
SqlServer 算法 :Nested Loops Join(嵌套连接)
自测试示例, 两表 都没有 建立索引 情况: start
1. sql 语句通过 nested loop 连接,
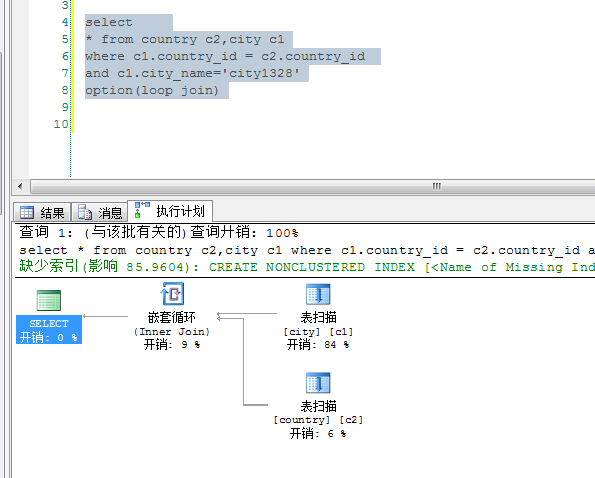
2. 默认 hash join
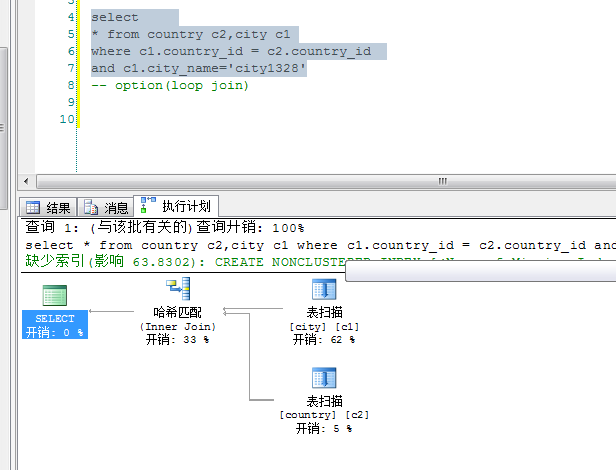
//end-------------------------------------------------------------------
说明:最近找到了一个不错的国外的博客http://blogs.msdn.com/b/craigfr/,博主是Sql Server的开发人员,写了很多Sql Server的内部原理性的文章,觉得非常有收获。所以试着把他翻译成中文,因为本人的英语和技术水平有限,难免会有错误,还请各位看官批评指教。
Nested Loops Join(嵌套连接)
Sql Server支持三种物理连接:nested loops join,merge join和hash join.这篇文章,我将描述nested loops join
(或者简称为NL)。
基本算法
最简单的情况是,nested loop会以连接谓词为条件取出一张表里的每一行(称为外部表)
与另外一张表(称为内部表)的每一行进行比较来寻找符合条件的行。(注意这里的"内部"和"外部"是具有多层含义的,必须从
上下文中来理解它们。"内部表"和"外部表"是指连接的输入,"内连接"和"外连接"是指逻辑操作。)
我们可以用伪码来解释这个算法:
for each row R1 in the outer table
for each row R2 in the inner table
if R1 joins with R2
return (R1, R2)
因为算法里的嵌套循环,所以命名为嵌套连接。
从比较的总行说来说,这种算法的成本是与外部表行数乘以内部表的行数成比例的。随着驱动表行数的增长
的成本增长是很快的,在实际情况我们通过减少内部表行数来减小算法的成本的。
还是以上篇文章给出的方案为例: create table Customers (Cust_Id int, Cust_Name varchar(10)) insert Customers values (1, 'Craig') insert Customers values (2, 'John Doe') insert Customers values (3, 'Jane Doe') create table Sales (Cust_Id int, Item varchar(10)) insert Sales values (2, 'Camera') insert Sales values (3, 'Computer') insert Sales values (3, 'Monitor') insert Sales values (4, 'Printer') 进行如下查询: select * from Sales S inner join Customers C on S.Cust_Id = C.Cust_Id option(loop join) 我加入了"loop join"提示来强迫优化器使用nested loops join.和"set statistics profile on" 一起运行得到如下的执行计划: Rows Executes 3 1 |--Nested Loops(Inner Join, WHERE:([C].[Cust_Id]=[S].[Cust_Id])) 3 1 |--Table Scan(OBJECT:([Customers] AS [C])) 12 3 |--Table Scan(OBJECT:([Sales] AS [S]))
这份执行计划里Customers是外部表,Sales是内部表。首先扫描Customers表。每次取出一个Customer,
对于每一个customer,都要扫描Sales表。因为有3个Customers,所以Sales表被扫描了3次。每次扫描返回
4行。判断每一个sale与当前的customer是否具有相同的Cust_Id,如果相同就返回这一对行.我们有3个
customer和4个sale所以我们进行了3*4=12次比较。其中只有3次比较符合条件。
如果在Sales表创建索引会是什么情况呢: create clustered index CI on Sales(Cust_Id) 我们得到了如下的执行计划: Rows Executes 3 1 |--Nested Loops(Inner Join, OUTER REFERENCES:([C].[Cust_Id])) 3 1 |--Table Scan(OBJECT:([Customers] AS [C])) 3 3 |--Clustered Index Seek(OBJECT:([Sales].[CI] AS [S]), SEEK:([S].[Cust_Id]=[C].[Cust_Id]) ORDERED FORWARD)
这次,并没有做全表扫描,而是进行了索引探寻。仍然进行了3次索引探寻-每个customer一次,
但是每次索引探寻只返回了与当前Cust-Id相匹配并满足谓词条件的一条记录。所以,索引探寻只返回了
3行,而不是全表扫描的12行。
请注意这里索引探寻的依赖条件C.CustId来自于连接的外部表-Customers全表扫描。
每次我们执行索引探寻(再次说明我们执行了3次-每个用户一次),C_CustId有不同的值。
我们称C.CustId为"关联参数";如果一个nested loops join有关联参数,执行计划里会以"OUTER REFERENCES"
显示出来。我们经常把这种以依赖于关联参数的索引探寻方式执行的nested loop join称为
"索引连接"。这是非常常见的场景。
Nested loops join支持什么类型的连接谓词?
