3-4 归一化网络的激活函数
归一化网络的激活函数( Normalizing activations in a network)
在深度学习兴起后,最重要的一个思想是它的一种算法,叫做 Batch 归一化。Batch 归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会是你的训练更加容易,甚至是深层网络。
当训练一个模型,比如 logistic 回归时,你也许会记得,归一化输入特征可以加快学习过程。你计算了平均值,从训练集中减去平均值,计算了方差,接着根据方差归一化你的数据集,在之前的视频中我们看到,这是如何把学习问题的轮廓,从很长的东西,变成更圆的东西,更易于算法优化。所以这是有效的,对 logistic 回归和神经网络的归一化输入特征值而言。
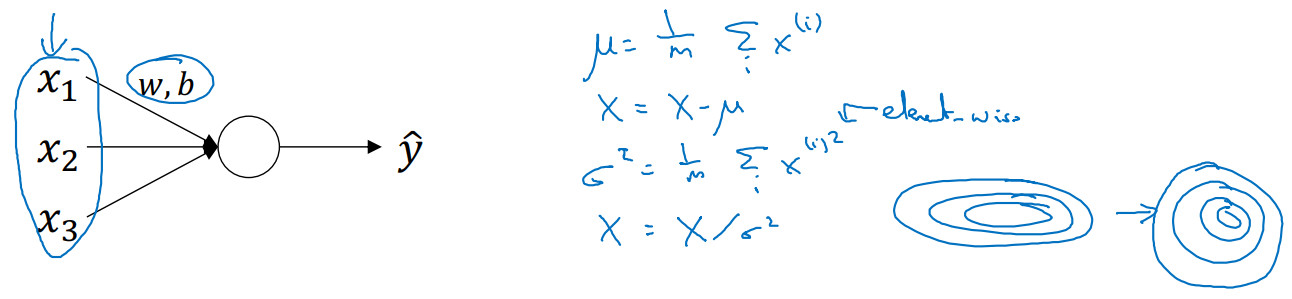
那么更深的模型呢?你不仅输入了特征值x,而且这层有激活值a。所以问题来了,对任何一个隐藏层而言,我们能否归一化a值,以更快的速度训练参数。例如归一化${{\rm{a}}^{[2]}}$,以便更快的训练参数${W^{[3]}}$,${b^{[3]}}$。因为${{\rm{a}}^{[2]}}$ 是下一层的输入值,所以就会影响${W^{[3]}}$,${b^{[3]}}$ 的训练。简单来说,这就是 Batch 归一化的作用。尽管严格来说,我们真正归一化的不是${{\rm{a}}^{[2]}}$ ,而是${{\rm{z}}^{[2]}}$ ,深度学习文献中有一些争论,关于在激活函数之前是否应该将值${{\rm{z}}^{[2]}}$ 归一化,或是否应该在应用激活函数${{\rm{a}}^{[2]}}$ 后再规范值。实践中,经常做的是归一化${{\rm{z}}^{[2]}}$。
在神经网络中,已知一些中间值,假设你有一些隐藏单元值从${z^{[1]}}$到${z^{[m]}}$,这些来源于隐藏层,所以这样写会更准确,即${z^{[l]}}^{(i)}$ 为隐藏层,i从1到m,但这样书写,我要省略l及方括号,以便简化这一行的符号。所以已知这些值,如下,你要计算平均值,强调一下,所有这些都是针对l层,但我省略l及方括号,计算方法如下:
$\mu = \frac{1}{m}\sum\limits_i {{z^{(i)}}} $
${\delta ^2} = \frac{1}{m}\sum\limits_i {({z^{(i)}}} - \mu {)^2}$
$z_{norm}^{(i)} = \frac{{{z^{(i)}} - \mu }}{{\sqrt {{\delta ^2} + \varepsilon } }}$
分母中加上$\varepsilon$以防止$\delta$为0的情况。
所以现在我们已把这些z值标准化,化为含平均值 0 和标准单位方差,所以z的每一个分量都含有平均值 0 和方差 1,但我们不想让隐藏单元总是含有平均值 0 和方差 1,也许隐藏单元有了不同的分布会有意义,所以我们所要做的就是计算,我们称之为${{\tilde z}^{(i)}}$:
${{\tilde z}^{(i)}} = \gamma z_{norm}^{(i)} + \beta$
这里$\gamma$和$\beta$是你模型的学习参数,所以我们使用梯度下降或一些其它类似梯度下降的算法,比如 Momentum 或者 Nesterov, Adam,你会更新$\gamma$和$\beta$,正如更新神经网络的权重一样。
$\gamma$和$\beta$的作用是你可以随意设置${{\tilde z}^{(i)}}$ 的平均值,事实上,如果:
$\gamma = \sqrt {{\delta ^2} + \varepsilon }$
$\beta = \mu $
那么:
${{\tilde z}^{(i)}} = \gamma z_{norm}^{(i)} + \beta = \sqrt {{\delta ^2} + \varepsilon } *\frac{{{z^{(i)}} - \mu }}{{\sqrt {{\delta ^2} + \varepsilon } }} + \mu = {z^{(i)}}$
Batch 归一化的作用是它适用的归一化过程,不只是输入层,甚至同样适用于神经网络中的深度隐藏层。你应用 Batch 归一化了一些隐藏单元值中的平均值和方差,不过训练输入和这些隐藏单元值的一个区别是,你也许不想隐藏单元值必须是平均值 0 和方差 1。$\gamma$和$\beta$参数控制使得均值和方差可以是 0 和 1,也可以是其它值。

