1-11 神经网络的权重初始化
神经网络的权重初始化( Weight Initialization for Deep NetworksVanishing / Exploding gradients)
理想的权重矩阵既不会增长过快,也不会太快下降到 0,从而训练出一个权重或梯度不会增长或消失过快的深度网络。
有一个神经元的情况 :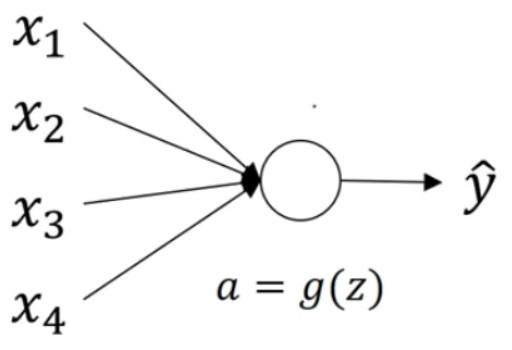
暂时忽略b:
$z = {w_1}{x_1} + {w_2}{x_2} + ... + {w_n}{x_n}$为了预防 z值过大或过小,你可以看到
n越大,你希望${w_i}$越小,因为 z是${w_i}{x_i}$的和如果你把很多此类项相加,希望每项值更小,最合理的方法就是设置
${w_i} = \frac{1}{n}$,n表示神经元的输入特征数量,实际上,你要做的就是设置某层权重矩阵: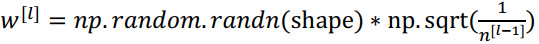
${n^{[l - 1]}}$就是我喂给第l层神经单元的数量(即第l-1层神经元数量)。
如果激活函数的输入特征被零均值和标准方差化,方差是 1, z也会调整到相似范围,这就没解决问题(梯度消失和爆炸问题)。
因为它给权重矩阵 w设置了合理值,你也知道,它不能比 1 大很多,也不能比 1 小很多,所以梯度没有爆炸或消失过快。
如果你想用 Relu 激活函数,使用如下公式:

如果使用 tanh 函数 ,使用如下公式:
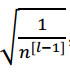
所有这些公式只是给你一个起点,它们给出初始化权重矩阵的方差的默认值,如果你想添加方差,方差参数则是另一个你需要调整的超级参数
,例如给公式

增加一个乘性系数,进行调优。
有时调优该超级参数效果一般,这并不是我想调优的首要超级参数,但我发现调优过程中产生的问题,虽然调优该参数能起到一定作用,但考虑到相比调优,其它超级参数的重要性,我通常把它的优先级放得比较低。

