数据挖掘入门系列教程(十点五)之DNN介绍及公式推导
深度神经网络(DNN,Deep Neural Networks)简介
首先让我们先回想起在之前博客(数据挖掘入门系列教程(七点五)之神经网络介绍)中介绍的神经网络:为了解决M-P模型中无法处理XOR等简单的非线性可分的问题时,我们提出了多层感知机,在输入层和输出层中间添加一层隐含层,这样该网络就能以任意精度逼近任意复杂度的连续函数。
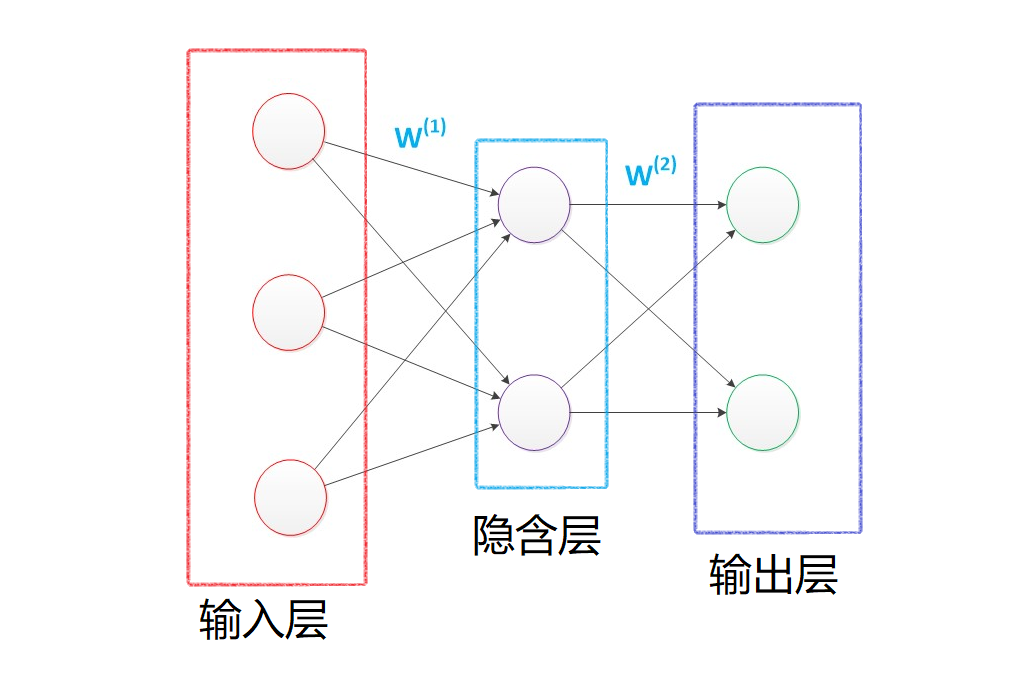
然后在数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST博客中,我们使用类似上图的神经网络结构对MINIST数据集进行了训练,最后在epochs = 100的条件下,F1 socre达到了约\(86\%\)。
这个时候我们想一想,如果我们将中间的隐含层由一层变为多层,如下图所示:
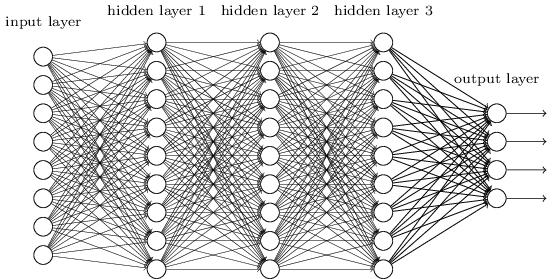
那么该网络就变成了深度神经网络(DNN),也可以称之为多层感知机(Multi-Layer perceptron,MLP)。
下面将对这个网络进行介绍以及公式推导。
DNN的基本结构及前向传播
