2-2 清除标注错误的数据
清除标注错误的数据( Cleaning up Incorrectly labeled data)
你的监督学习问题的数据由输入x和输出标签y构成,如果你观察一下你的数据,并发现有些输出标签y是错的,这些输出标签y是错的,你的数据有些标签是错的。
在猫分类问题中,图片是猫,y=1,图片不是猫,y=0。下面列举的样本中发现倒数第二张图片其实不是猫,所以这是标记错误的样本。
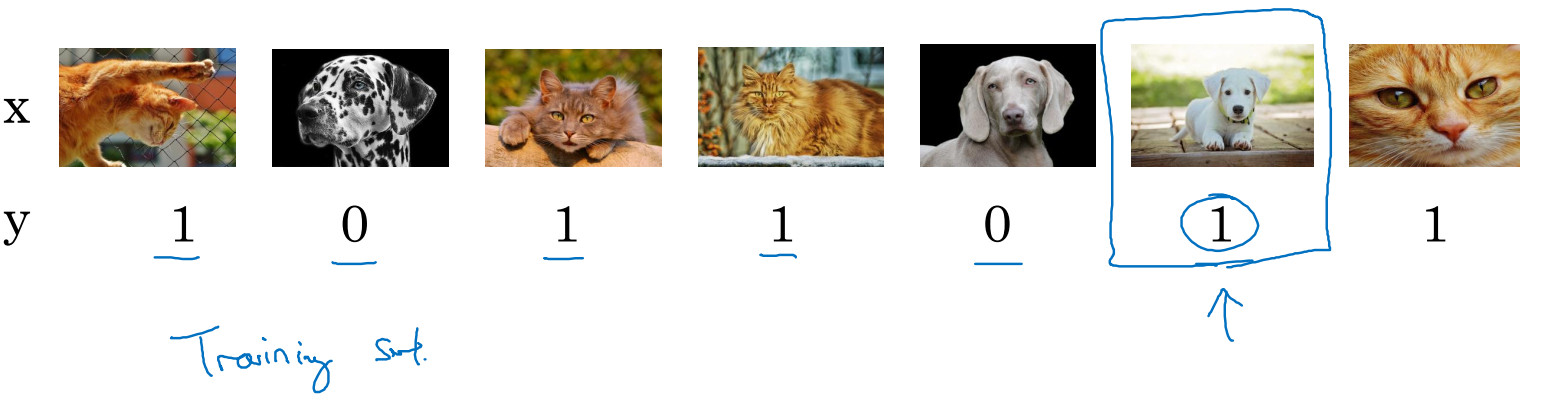
首先,我们来考虑训练集,事实证明,深度学习算法对于训练集中的随机错误是相当健壮的( robust)。有时可能做标记的人没有注意或者不小心,按错键了,如果错误足够随机,那么放着这些错误不管可能也没问题,而不要花太多时间修复它们。
当然你浏览一下训练集,检查一下这些标签,并修正它们也没什么害处。有时候修正这些错误是有价值的,有时候放着不管也可以,只要总数据集总足够大,实际错误率可能不会太高。我见过一大批机器学习算法训练的时候,明知训练集里有x个错误标签,但最后训练出来也没问题。
深度学习算法对随机误差很健壮,但对系统性的错误就没那么健壮了。所以比如说,如果做标记的人一直把白色的狗标记成猫,那就成问题了。因为你的分类器学习之后,会把所有白色的狗都分类为猫。但随机错误或近似随机错误,对于大多数深度学习算法来说不成问题。
如果你担心开发集或测试集上标记出错的样本带来的影响,一般建议你在错误分析时,添加一个额外的列,这样你也可以统计标签 y = 1错误的样本数。所以比如说,也许你统计一下对 100 个标记出错的样本的影响,所以你会找到 100 个样本,其中你的分类器的输出和开发集的标签不一致,有时对于其中的少数样本,你的分类器输出和标签不同,是因为标签错了,而不是你的分类器出错。之后可以统计因为标签错误所占的百分比。例如,分析总结如下:

所以现在问题是,是否值得修正这 6%标记出错的样本,我的建议是,如果这些标记错误严重影响了你在开发集上评估算法的能力,那么就应该去花时间修正错误的标签。但是,如果它们没有严重影响到你用开发集评估成本偏差的能力,那么可能就不应该花宝贵的时间去处理。

首先观察整体的开发集错误率也许我们的系统达到了 90%整体准确度,所以有 10%错误率,那么你应该看看错误标记引起的错误的数量或者百分比。所以在这种情况下, 6%的错误来自标记出错,所以10%的6%就是0.6%。也许你应该看看其他原因导致的错误,如果你的开发集上有 10%错误,其中 0.6%是因为标记出错,剩下的占 9.4%,是其他原因导致的,比如把狗误认为猫,大猫图片。所以在这种情况下,我说有 9.4%错误率需要集中精力修正,而标记出错导致的错误是总体错误的一小部分而已,所以如果你一定要这么做,你也可以手工修正各种错误标签,但也许这不是当下最重要的任务。
我们再看另一个样本,假设你在学习问题上取得了很大进展,所以现在错误率不再是 10%了,假设你把错误率降到了 2%,但总体错误中的 0.6%还是标记出错导致的。所以现在,如果你想检查一组标记出错的开发集图片,开发集数据有 2%标记错误了,那么其中很大一部分, 0.6%除以 2%,实际上变成 30%标签而不是 6%标签了。有那么多错误样本其实是因为标记出错导致的,所以现在其他原因导致的错误是 1.4%。当测得的那么大一部分的错误都是开发集标记出错导致的,那似乎修正开发集里的错误标签似乎更有价值。
如果你还记得设立开发集的目标的话,开发集的主要目的是,你希望用它来从两个分类器A和B中选择一个。所以当你测试两个分类器和时,在开发集上一个有 2.1%错误率,另一个有 1.9%错误率,但是你不能再信任开发集了,因为它无法告诉你这个分类器是否比这个好,因为 0.6%的错误率是标记出错导致的。
开发和测试集必须来自相同的分布。开发集确定了你的目标,当你击中目标后,你希望算法能够推广到测试集上,这样你的团队能够更高效的在来自同一分布的开发集和测试集上迭代。如果你打算修正开发集上的部分数据,那么最好也对测试集做同样的修正以确保它们继续来自相同的分布。
其次,我强烈建议你要考虑同时检验算法判断正确和判断错误的样本,要检查算法出错的样本很容易,只需要看看那些样本是否需要修正,但还有可能有些样本算法判断正确,那些也需要修正。如果你只修正算法出错的样本,你对算法的偏差估计可能会变大,这会让你的算法有一点不公平的优势,我们就需要再次检查出错的样本,但也需要再次检查做对的样本,因为算法有可能因为运气好把某个东西判断对了。在那个特例里,修正那些标签可能会让算法从判断对变成判断错。这第二点不是很容易做,所以通常不会这么做。通常不会这么做的原因是,如果你的分类器很准确,那么判断错的次数比判断正确的次数要少得多。那么就有 2%出错, 98%都是对的,所以更容易检查 2%数据上的标签,然而检查 98%数据上的标签要花的时间长得多,所以通常不这么做,但也是要考虑到的。
最后,你可能决定只修正开发集和测试集中的标签,因为它们通常比训练集小得多,你可能不想把所有额外的精力投入到修正大得多的训练集中的标签,所以这样其实是可以的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号