
CNN01:Pytorch实现LeNet的Mnist手写数字识别
CNN01:Pytorch实现LeNet的Mnist手写数字识别
1、LeNet的网络结构和原理
LeNet的具体网络结构和原理参考博客:
https://www.cnblogs.com/guoyaohua/p/8534077.html
该博客不只讲了LeNet还讲了其他的网络结构,比较详细,容易理解。
2、基于Pytorch的LeNet的MNIST手写数字识别Python代码实现
(1) 整体代码:
#__author__ = 'SherlockLiao'
import torch
from torch import nn, optim
#import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
#from logger import Logger
# 定义超参数
batch_size = 128 # 批的大小
learning_rate = 1e-2 # 学习率
num_epoches = 20 # 遍历训练集的次数
# 数据类型转换,转换成numpy类型
#def to_np(x):
# return x.cpu().data.numpy()
# 下载训练集 MNIST 手写数字训练集
train_dataset = datasets.MNIST(
root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(
root='./data', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义 Convolution Network 模型
class Cnn(nn.Module):
def __init__(self, in_dim, n_class):
super(Cnn, self).__init__() # super用法:Cnn继承父类nn.Model的属性,并用父类的方法初始化这些属性
self.conv = nn.Sequential( #padding=2保证输入输出尺寸相同(参数依次是:输入深度,输出深度,ksize,步长,填充)
nn.Conv2d(in_dim, 6, 5, stride=1, padding=2),
nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5, stride=1, padding=0),
nn.ReLU(True),
nn.MaxPool2d(2, 2))
self.fc = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84),
nn.Linear(84, n_class))
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
model = Cnn(1, 10) # 图片大小是28x28,输入深度是1,最终输出的10类
use_gpu = torch.cuda.is_available() # 判断是否有GPU加速
if use_gpu:
model = model.cuda()
# 定义loss和optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
#logger = Logger('./logs')
# 开始训练
for epoch in range(num_epoches):
print('epoch {}'.format(epoch + 1)) # .format为输出格式,formet括号里的即为左边花括号的输出
print('*' * 10)
running_loss = 0.0
running_acc = 0.0
for i, data in enumerate(train_loader, 1):
img, label = data
# cuda
if use_gpu:
img = img.cuda()
label = label.cuda()
img = Variable(img)
label = Variable(label)
# 向前传播
out = model(img)
loss = criterion(out, label)
running_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
accuracy = (pred == label).float().mean()
running_acc += num_correct.item()
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
"""
# ========================= Log ======================
step = epoch * len(train_loader) + i
# (1) Log the scalar values
info = {'loss': loss.data[0], 'accuracy': accuracy.data[0]}
for tag, value in info.items():
logger.scalar_summary(tag, value, step)
# (2) Log values and gradients of the parameters (histogram)
for tag, value in model.named_parameters():
tag = tag.replace('.', '/')
logger.histo_summary(tag, to_np(value), step)
logger.histo_summary(tag + '/grad', to_np(value.grad), step)
# (3) Log the images
info = {'images': to_np(img.view(-1, 28, 28)[:10])}
for tag, images in info.items():
logger.image_summary(tag, images, step)
if i % 300 == 0:
print('[{}/{}] Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, num_epoches, running_loss / (batch_size * i),
running_acc / (batch_size * i)))
"""
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(train_dataset))))
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
if use_gpu:
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
print()
# 保存模型
torch.save(model.state_dict(), './cnn.pth')
(2) 代码详解:
首先,该代码可以分为以下几个部分:
- 导入各种包
- 定义超参数
- 下载MNIST数据集
- 定义LeNet网络模型
- 定义损失函数loss和优化方式SGD
- 训练模型
1). 初始化loss和accuracy
2). 前向传播
3). 反向传播
4). 测试模型
5). 打印每个epoch的loss和acc - 保存模型
1、导包
import torch
from torch import nn, optim
#import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
#from logger import Logger
