数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST
简介
在上一篇博客:数据挖掘入门系列教程(十点五)之DNN介绍及公式推导中,详细的介绍了DNN,并对其进行了公式推导。本来这篇博客是准备直接介绍CNN的,但是想了一下,觉得还是使用keras构建一个DNN网络,然后进行一定的分类操作,这样能够更加的直观一点。
在这篇博客中将介绍:
- keras的基本使用
- 使用keras构建DNN对MNIST数据集进行预测
使用前准备
这次我们将使用keras库去构建神经网络,然后默认使用tensorflow作为后端,我是用的python库版本如下:
- keras:version 2.3.1
- tensorflow:version 2.1.0
这篇博客并不会讲keras,tensorflow的安装,不过值得注意的是,如果自己电脑有英伟达的显卡就尽量去装gpu版本的tensorflow,然后安装对应版本的cuda。一般来说使用GPU能够大幅度提高程序计算的速度(我的mx250哭晕在厕所)。至于AMD的显卡,emm,我就不知道支不支持了。
关于keras的具体使用,可以去看一看官方文档,但是目前官方文档的目录栏有一点问题,因此建议大家去看这个keras 中文文档,这个是根据官方文档生成的。
准备数据集
这里我们使用keras提供MNIST数据集,训练集为 60,000 张$ 28\times 28 = 784$像素灰度图像,测试集为 10,000 同规格图像,总共 10 类数字标签。
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
然后我们可以看一看数据集的shape:
print(x_train.shape, 'x_train samples')
print(x_test.shape, 'x_test samples')
print(y_train.shape, 'y_trian samples')
print(y_test.shape, 'Y_test samples')

此时,我们就已经加载好数据集了。我们可以稍微的看一看数据集长什么样子:
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(12,10))
x, y = 8, 6
for i in range(x*y):
plt.subplot(y, x, i+1)
plt.imshow(x_train[i],interpolation='nearest')
plt.show()

