1-5 为什么正则化有利于预防过拟合呢?
为什么正则化有利于预防过拟合呢?( Why regularization reduces overfitting?)
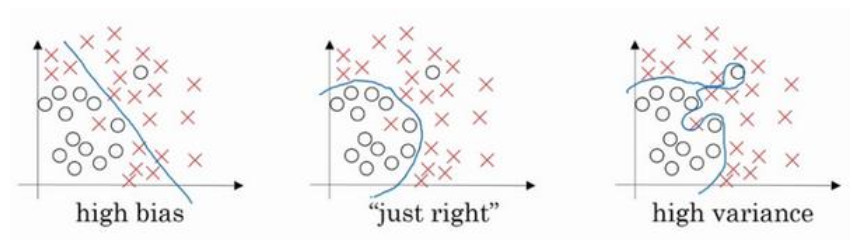
左图是高偏差,右图是高方差,中间是 Just Right。
我们假设下面的网络是一个过拟合的网络,我们添加正则项,可以避免数据权值矩阵过大,这就是弗罗贝尼乌斯范数。那么为什么弗罗贝尼乌斯范数可以减少过拟合呢?
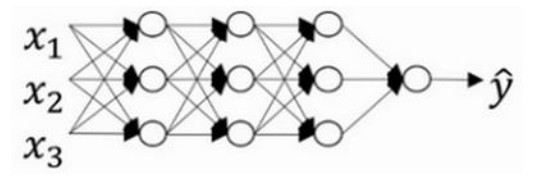

直观上理解就是如果正则化$\lambda$设置得足够大,权重矩阵W被设置为接近于0的值,就是把多隐藏单元的权重设为 0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。但是$\lambda$会存在一个中间值, 于是会有一个接近“Just Right”的中间状态。
直观上理解就是如果正则化$\lambda$设置得足够大,权重矩阵W被设置为接近于0的值。实际上是不会发生这种情况的,我们尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,我们直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合。

