
素数问题
素数问题
问题描述:
现在给你一个正整数N,要你快速的找出在2.....N这些数里面所有的素数。
输入:
给出一个正整数数N(N<=2000000)、但N为0时结束程序。、测试数据不超过100组
输出:
将2~N范围内所有的素数输出。两个数之间用空格隔开
一般实现:
代码:
#include <stdio.h> #include <malloc.h> void printPrimeNum(int n) { int i, j; int isPrimeNum = 1; for(i=2;i<=n;i++) { for(j=2;j<i;j++) { if((i%j) == 0) { isPrimeNum = 0; break; } else { isPrimeNum = 1; } } if(isPrimeNum) { printf("%d ", i); } } } int main() { int N; scanf("%d%*c", &N); if(N==0) { return 0; } printPrimeNum(N); return 0; }
素数筛法和改进的素数筛法
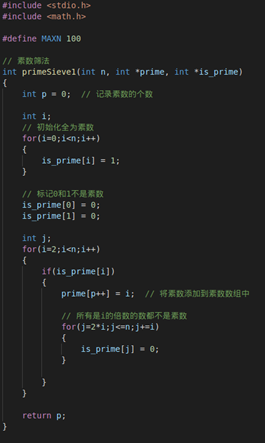
素数筛法:
这种素数的判断方法的确直观,但这种算法只对较小数据量适用,当数据量较大时,该方法就不再适用于素数的判定了。因此,我们此处引入一种新的算法——素数筛法。
首先介绍一下什么叫素数筛法:
假设所有待判断的数字的上限是L,声明一个长度为L+1的布尔数组A[L+1]。用这个数组来表示对应下标的数字是不是素数。起初,将数组所有成员标记为1,然后按照某种方法将其中的非素数都标记为0即可,完成后的数组有这样的特征:所有素数为下标的成员内存的数字都是1,所有非素数为下标的成员内存的数字都是0。例如 :2 是素数,那么A[2]=1;4不是素数,那么A[4]=0。因此,我们获取了一个素数表。这样,判断一个数是不是素数,直接查找即可。这样,我们在使用素数的时候就无需再进行素数的判断,这将大大缩短程序的运行时间,虽然我们需要提前计算素数表,但这相比较于用的时候再进行素数的判定,无疑是一个巨大的进步。下面介绍如何进行素数的标记:
这个标记的方法是这样的:1不是质数,也不是合数,标记0。第二个数2是质数标记为1,而把2后面所有能被2整除的数都标记为0。2后面第一个没划去的数是3,把3标记为1,再把3后面所有能被3整除的数都标记为0。3后面第一个没划去的数是5,把5标记为1,再把5后面所有能被5整除的数都标记为0。这样一直做下去,就会把不超过N的全部合数都标记为0,留下的就是不超过N的全部质数。因为希腊人是把数写在涂腊的板上,每要划去一个数,就在上面记以小点,寻求质数的工作完毕后,这许多小点就像一个筛子,所以就把埃拉托斯特尼的方法叫做“埃拉托斯特尼筛法”,简称“筛法”。
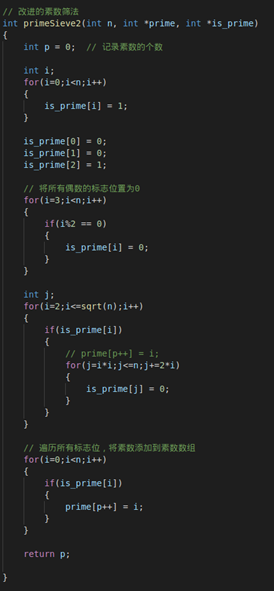
改进的素数筛法:
当然这个方法已经有很大的改进了,但是仍然存在会有重复筛掉某一合数,增加无用计算的现象,例如,删3的倍数时15标记为0,删15的倍数时,同样再一次将15标记为0。这还不够精简,因此有人将这个方法进行了改进:
首先初始A[1]=0,A[2]=1;
其次,将所有偶数下标的成员全部置为0,
接下来求出 t=√A
接下来从i=3开始到i=t开始当A[i]=1时进行下列操作
{
从 j=i*i 开始,到 j=L 结束,每次 j 加 2*i 让A[j]=0
}
改进原理如下:
将1和2进行初始化很容易理解
接着是将所有的偶数标记为0,这也很好理解,因为除了2之外所有的偶数都不是素数,这样一来,数据处理量直接缩小一半,爽!!!!
接下来就是问题的关键了,也是比较难理解的一部分,为什么再循环判断的时候到√A 就结束了哪?我们是这样解释的,因为在内部循环中我们是让 j 从i * i 开始循环的,如果 i > √A ,呢么我们一定可以保证 i * i 是大于 L 的,所有就没有必要再继续循环了。内循环的处理原理是这样的:实际上我们处理的是 i 的倍数是不是素数的问题.
为什么 i 从3 开始 到 t 便可以结束呢?原因是循环之内(黄色字体)的 j 每次是以 i * i 为初始值进行判断的, 如果 i > t ,那么 i * i 一定 大于 L,所以 就没必要进行 t 之后的循环了。只判断 A[ i ]= 1(即 A[ i ]是奇数)的情况,原因是 循环之内的处理,实际上处理的是 i 的倍数是不是素数的问题,大家都清楚,不仅 2 的所有倍数是偶数,所有偶数的倍数都是偶数。
在解释循环之内(黄色字体)的内容,有人很好奇,为什么不用考虑 i *3 到 i *( i-1)之间的数呢,那么假设 有一个数 p 介于 3 和( i - 1)之间, 显然 ,如果 i * p 是小于 L 范围之内的数, 在 i = p
的时候,就应该判断过这个数了。
j = i * i 是非素数,这个就很明显了。
至于为什么 j 每次的增量是 2 * i ,而不是 i 呢?因为奇数个奇数相加一定是奇数,偶数个奇数相加一定是偶数。首先我们已经在判断时保证 i 是 奇数,那么 i 个i 相加就可以表示为 i * i,如果增量是 i 且 i * i
是奇数的话,i * i +i 必定是偶数, i*i+2i 才是奇数,也就说增量是 i 的时候,每两次循环中,有一次 就判断偶数(偶数之前已经被排除过了),这样岂不是违背了要提高效率的初衷?因此,在当前循环中需
要处理的只是 奇数且是非素数的情况。j =i * i+2i=i *( i + 2)显然也是非素数,以此类推 j = j +2*i 是非素数,直至该数超过上限结束本次循环。
这样就保证万无一失且不重复的排除所有情况啦。
好了直接上代码
代码:
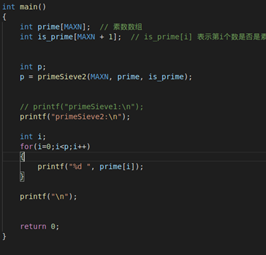
测试输出:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号