因为数据集并不能能够直接进行训练或者训练效果不好,在这里我们将数据进行一下变换。比如说归一化,onehot编码(这个必须做)。
数据集的变换
首先,我们的DNN的设计如下:
输入层是由784个神经元构成的,但是在前面我们已经知道x_train.shape是(6000,28,28)。输出层由10个神经元构成,而y_train.shape是(6000,),毋庸置疑,我们需要对x,y数据进行编码。
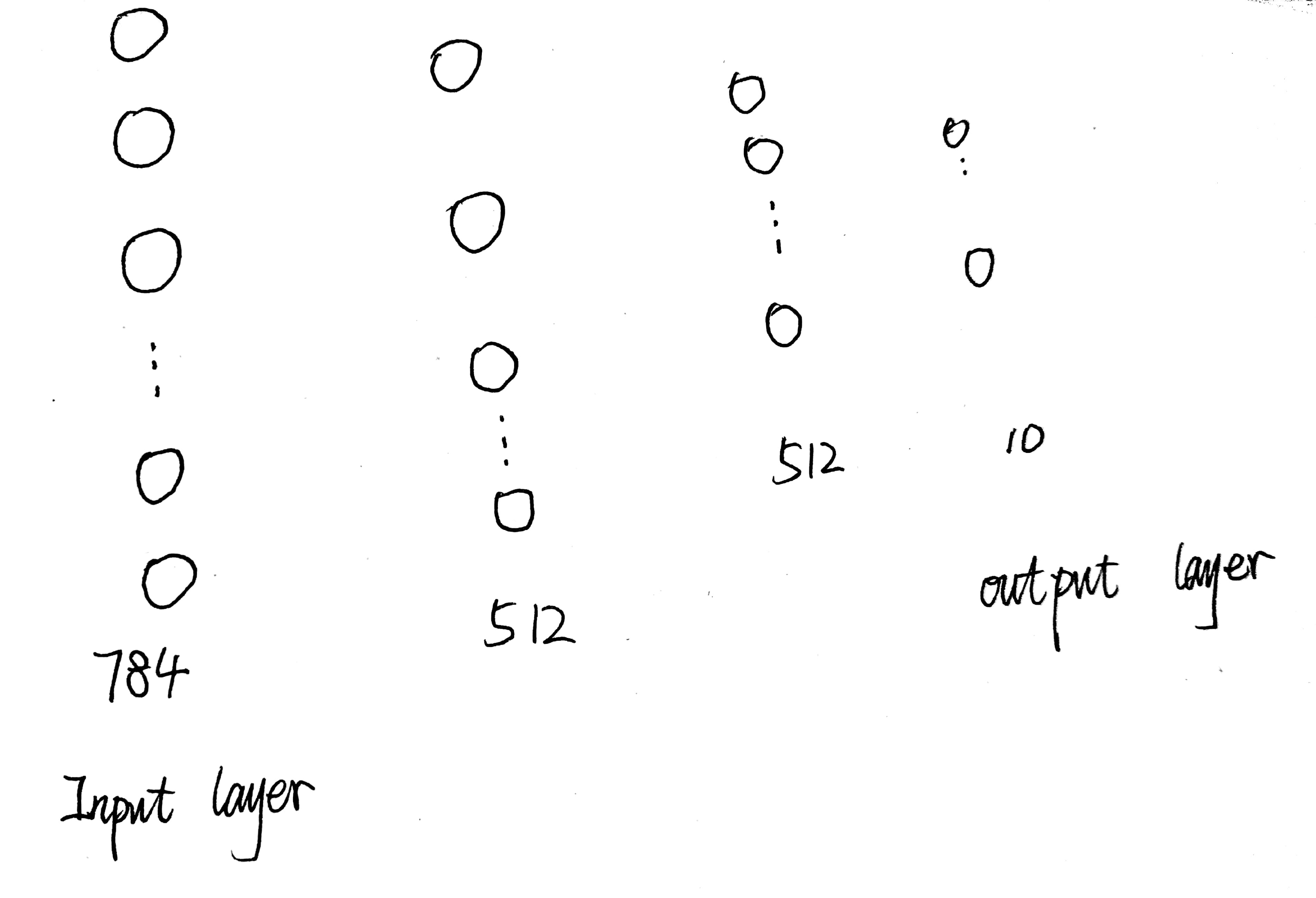
对于x数据来说,我们需要将它变成(6000,784)的类型,对于y我们进行onehot编码就行了(one hot编码在前面已经介绍过了,这里就不多做介绍了),同时在这里我们还将数据进行归一化(可以提高模型的准确率)。
import keras
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
# 将数据变成float类型,这样能够被255除
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# one hot 编码,将类向量(整数)转换为二进制类矩阵。
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
构建DNN网络
首先我们导入Sequential。
from keras.models import Sequential
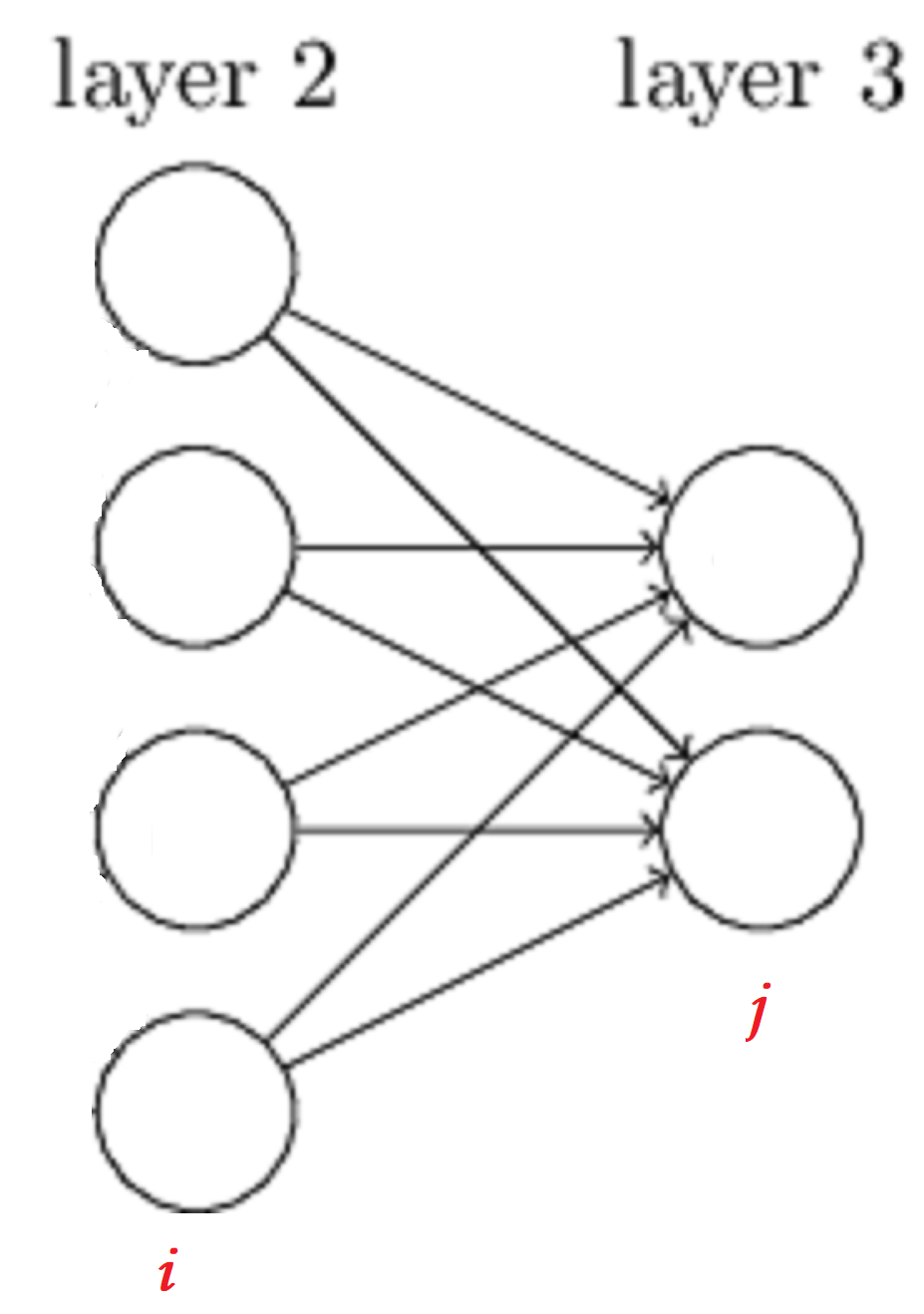
Sequential是一个顺序模型:多个网络层的线性堆叠,每一层接受上一层的输入,向下一层进行输出,示意图如下:

这里,再说一个概念,全连接层,很简单理解,就是某一层用数学公式来表达就是\(output = W\times input\),比如说下图中的layer2和layer3就是全连接的,也就是说layer2是全连接层。在keras中,可以使用Dense去创建一个全连接层。
关于Dense的参数,截取官方文档如下:
参数
- units: 正整数,输出空间维度。
- activation: 激活函数 (详见 activations)。 若不指定,则不使用激活函数 (即,「线性」激活:
a(x) = x)。- use_bias: 布尔值,该层是否使用偏置向量。
- kernel_initializer:
kernel权值矩阵的初始化器 (详见 initializers)。- bias_initializer: 偏置向量的初始化器 (see initializers).
- kernel_regularizer: 运用到
kernel权值矩阵的正则化函数 (详见 regularizer)。- bias_regularizer: 运用到偏置向的的正则化函数 (详见 regularizer)。
- activity_regularizer: 运用到层的输出的正则化函数 (它的 "activation")。 (详见 regularizer)。
- kernel_constraint: 运用到
kernel权值矩阵的约束函数 (详见 constraints)。- bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
然我们来看一看具体的使用(里面涉及的几个激活函数随便去网上搜一下就知道了):
from keras.layers import Dense, Dropout
# 创建一个网络模型
model = Sequential()
# 创建输入层 512代表的是输出维度为512,也就是第二层神经元有512个,输入维度为(784,),激活函数为Relu
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
# 创建layer2,然后向下层输出的空间维度为512
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
# 输出层,因为只有10个数字,所以输出空间维度为10,激活函数为softmax。
model.add(Dense(10, activation='softmax'))
# 网络模型的介绍
print(model.summary())
Dropout 应用于输入。Dropout 包括在训练中每次更新时, 将输入单元的按比率随机设置为 0, 这有助于防止过拟合。
简单点来说,他就是这样的,随机(按比率)将某一个输入值变成0,这样他就没办法向下一层传递信息。