其中logger包是记录日志用的,并不需要
2、定义超参数
batch_size = 128 # 批的大小
learning_rate = 1e-2 # 学习率
num_epoches = 20 # 遍历训练集的次数
超参数有3个,分别是batch_size、learning_rate和mun_epoches:
batch_size(批大小):指将数据集分成n个batch(批),每一个batch的大小
learning_rate(学习率):训练时,每次更新的步长,不宜设置过大
mun_epoches(遍历数据集训练的次数):指遍历训练整个数据集的次数。
3、下载MNIST数据集
train_dataset = datasets.MNIST(
root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(
root='./data', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
Pytorch的torchvision.datasets包含MNIST、COCO、LSUN、ImageFolder、Imagenet-12、CIFAR、STL10等数据集。可以通过datasets.MNIST这种方式来下载调用这些数据集。
datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)参数说明:
root: processed/training.pt和 processed/test.pt的主目录。数据集下载和保存的地址。
train:train=True表示训练集,train=False表示测试集。
download:download=True表示从网上下载数据集,download=False表示数据已经下载过。
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False)
数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。
参数说明:
dataset (Dataset):加载数据的数据集。
batch_size (int, optional):每个batch加载多少个样本(默认: 1)。
shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据(默认: False).。
sampler (Sampler, optional):定义从数据集中提取样本的策略。如果指定,则忽略shuffle参数。
num_workers (int, optional):用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)。
collate_fn (callable, optional)
pin_memory (bool, optional)
drop_last (bool, optional):如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)。
4、定义LeNet网络模型
# 定义 Convolution Network 模型
class Cnn(nn.Module):
def __init__(self, in_dim, n_class):
super(Cnn, self).__init__() # super用法:Cnn继承父类nn.Model的属性,并用父类的方法初始化这些属性
self.conv = nn.Sequential( #padding=2保证输入输出尺寸相同(参数依次是:输入深度,输出深度,ksize,步长,填充)
nn.Conv2d(in_dim, 6, 5, stride=1, padding=2),
nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5, stride=1, padding=0),
nn.ReLU(True),
nn.MaxPool2d(2, 2))
self.fc = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84),
nn.Linear(84, n_class))
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
(1) superd的用法:Cnn继承父类nn.Model的属性,并用父类的方法初始化这些属性
(2) nn.Sequential():一个时序容器。Modules 会以他们传入的顺序被添加到容器中。这个容器里可以初始化卷积层、激活层和池化层。
nn.Conv2d(in_dim, 6, 5, stride=1, padding=2):初始化卷积层1
in_dim:输入图像的通道深度out_dim:输出图像的通道深度Ksize:卷积核的尺寸大小std:步长padding:填充
nn.ReLU(True):激活函数
nn.MaxPool2d(2, 2):池化层,Ksize和Padding均为2
值得注意的是,由于LeNet的输入为32x32,而MNIST的图像大小为28x28,要使数据大小和网络结构大小一致,一般是改网络大小而不改数据的大小。将padding置为2就可以使输出为28x28。
全连接层:nn.Linear(in_features, out_features, bias=True)
参数:
in_features:每个输入样本的大小out_features:每个输出样本的大小bias:若设置为False,这层不会学习偏置。默认值:True
形状:
- 输入:
(N,in_features) - 输出:
(N,out_features)
变量:
weight:形状为(out_features x in_features)的模块中可学习的权值bias:形状为(out_features)的模块中可学习的偏置
各层的输入和输出尺寸大小:
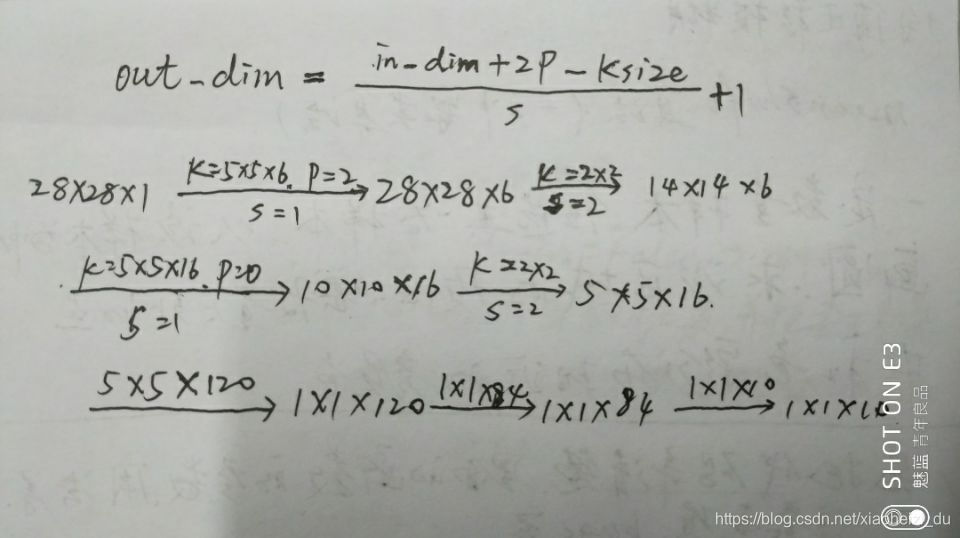
(3) 前向传播
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
5、定义损失函数loss和优化方式SGD
# 定义loss和optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
nn.CrossEntropyLoss():交叉熵损失
optim.SGD():SGD方式优化
6、训练模型
# 开始训练
for epoch in range(num_epoches):
print('epoch {}'.format(epoch + 1)) # .format为输出格式,formet括号里的即为左边花括号的输出
print('*' * 10)
running_loss = 0.0
running_acc = 0.0
for i, data in enumerate(train_loader, 1):
img, label = data
# cuda
if use_gpu:
img = img.cuda()
label = label.cuda()
img = Variable(img)
label = Variable(label)
# 向前传播
out = model(img)
loss = criterion(out, label)
running_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
accuracy = (pred == label).float().mean()
running_acc += num_correct.item()
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
"""