在上面的图中,我们可以很容易的观察到,在DNN中,层与层之间是全连接的,也就是如同感知机一样,第\(i\)层的任意一个神经元与第\(i+1\)层的任意一个神经元都有连接。尽管这个网络看起来很庞大复杂,但是如果我们只看某一小部分,实际上它的原理与感知机很类似。
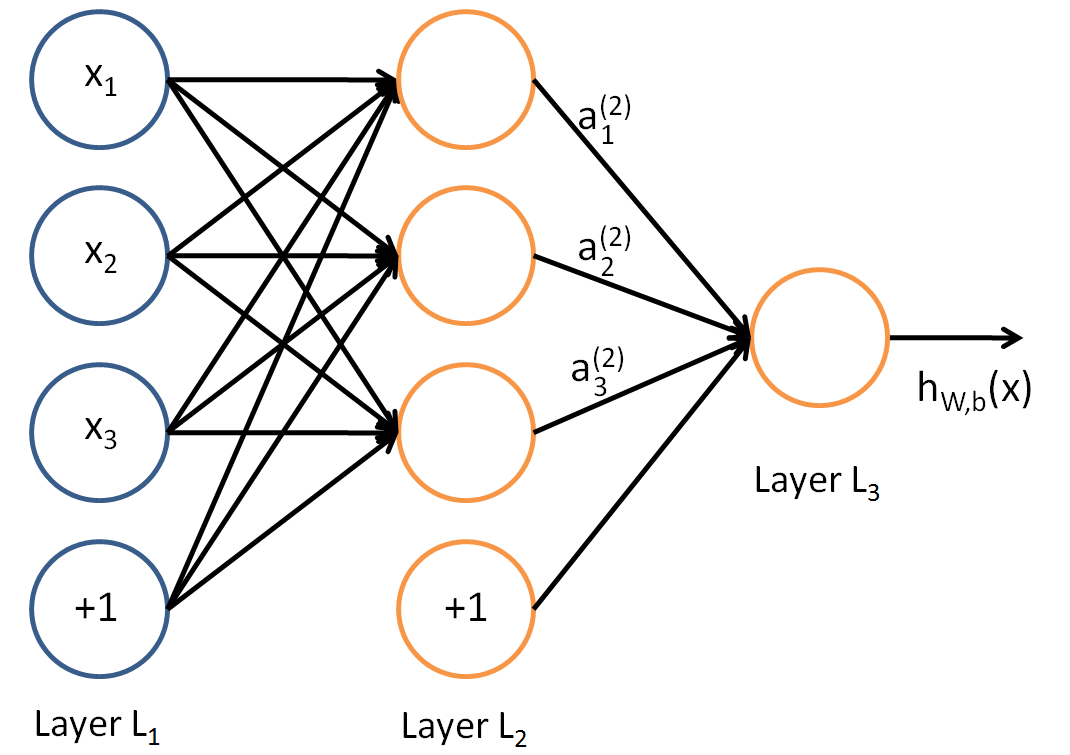
如同感知机,我们可以很简单的知道:
对于\(LayerL_2\)的输出,可知:
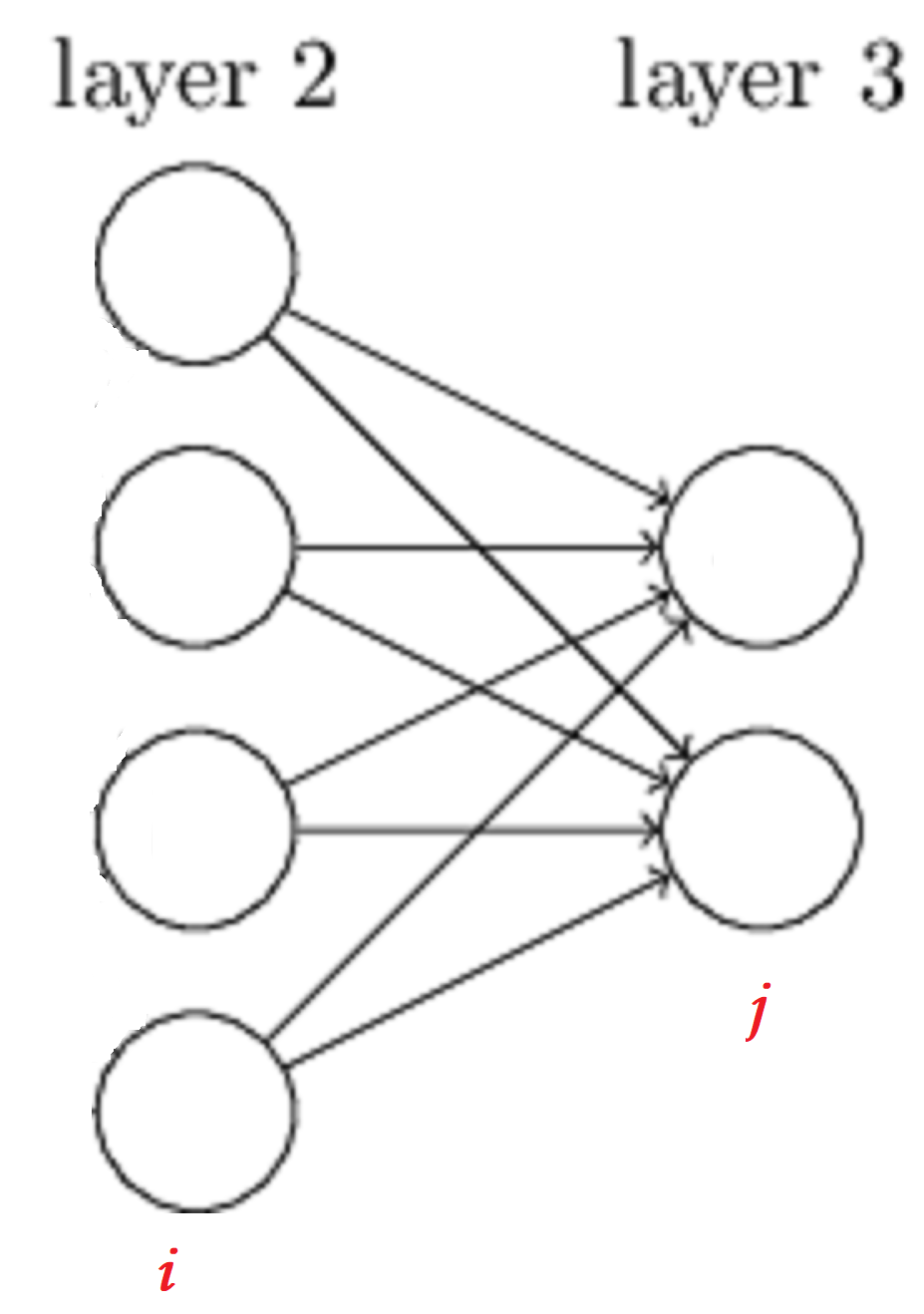
对于\(w\)的参数上标下标解释,以下图为例:

对于\(w_{24}^3\),上标3代表\(w\)所在的层数,下标2对应的是第三层的索引2,下标4对应的是第二层的索引4。至于为什么标记为\(w_{24}^3\)而不是\(w_{42}^3\),我们可以从矩阵计算的角度进行考虑:
在下图中,为了得到\(a\),我们可以直接使用\(a = Wx\),也可使用\(a = W^Tx\)这种形式,但是对于第二种形式,我们需要使用转置,这样会加大计算量,因此我们采用第一种形式。

对于\(LayerL_3\)的输出,可知:
假设我们在\(l-1\)层一共有\(m\)个神经元,对于第\(l\)层第\(j\)个神经元的输出\(a_j^l\),有:
如果我们采用矩阵的方式进行表示,则第\(l\)层的输出为:
因此,我们可以对DNN的前向传播算法进行推导,从输入到输出有:
输入: 总层数\(L\),所有隐藏层和输出层对应的矩阵\(W\),偏倚向量\(b\),输入值向量\(x\)
输出:输出层的输出\(a^L\)
1) 初始化\(a^1 = x\)
2) for \(l=2\) to \(L\),计算:
\[\begin{equation}a^{l}=\sigma\left(z^{l}\right)=\sigma\left(W^{l} a^{l-1}+b^{l}\right)\end{equation} \]最后结果的输出即为\(a^L\)
以上便是DNN的前向传播算法,实际上挺简单的,就是一层一层向下递归。
DNN反向传播(BP)算法
在数据挖掘入门系列教程(七点五)之神经网络介绍中,我们提到过BP算法,并进行过详细的数学公式的推导。BP算法的目的就是为了寻找合适的\(W,b\)使得损失函数\(Loss\)达到某一个比较小的值(极小值)。
在DNN中,损失函数优化极值求解的过程最常见的一般是通过梯度下降法来一步步迭代完成的,当然也有其他的方法。而在这里,我们将使用梯度下降法对DNN中的反向传播算法进行一定的数学公式推导。图片和部分过程参考了Youtube:反向传播算法,但是对其中的某一些图片进行了修改。
