

hive数据倾斜处理
Hive数据倾斜原因和解决办法(Data Skew)
什么是数据倾斜(Data Skew)?
数据倾斜是指在原本应该并行处理的数据集中,某一部分的数据显著多于其它部分,从而使得该部分数据的处理速度成为整个数据集处理的瓶颈。
假设数据分布不均匀,某个key对应几十万条数据,其他key对应几百条或几十条数据,那么在处理数据的时候,大量相同的key会被分配(partition)到同一个分区里,造成"一个人累死,其他人闲死“的情况,具体表现在:有些任务很快就处理完了,而有些任务则迟迟未能处理完,导致整体任务最终耗时过长甚至是无法完成。
数据倾斜分为map端倾斜和reduce端倾斜。
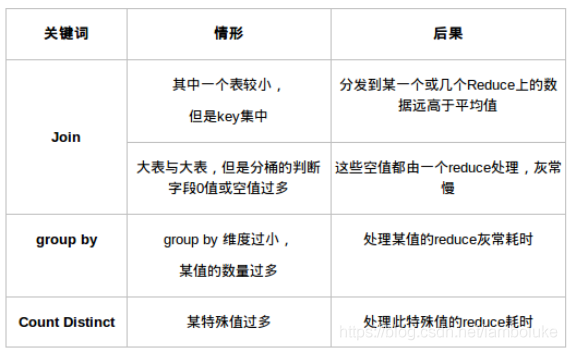
1.1 操作:
1.2 原因:
1)、key分布不均匀
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
1.3 表现:
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
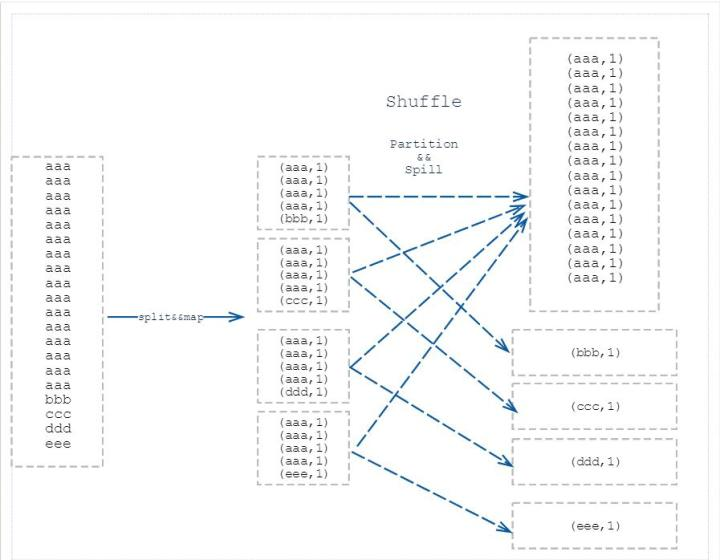
要真正了解数据倾斜,需要知道MapReduce的工作原理。(以下摘自:https://www.zhihu.com/question/27593027)
举个 word count 的入门例子,它的map 阶段就是形成 (“aaa”,1)的形式,然后在reduce 阶段进行 value 相加,得出 “aaa” 出现的次数。若进行 word count 的文本有100G,其中 80G 全部是 “aaa” ,剩下 20G 是其余单词,那就会形成 80G 的数据量交给同一个 reduce 进行相加,其余 20G 根据分配到不同 reduce 进行相加的情况。如此就造成了数据倾斜,临床反应就是 reduce 跑到 99%,然后一直在原地等着那80G 的reduce 跑完。
2、数据倾斜的解决方案
2.1 参数调节:
hive.map.aggr=true
Map 端部分聚合,相当于Combiner
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
2.2 SQL语句调节:
如何Join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表。
做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
当出现小文件过多,需要合并小文件。可以通过set hive.merge.mapfiles=true来解决。
大小表Join:
解决方法:小表在join左侧,大表在右侧,或使用mapjoin 将小表加载到内存中。然后再对比较大的表进行map操作。
大表Join大表
遇到需要进行join的但是关联字段有数据为null,如表一的id需要和表二的id进行关联,null值的reduce就会落到一个节点上
解决方法1:子查询中过滤掉null值,id为空的不参与关联
解决方法2:用case when给空值分配随机的key值(字符串+rand())
count (distinct)大量相同特殊值
如果数据量非常大,执行如select a,count(distinct b) from t group by a;类型的SQL时,会出现数据倾斜的问题。
解决方法:使用sum()…group by代替。如select a,sum(1) from (select a, b from t group by a,b) group by a;
如果还有其他计算,如需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
实例:
场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的user_id 关联,会碰到数据倾斜的问题。
解决方法1: user_id为空的不参与关联
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all
select * from log a
where a.user_id is null;
解决方法2 :赋与空值分新的key值
select *
from log a
left outer join users b
on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