# ========================= Log ======================
step = epoch * len(train_loader) + i
# (1) Log the scalar values
info = {'loss': loss.data[0], 'accuracy': accuracy.data[0]}
for tag, value in info.items():
logger.scalar_summary(tag, value, step)
# (2) Log values and gradients of the parameters (histogram)
for tag, value in model.named_parameters():
tag = tag.replace('.', '/')
logger.histo_summary(tag, to_np(value), step)
logger.histo_summary(tag + '/grad', to_np(value.grad), step)
# (3) Log the images
info = {'images': to_np(img.view(-1, 28, 28)[:10])}
for tag, images in info.items():
logger.image_summary(tag, images, step)
if i % 300 == 0:
print('[{}/{}] Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, num_epoches, running_loss / (batch_size * i),
running_acc / (batch_size * i)))
"""
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(train_dataset))))
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
if use_gpu:
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
print()
1). 初始化loss和accuracy
print('epoch {}'.format(epoch + 1)): .format为输出格式,formet括号里的即为左边花括号的输出
data是一个以两个张量为元素的列表:

两个元素分别是img和label,元素类型为tensor类型。
Variable():由于Variable API几乎和Tensor API一致 (除了一些in-place方法,这些in-place方法会修改 required_grad=True的 input 的值)。多数情况下,将Tensor替换为Variable,代码一样会正常的工作。可以通过torch.Tensor的文档来获取相关知识。
torch.tensor(data, dtype=None, device=None, requires_grad=False)
参数
data (array_like):张量的初始数据。可以是列表,元组,NumPyndarray,标量和其他类型。dtype (torch.dtype, optional):返回张量的所需数据类型。默认值:如果为None,则从data中推断数据类型。device (torch.device, optional):返回张量的理想设备。默认值:如果为None,则使用当前设备作为默认张量类型(请参阅torch.set_default_tensor_type())。device将是CPU张量类型的CPU和CUDA张量类型的当前CUDA设备。requires_grad (bool, optional):如果autograd应该在返回的张量上记录操作。默认值:False。
img = Variable(img)
label = Variable(label)
是将tensor类型的img和label转换为variable类型。
2). 前向传播forward()
# 向前传播
out = model(img) # 输出
loss = criterion(out, label) # 计算交叉熵损失
running_loss += loss.item() * label.size(0) #
_, pred = torch.max(out, 1) # 预测最大值所在的位置标签,即预测的数字
num_correct = (pred == label).sum() # 预测正确的数目
accuracy = (pred == label).float().mean()
running_acc += num_correct.item()
criterion = LossCriterion() #构造函数有自己的参数
loss = criterion(x, y) #调用标准时也有参数
计算出来的结果已经对mini-batch取了平均。
torch.max():返回输入张量所有元素的最大值。
torch.max(input, dim, max=None, max_indices=None):
返回输入张量给定维度上每行的最大值,并同时返回每个最大值的位置索引。输出形状中,将dim维设定为1,其它与输入形状保持一致。
参数
input (Tensor):输入张量dim (int):指定的维度max (Tensor, optional):结果张量,包含给定维度上的最大值max_indices (LongTensor, optional):结果张量,包含给定维度上每个最大值的位置索引
预测最大值所在的位置标签,即预测的数字。
accuracy-求平均准确率
3). 反向传播backward()
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
zero_grad():清空所有被优化过的Variable的梯度.
step():进行单次优化
4). 测试模型
model.eval() # 模型评估
eval_loss = 0
eval_acc = 0
for data in test_loader: # 测试模型
img, label = data
if use_gpu:
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
print()
5). 打印每个epoch的loss和acc
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(train_dataset))))
这里又有.format()的用法。

7、保存模型
# 保存模型
torch.save(model.state_dict(), './cnn.pth')
torch.save(model.state_dict(), './cnn.pth')
model.state_dict():需要保存的模型
'./cnn.pth':模型的名称
参考
1、https://www.cnblogs.com/guoyaohua/p/8534077.html
2、https://blog.csdn.net/hustchenze/article/details/79154139
3、https://github.com/L1aoXingyu/pytorch-beginner/blob/master/04-Convolutional Neural Network/convolution_network.py
4、https://www.pytorchtutorial.com/10-minute-pytorch-4/
5、https://blog.csdn.net/u013066730/article/details/82498229

 浙公网安备 33010602011771号
浙公网安备 33010602011771号