在左边的图片中,是一个比较复杂的DNN网络,我们针对该DNN网络进行简化,将其看成每一层只有一个神经元的网络,如右图所示

此时我们还可以将问题进行简化,如果我们只看简化模型的最后面两个神经元,则有:
\(y\)代表期望值,\(C_o\)代表损失函数\(\mathrm{C_0}=\operatorname{Loss}=\left(a^{(L)}-y\right)^{2}\),\(\sigma\)代表激活函数,比如说Relu,sigmoid,具体的表达式在图中,我就不写出来了。
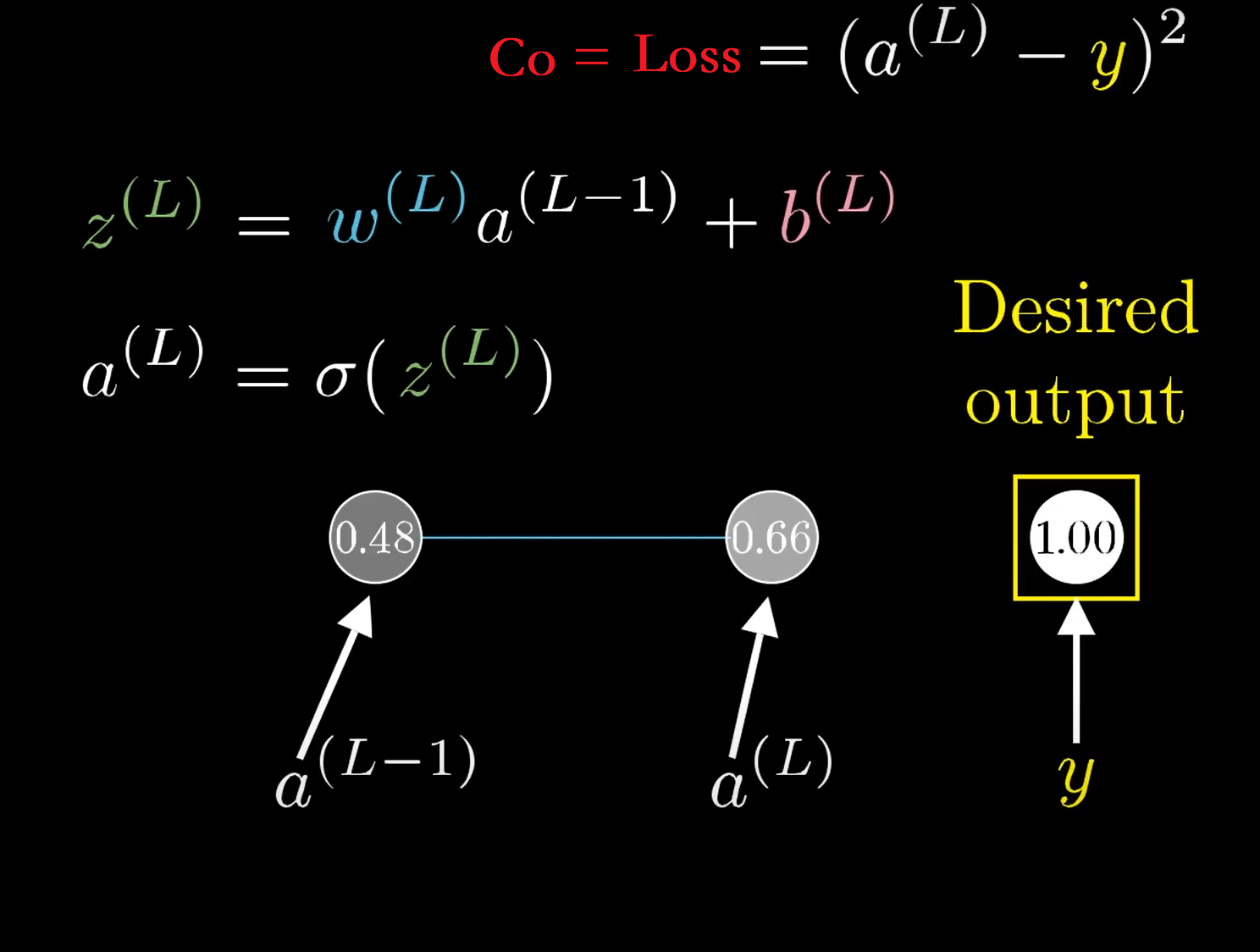
在下图所示,当\(w^{(L)}\)发生微小的改变(\(\partial w^{(L)}\))时,会通过一连串的反应使得\(C_0\)发生微小的改变:类似蝴蝶扇动翅膀一样,响应流程如下\(\partial w^{(L)} \longrightarrow z^{(L)} \longrightarrow a^{(L)} \longrightarrow C_0\)。
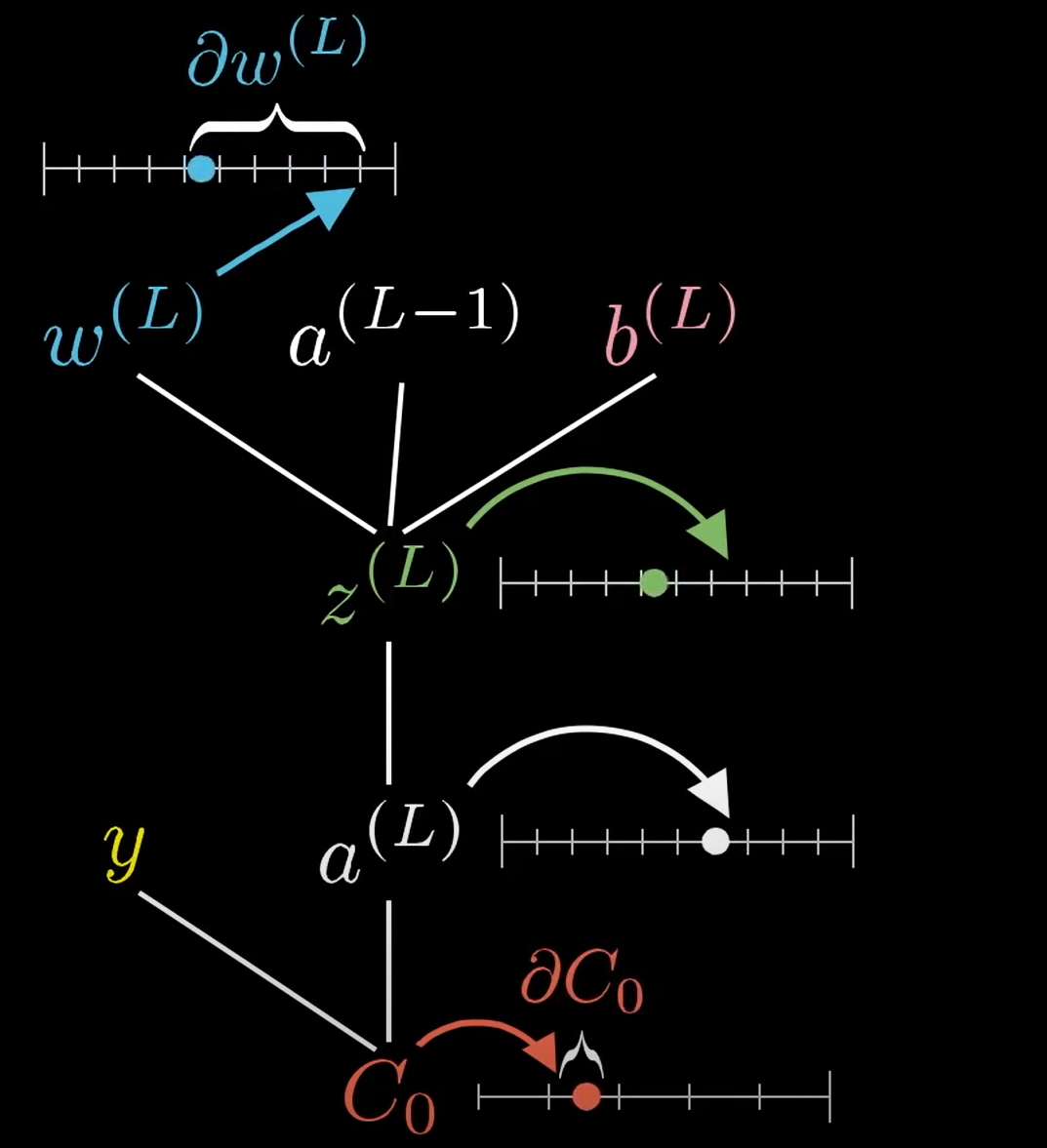
此时我们对\(C_0\)求其\(W^L\)的偏导,则得到了下式:
我们分别求各自偏导的结果:
综上,结果为:
同理我们可得:
这时候,我们可以稍微将问题复杂化一点,考虑多个神经元如下图所示,那么此时所有的变量\(W,x,b,z,a,y\)也就变成了一个矩阵:
求导结果如下(这里我们使得Loss为\(J(W, b, x, y)=\frac{1}{2}\left\|a^{L}-y\right\|_{2}^{2}\)表示,代表Loss与\(W, b, x, y\)有关):
注意上式中有一个符号\(\odot\),它代表Hadamard积, 对于两个维度相同的向量 \(A\left(a_{1}, a_{2}, \ldots a_{n}\right)^T 和 B\left(b_{1}, b_{2}, \ldots b_{n}\right)^{T},\) 则 \(A \odot B=\) \(\left(a_{1} b_{1}, a_{2} b_{2}, \ldots a_{n} b_{n}\right)^{T}\)。怎么理解这个变量呢?从一个不怎么严谨的角度进行理解:
假设第\(L-1\)层有\(i\)个神经元,第\(L\)层有\(j\)个神经元(如上图所示),那么毋庸置疑,\(\partial W\)为一个\(j \times i\)的矩阵(因为\(W\)为一个\(j \times i\)的矩阵,至于为什么,前面前向传播中已经提到了)。\(A \odot B\)则是一个\(j \times 1\)的矩阵,然后与\(\left(a^{L-1}\right)^{T}\)*(它是一个$1 \times i \(的矩阵)*相乘,最后结果则为一个\)j \times i$的矩阵。
在求导的结果\(\frac{\partial J(W, b, x, y)}{\partial W^{L}} 和 \frac{\partial J(W, b, x, y)}{\partial b^{L}}\)有公共部分,也就是\(\frac{\partial J(W, b, x, y)}{\partial z^{L}}=\left(a^{L}-y\right) \odot \sigma^{\prime}\left(z^{L}\right)\),代表输出层的梯度,因此我们令:
根据前向传播算法,对于与第\(l\)层的\(W^l 和 b^l\)的梯度有如下结论:
因此问题就变成了如何求得任意一层\(l\)的\(\delta^{l}\),假设我们一共有\(L\)层,则对于\(\delta^{L}\)我们还是能够直接进行求解\(\delta^{L}=\left(a^{L}-y\right) \odot \sigma^{\prime}\left(z^{L}\right)\),那么我们如何对\(L-1\)层进行求解呢?