打印的网络结构模型如下所示,还是有蛮多参数的:
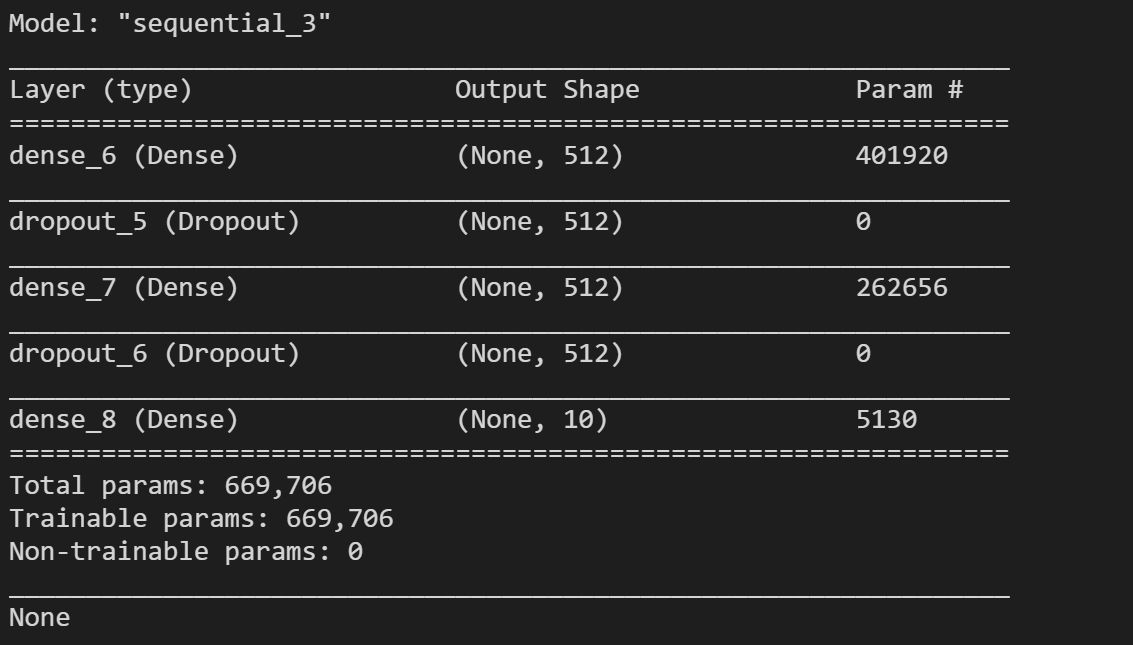
接着我们就来讲一下如何配置这个模型,在keras中,配置一个模型至少需要两个参数loss和optimizer。其中loss就是损失函数,optimizer就是优化器,也就是前篇博客提到的优化方法,比如说梯度下降法,牛顿法等等,metrics代表在训练和测试期间的模型评估标准。
from keras.optimizers import RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
这里我们选择RMSprop,具体内容可以参考Day 69: rmsprop,然后loss我们选择categorical_crossentropy,因为它是多分类任务。其表达式为:
\(C E(x)=-\sum_{i=1}^{C} y_{i} \log f_{i}(x)\)
其中, \(x\)表示输入样本, \(C\)为待分类的类别总数。 \(y_{i}\) 为第\(i\)个类别对应的真实标签, \(f_{i}(x)\) 为对应的模 型输出值。
开始训练
最后我们可以使用这个模型来训练数据了,代码:
# history保存了每一次训练的loss,accuracy
history = model.fit(x_train, y_train,
batch_size=128,
epochs=32,
verbose=1,
validation_data=(x_test, y_test))
x_train, y_train这个就没必要解释了,很简单,就是训练的数据集。
batch_size代表每一次梯度更新的样本数,默认32。如何理解这个这一个参数呢?意思就是说每次一训练的时候训练batch_size个样本,针对每一个样本我们都可以求出它对应的loss,然后我们求和然后取平均\(C E(x)_{\text {final}}=\frac{\sum_{b=1}^{batch\_size} C E\left(x^{(b)}\right)}{N}\),然后再使用BP算法。epochs: 训练模型迭代轮次。verbose: 0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行。validation_data:用来评估损失,以及在每轮结束时的任何模型度量指标。 模型将不会在这个数据上进行训练。
部分打印数据如下:

在我的笔记本i5十代u,mx250的情况下,训练了大概1分多钟,毕竟数据集还是比较小的,然后参数也不是很多。
进行评估
# 这里的verbose和fit中的含义一样
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
最后结果如下图:

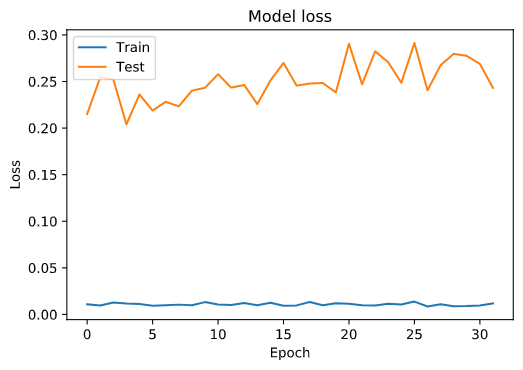
训练过程的accuracy和loss
这里我们将每一次轮训练以及测试对应的loss和accuracy画出来:
# 绘制训练过程中训练集和测试集合的准确率值
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# 绘制训练过程中训练集和测试集合的损失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()

总结
ok,这篇博客就结束了。总的来说还是蛮顺利的,因为不需要去推数学公式,基本上没有什么难度(当然,如果想更好的提高准确率还是蛮难的,可以去kaggle里面看一下大佬的解决方案)。这篇博客简单的介绍了keras使用,我力求将每一个用到的函数都讲清楚,但是实际上很难,因为可能我认为讲清楚了,但是实际上你可能还是没有明白。这个时候可以去多看一下官方文档,或者别人的博客,当然,私信我也是🆗的。
项目地址:Github

 浙公网安备 33010602011771号
浙公网安备 33010602011771号