1-7 可避免偏差
可避免偏差( Avoidable bias)
你得知道人类水平的表现是怎样的,可以确切告诉你算法在训练集上的表现到底应该有多好,或者有多不好。

我们经常使用猫分类器来做例子,比如人类具有近乎完美的准确度,所以人类水平的错误是 1%。在这种情况下,如果您的学习算法达到 8%的训练错误率和 10%的开发错误率,那么你也许想在训练集上得到更好的结果。所以事实上,你的算法在训练集上的表现和人类水平的表现有很大差距的话,说明你的算法对训练集的拟合并不好。所以从减少偏差和方差的工具这个角度看,在这种情况下,我会把重点放在减少偏差上。你需要做的是,比如说训练更大的神经网络,或者跑久一点梯度下降,就试试能不能在训练集上做得更好。

假设人类水平错误实际上是 7.5%,也许你的数据集中的图像非常模糊,即使人类都无法判断这张照片中有没有猫。这个例子可能稍微更复杂一些,因为人类其实很擅长看照片,分辨出照片里有没有猫。但就为了举这个例子,比如说你的数据集中的图像非常模糊,分辨率很低,即使人类错误率也达到 7.5%。在这种情况下,即使你的训练错误率和开发错误率和其他例子里一样,你就知道,也许你的系统在训练集上的表现还好,它只是比人类的表现差一点点。在第二个例子中,你可能希望专注减少这个分量,减少学习算法的方差,也许你可以试试正则化,让你的开发错误率更接近你的训练错误率。
所以在之前的课程关于偏差和方差的讨论中,我们主要假设有一些任务的贝叶斯错误率几乎为 0。所以要解释这里发生的事情,看看这个猫分类器,用人类水平的错误率估计或代替贝叶斯错误率或贝叶斯最优错误率,对于计算机视觉任务而言,这样替代相当合理,因为人类实际上是非常擅长计算机视觉任务的,所以人类能做到的水平和贝叶斯错误率相差不远。根据定义,人类水平错误率比贝叶斯错误率高一点,因为贝叶斯错误率是理论上限,但人类水平错误率离贝叶斯错误率不会太远。所以这里比较意外的是取决于人类水平错误率有多少,或者这真的就很接近贝叶斯错误率,所以我们假设它就是,但取决于我们认为什么样的水平是可以实现的。
所以在之前的课程关于偏差和方差的讨论中,我们主要假设有一些任务的贝叶斯错误率几乎为 0。所以要解释这里发生的事情,看看这个猫分类器,用人类水平的错误率估计或代替贝叶斯错误率或贝叶斯最优错误率,对于计算机视觉任务而言,这样替代相当合理,因为人类实际上是非常擅长计算机视觉任务的,所以人类能做到的水平和贝叶斯错误率相差不远。根据定义,人类水平错误率比贝叶斯错误率高一点,因为贝叶斯错误率是理论上限,但人类水平错误率离贝叶斯错误率不会太远。所以这里比较意外的是取决于人类水平错误率有多少,或者这真的就很接近贝叶斯错误率,所以我们假设它就是,但取决于我们认为什么样的水平是可以实现的。

在这两种情况下,具有同样的训练错误率和开发错误率,我们决定专注于减少偏差的策略或者减少方差的策略。那么左边的例子发生了什么? 8%的训练错误率真的很高,你认为你可以把它降到 1%, 那么减少偏差的手段可能有效。而在右边的例子中,如果你认为贝叶斯错误率是 7.5%,这里我们使用人类水平错误率来替代贝叶斯错误率,但是你认为贝叶斯错误率接近 7.5%,你就知道没有太多改善的空间了,不能继续减少你的训练错误率了,你也不会希望它比 7.5%好得多,因为这种目标只能通过可能需要提供更进一步的训练。而这边,就还(训练误差和开发误差之间)有更多的改进空间,可以将这个 2%的差距缩小一点,使用减少方差的手段应该可行,比如正则化,或者收集更多的训练数据。
所以要给这些概念命名一下,这不是广泛使用的术语,就是把这个差值,贝叶斯错误率或者对贝叶斯错误率的估计和训练错误率之间的差值称为可避免偏差,你可能希望一直提高训练集表现,直到你接近贝叶斯错误率,但实际上你也不希望做到比贝叶斯错误率更好,这理论上是不可能超过贝叶斯错误率的,除非过拟合。而这个训练错误率和开发错误率之前的差值,就大概说明你的算法在方差问题上还有多少改善空间。
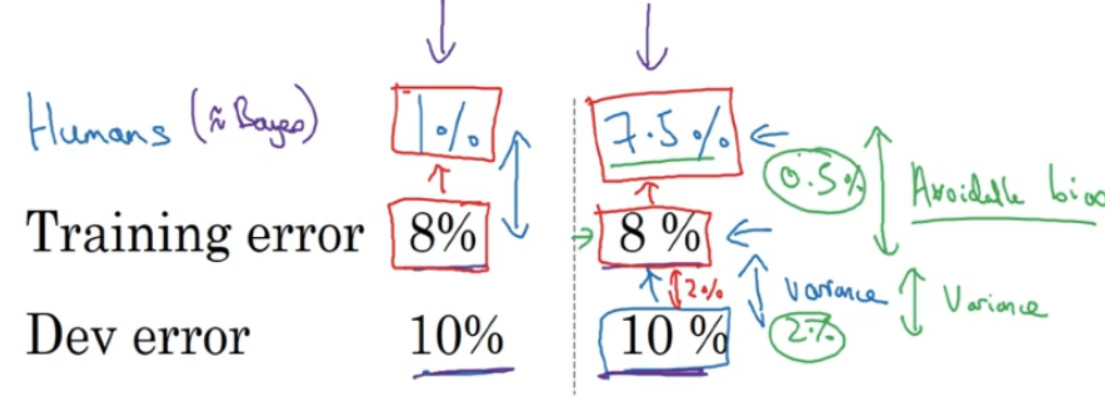
可避免偏差这个词说明了有一些别的偏差,或者错误率有个无法超越的最低水平,那就是说如果贝叶斯错误率是 7.5%。你实际上并不想得到低于该级别的错误率,所以你不会说你的训练错误率是 8%,然后 8%就衡量了例子中的偏差大小。你应该说,可避免偏差可能在0.5%左右,或者 0.5%是可避免偏差的指标。而这个 2%是方差的指标,所以要减少这个 2%比减少这个 0.5%空间要大得多。而在左边的例子中,这 7%衡量了可避免偏差大小,而 2%衡量了方差大小。所以在左边这个例子里,专注减少可避免偏差可能潜力更大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号