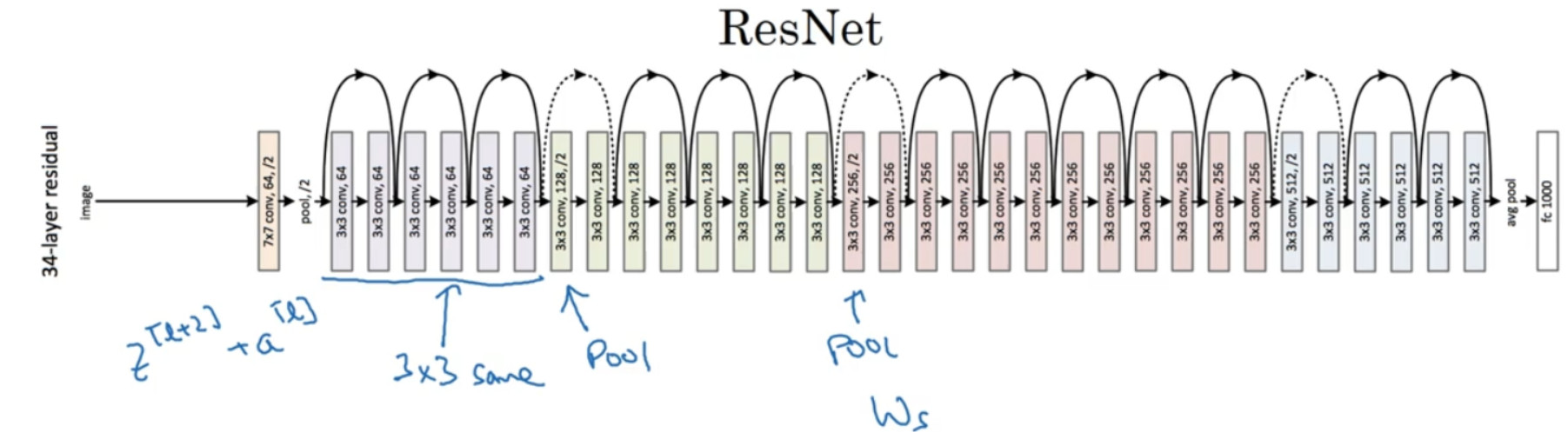
ResNets 类似于其它很多网络,也会有很多卷积层,其中偶尔会有池化层或类池化层的层。不论这些层是什么类型,你都需要调整矩阵${W_s}$的维度。普通网络和 ResNets 网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复。 直到最后, 有一个通过 softmax 进行预测的全连接层。