设第\(l+1\)层的\(\delta^{l+1}\)已知,则对\(\delta^{l}\)的求解如下:
也就是说,求解关键点又到了\((\frac{\partial z^{l+1}}{\partial z^{l}})^T\)的求解,根据前向传播算法:
因此,有:
综上可得:
因此当我们可以得到任意一层的\(\delta^{l}\)时,我们也就可以对任意的\(W^l和b^l\)进行求解。
算法流程
下面算法流程是copy深度神经网络(DNN)反向传播算法(BP)的,因为他写的比我好多了,我就直接用他的了。
现在我们总结下DNN反向传播算法的过程。由于梯度下降法有批量(Batch),小批量(mini-Batch),随机三个变种, 为了简化描述, 这里我们以最基本的批量梯度下降法为例来描述反向传播算法。实际上在业界使用最多的是mini-Batch的 梯度下降法。不过区别又仅在于迭代时训练样本的选择而已。
输入: 总层数\(L\), 以及各隐藏层与输出层的神经元个数, 激活函数, 损失函数, 选代步长 \(\alpha\),最大迭代次数\(MAX\)与停止迭代阈值\(\epsilon\), 输入的\(m\)个训练样本 \(\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots,\left(x_{m}, y_{m}\right)\right\}\)。
输出: 各隐藏层与输出层的线性关系系数矩阵 \(W\) 和偏倚向量\(b\)
-
初始化各隐藏层与输出层的线性关系系数矩阵\(W\)和偏倚向量\(b\)的值为一个随机值。
-
for iter to 1 to MAX:
2.1 for \(i=1\) to \(m\) :
a. 将DNN输入 \(a^{1}\) 设置为 \(x_{i}\)
b. for \(l=2\) to \(L,\) 进行前向传播算法计算 \(a^{i, l}=\sigma\left(z^{i, l}\right)=\sigma\left(W^{l} a^{i, l-1}+b^{l}\right)\)
c. 通过损失函数计算输出层的 \(\delta^{i, L}\)
d. for \(l=\) L-1 to 2 , 进行反向传播算法计算 \(\delta^{i, l}=\left(W^{l+1}\right)^{T} \delta^{i, l+1} \odot \sigma^{\prime}\left(z^{i, l}\right)\)
2.2 for \(l=2\) to \(\mathrm{L},\) 更新第\(l\)层的 \(W^{l}, b^{l}:\)
2-3. 如果所有\(W,b\)的变化值都小于停止迭代阈值 \(\epsilon,\) 则跳出迭代循环到步骤3。
- 输出各隐藏层与输出层的线性关系系数矩阵\(W\)和偏倚向量\(b\)。
总结
这一篇博客主要是介绍了以下内容:
- DNN介绍
- DNN的基本结构
- DNN的前向传播
- DNN的BP算法
本来是想在这一章博客中将CNN也介绍一下,但是想了想,可能还是分开介绍比较好。因此我将会在下一篇博客中主要会对CNN进行介绍以及部分推导。
参考
- 深度学习研究综述 ——张荣,李伟平,莫同
- 深度神经网络(DNN)模型与前向传播算法
- Youtube:反向传播算法
- 深度学习(一):DNN前向传播算法和反向传播算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号