数据仓库中的Inmon与Kimball架构
对于数据仓库体系结构的最佳问题,始终存在许多不同的看法,甚至有人把Inmon和Kimball之争称之为数据仓库界的“宗教战争”,那么本文就通过对两位提倡的数据仓库体系和市场流行的另一种体系做简单描述和比较,不是为了下定义那个好,那个不好,而是让初学者更明白两位数据仓库鼻祖对数据仓库体系的见解而已。
首先,我们谈Inmon的企业信息化工厂。
2000年5月,W.H.Inmon在DM Review杂志上发表一篇文章,里面写到一句话“……如果明天非得设计一个数据集市,我将不考虑使用其他的方法”;正是揭示了他的企业信息化工厂的特点。下图是关于他的企业信息化工厂的架构图: 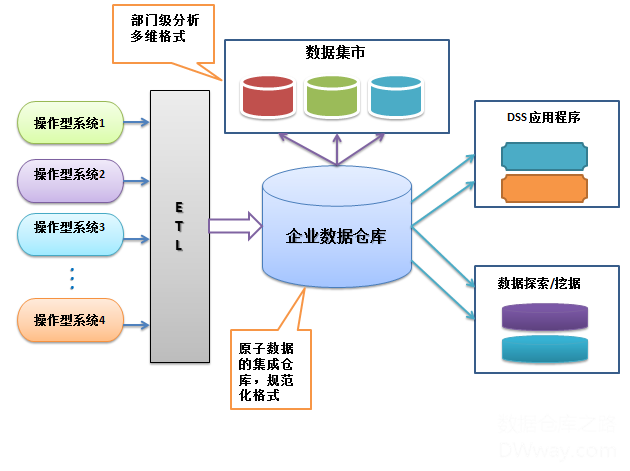
我们理解一下这个体系架构,左边是操作型系统或者事务系统,里面包括很多种系统,有数据库在线系统,有文本文件系统…等等。而这些系统的数据经过ETL的过程,加载数据到企业数据仓库中,ETL的过程是整合不同系统的数据,经过整合,清洗和统一,因此我们可以称之为数据集成。
企业数据仓库是企业信息化工厂的枢纽,是原子数据的集成仓库,但是由于企业数据仓库不是多维格式,因此不适合分析型应用程序,BI工具直接查询。他的目的是将附加的数据存储用于各种分析型系统。
数据集市,是针对不同的主题区域,从企业数据仓库中获取的信息,转换成多维格式,然后通过不同手段的聚集、计算,最后提供最终用户分析使用,因此Inmon把信息从企业数据仓库移动到数据集市的过程描述为“数据交付”。
接下来我们来看Kimball的维度数据仓库:
kimball的维度数据仓库是基于维度模型建立的企业级数据仓库,它的架构有的时候可以称之为“总线体系结构”,和inmon提出的企业信息化工厂有很多相似之处,都是考虑原子数据的集成仓库;我们来根据下面的架构来分析他的观点: 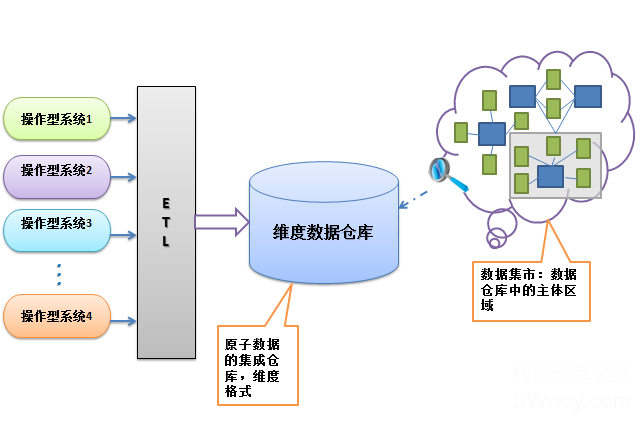
虽然初看两个图有很多不一样的地方,但是这两种结构有很多相似之处:一,都是假设操作型系统和分析型系统是分离的;二,数据源(操作型系统)都是众多;三,ETL整合了多种操作型系统的信息,集中到一个企业数据仓库。
当然如果去区别他们的不同,最大的不同就是企业数据仓库的模式不同,inmon是采用第三范式的格式,而kimball则采用了多维模型–星型模型,并且还是最低粒度的数据存储。其次是,维度数据仓库可以被分析系统直接访问,当然这种访问方式毕竟在分析过程中很少使用。最后就是数据集市的概念有逻辑上的区别,在kimball的架构中,数据集市有维度数据仓库的高亮显示的表的子集来表示。
当然有的时候,在kimball的架构中,有一个可变通的设计,就是在ETL的过程中加入ODS层,使得ODS层中能保留第三范式的一组表来作为ETL过程的过度。但是这个思想,Kimball看来只是ETL的过程辅助而已。另外,还可以把数据集市和企业维度数据仓库分离开来,这样多一层所谓的展现层(presentationlayer),这些变通的设计都是可以接受的,只要符合企业本身分析的需求。
最后一种是独立型数据集市,来自市场的实施过程被广泛使用,下面是独立型数据集市的架构:特点是非常简单,容易实现,而且实施时间段。但是最大的问题是,由于快速的实施,廉价的过程,导致长期费用的提供和效率的低下。 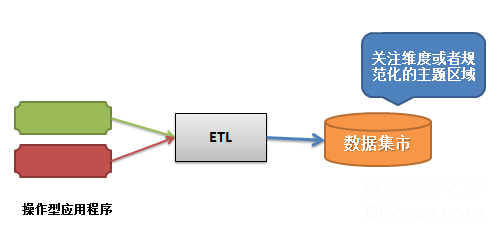
开发一个独立的数据集市是获得可见结果的最有效的方法,因为不需要做跨部门,跨功能的分析,并且数据集市可以很快投入到生产中,因此能够迅速和廉价地获得结果,所以很多机构应用这种方法。而且很多ERP集成商的系统中也自带了类似的功能作为一个卖点来吸引客户。虽然它有很多有点,但是最致命的缺点,短期的成功却带来长期的棘手问题。特别是独立型数据集市支持多主题区域时,会导致多个部门数据不一致,就是数据打架的现象。并且使得各个数据集市成为信息孤岛,缺乏兼容性。因此这种方案很多时候是不可接受的。
通过本文的简要的介绍3种体系结构,希望能帮助你准确的理解数据仓库的体系结构和实施方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号