Nested loops join支持包括相等连接谓词和不等谓词连接在内的所有连接谓词。
Nested loops join支持什么类型的逻辑连接?
Nested loops join支持以下类型的逻辑连接:
* Inner join
* Left outer join
* Cross join
* Cross apply and outer apply
* Left semi-join and left anti-semi-join
Nested loops join不支持以下逻辑连接:
* Right and full outer join
* Right semi-join and right anti-semi-join
为什么Nested loops join 只支持左连接?
我们很容易扩展Nested loops join 算法来支持left outer 和semi-joins.例如,下边是左外连接的伪码。
我们可以写出相似的代码来实现 left semi-join 和 left anti-semi-join.
for each row R1 in the outer table
begin
for each row R2 in the inner table
if R1 joins with R2
return (R1, R2)
if R1 did not join
return (R1, NULL)
end
这个算法记录我们是否连接了一个特定的外部行。如果已经穷尽了所有内部行,但是没有找到一个
符合条件的内部行,就把该外部行做为NULL扩展行输出。
那么我们为什么不支持right outer join呢。在这里,我们想返回符合条件的行对(R1,R2)
和不符合连接条件的(NULL,R2)。问题是我们会多次扫描内部表-对于外部表的每行都要扫描一次。
在多次扫描过程中我们可能会多次处理内部表的同一行。这样我们就无法来判断某一行到底符合
不符合连接条件。更进一步,如果我们使用index join,一些内部行可能都不会被处理,但是这些行在
外连接时是应该返回的。
幸运的是right outer join可以转换为left outer join,right semi-join可以转换为left semi-join,
所以right outer join和semi-joins是可以使用nested loops join的。但是,当执行转换的时候可能会
影响性能。例如,上边方案中的"Customer left outer join Sales",由于表内部表Sales有聚集索引,所以
我们在连接过程中可以使用索引探寻。如果"Customer right outer join Sales" 转换为 "Sales left outer
join Customer”,我们则需要在Customer表上具有相应的索引了。
full outer joins是什么情况呢?
nested loops join完全支持outer join.我们可以把"T1 full outer join T2"转换为"T1 left outer join T2
UNION T2 left anti-semi-join T1".可以这样来理解,将full outer join转换为一个左连接-包含T1和T2所有的
符合条件的连接行和T1表里没有连接的行,然后加上那些使用anti-semi-join从T2返回的行。下边是转换过程:
select *
from Customers C full outer join Sales S
on C.Cust_Id = S.Cust_Id
Rows Executes
5 1 |--Concatenation
4 1 |--Nested Loops(Left Outer Join, WHERE:([C].[Cust_Id]=[S].[Cust_Id]))
3 1 | |--Table Scan(OBJECT:([Customers] AS [C]))
12 3 | |--Clustered Index Scan(OBJECT:([Sales].[Sales_ci] AS [S]))
0 0 |--Compute Scalar(DEFINE:([C].[Cust_Id]=NULL, [C].[Cust_Name]=NULL))
1 1 |--Nested Loops(Left Anti Semi Join, OUTER REFERENCES:([S].[Cust_Id]))
4 1 |--Clustered Index Scan(OBJECT:([Sales].[Sales_ci] AS [S]))
3 4 |--Top(TOP EXPRESSION:((1)))
3 4 |--Table Scan(OBJECT:([Customers] AS [C]), WHERE:([C].[Cust_Id]=[S].[Cust_Id]))
注意:在上边的例子中,优化器并选择了聚集索引扫描而不是探寻。这完全是基于成本考虑而做出的决定。表非常小(只有一页)
所以扫描或探寻并没有什么性能上的区别。
NL join好还是坏?
实际上,并没有所谓"最好"的算法,连接算法也没有好坏之分。每一种连接方式在正确的环境下性能非常好,
而在错误的环境下则非常差。因为nested loops join的复杂度是与驱动表大小和内部表大小乘积成比例的,所以在驱动表比较小
的情况下性能比较好。内部表不需要很小,但是如果非常大的话,在具有高选择性的连接列上建立索引将很有帮助。
一些情况下,Sql Server只能使用nested loops join算法,比如Cross join和一些复杂的cross applies,outer applies,
(full outer join是一个例外)。如果没有任何相等连接谓词的话nested loops join算法是Sql Server的唯一选择。
参考 :
