3-8 随机初始化
随机初始化( Random Initialization)
对于逻辑回归,把权重初始化为 0当然也是可以的。但是对于一个神经网络,如果你把权重或者参数都初始化为 0,那么梯度下降将不会起作用。
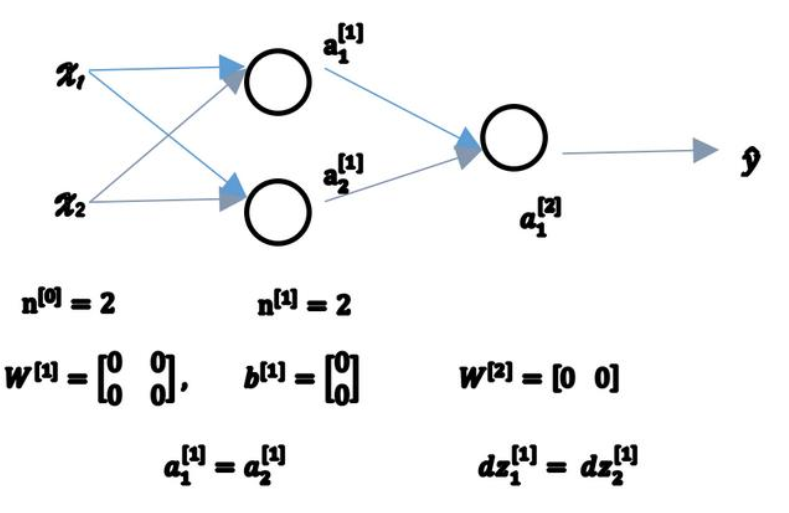
如上图所示的神经网络以及初始化方式,其结果$a_1^{[1]} = a_2^{[1]}$,反向传播时:$dz_1^{[1]} = dz_2^{[1]}$。
如果你把权重都初始化为 0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管你训练网络多长时间,隐含单元仍然计算的是同样的函数。 因此这种情况下超过 1 个隐含单元也没什么意义,因为他们计算同样的东西。
解决这个问题的办法就是随机初始化参数,通常随机初始化后还会乘一个小数,如0.01,这样就可以把它初始化为很小的随机数。b没有这种对称问题,因而可以将b初始化为0。
由此,初始化方式可以总结为:

这里取0.01而不是100,1000,是因为我们通常更倾向于初始化为很小的随机数,如果使用tanh或者sigmoid激活函数,当计算z时,如果W的值很大,z就会很大,在这种情况下就会导致梯度下降缓慢,学习慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号