结论:方法2比方法1效率更好,不但io少了,而且作业数也少了。解决方法1中 log读取两次,jobs是2。解决方法2 job数是1 。这个优化适合无效 id (比如 -99 , ’’, null 等) 产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
实例:
不同数据类型关联产生数据倾斜:
场景:用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时,默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分配到一个Reducer中。
解决方法:把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string)下面是另一种总结方法:
数据倾斜产生的原因:
1,map端:输入文件的大小不均匀
2,reduce端:key分布不均匀,导致partition不均匀
数据倾斜的解决办法:
1,当出现小文件过多时:合并小文件
可以通过set hive.merge.mapfiles=true来解决。
2,当group by分组的维度过少,每个维度的值过多时:调优参数
(1)设置在map阶段做部分聚合操作
hive.map.aggr=true
效率更高但需要更多的内存。
(2)设置数据倾斜时负载均衡
hive.groupby.skewindata=true
当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
起至关作用的是第(2)项,它分为了两个mapreduce,第一个在shuffle过程中partition时随机给key打标记,使其分布在不同的reduce上计算,但不能完成全部运算,所以需要第二次mapreduce整合回归正常的shuffle,由于数据分布不均问题在第一次时得到改善,所以基本解决数据倾斜问题。
3,调节SQL语句
(1)关联字段带空值的两表Join时:把空值的key变成一个字符串加上随机数,这样就可以把倾斜的数据分到不同的reduce上,此外由于空值关联不起来,所以处理后并不影响最终结果。
(2)大小表Join时:使用map join让小表(1000条以下的记录条数) 先进内存,在map端完成reduce。
在 hive 中,能够在 HQL 语句中直接指定该次查询使用map join,具体做法是:在查询/子查询的SELECT关键字后面添加/*+ MAPJOIN(tablelist) */,提示优化器转化为map join(早期的 Hive 版本的优化器是不能自动优化 map join 的)。
select /* +mapjoin(movies) */ a.title, b.rating from movies a join ratings b on a.movieid = b.movieid;
在 hive0.11 版本以后会自动开启 map join 优化,由两个参数控制:
set hive.auto.convert.join=true; //设置 MapJoin 优化自动开启
set hive.mapjoin.smalltable.filesize=25000000 //设置小表不超过多大时开启 mapjoin 优化
(3)大表Join大表时:把大表切分成小表,然后分别map join。
(4)count(distinct xx)时有大量相同的特殊值:用sum() group by的方式来替换count(distinct)完成计算。如:如select a,count(distinct b) from t group by a,用select a,sum(1) from (select a,b from t group by a,b) group by a替代。
(5)其他情况:如果倾斜的key数量比较少,那么将倾斜的数据单独拿出来处理,最后union回去;如果倾斜的key数量比较多,那么给key增加随机前/后缀,使得原来Key相同的数据变为Key不相同的数据,从而使倾斜的数据集分散到不同的任务中,在Join的另一侧数据中,将与倾斜Key对应的部分数据和随机前/后缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜Key如何加前缀,都能与之正常Join。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2017-01-15 db2数据类型