数据挖掘入门系列教程(七)之朴素贝叶斯进行文本分类
数据挖掘入门系列教程(七)之朴素贝叶斯进行文本分类
贝叶斯分类算法是一类分类算法的总和,均以贝叶斯定理为基础,故称之为贝叶斯分类。而朴素贝叶斯分类算法就是其中最简单的分类算法。
朴素贝叶斯分类算法
朴素贝叶斯分类算法很简单很简单,就一个公式如下所示:
上面的公式就是朴素贝叶斯分类算法的核心。现在不理解没关系,只要能够知道并能够推导出这个公式是正确的就🆗了。(至于怎么推导,emm,概率论里面最基础的公式\(P(B|A) = \frac{P(A,B)}{P(A)}\))。
首先我们来理解\(P(B|A)\)这个公式,在概率论上这个公式表示“在A发生的情况下,B发生的概率”。A那么在数据挖掘中,\(A和B\)又代表着什么呢?我们可以这样理解,对于分类,我们肯定已知被预测物体特征,然后想通过这些特征来判断该物体属于哪一个类别。因此:
对于数据挖掘来说,\(A\)通常是观察样本个体(也就是特征),\(B\)为被测个体所属的类别。
那么这个公式变成了:
至此,我们就可以拿这个公式进行分类了。但是这里还是有个问题,一个物体的特征不可能只有一个,肯定是有多个,那么下面这个公式怎么计算。
首先,我们假设\(特征1,特征2,特征3……\)相互独立,那么有以下结论:
so,有以下公式:
因此朴素贝叶斯公式如下:
这里,又有一个问题,如果我的模型已经训练好了,然后我们使用测试数据去测试的时候,如果某个\(P(特征_{ij}) = 0\)怎么办(\(特征_{ij}表示特征i的特征值是j\)) 此时\(h=0\),这样肯定不行。那么有什么解决方法没?拉普拉斯平滑解决了这个问题。
引入拉普拉斯平滑之后公式如下:
很显然,拉普拉斯平滑避免了因为训练集中样本不充分而导致概率估计值为0的问题。至于具体的朴素贝叶斯的应用举例子,可以参考这位博主的两篇博客:带你理解朴素贝叶斯分类算法和理解朴素贝叶斯分类的拉普拉斯平滑,写的比我好多了,emm。
🆗,目前我们已经能够计算出不同特征的特征值在不同类别下的\(P\)值(或者说比较标准\(h\)),然后我们通过\(P\)值的大小,以判断某一条数据属于那一个类别。
朴素贝叶斯的介绍就到这里,下面来介绍文本的数据挖掘流程。
加载数据集
首先先说这篇博客挖掘文本数据目的(使用《Python数据挖掘入门与实践》上面的例子):在twitter的话题中,“Python”可以代表一种编程语言,也可以代表蟒蛇,也可以代表一个鞋子牌子。而我们的目的就是判断一个文本中“Python”的具体含义(至于为什么不用微博的话题,emm,没有现成的数据集,懒得自己再去弄了)。
文本的数据与前面的Iris数据集的不同之处在于他的数据特征不是那么的明显,因为文本数据不是固定格式的,不同的文章不可能按照相同的格式去写,而我们第一步就是需要将文本数据转换成数据挖掘算法能够识别的数据格式。
数据集来自这位博主的博客,在我写这篇博客的时候,我twitter开发者还未申请成功,并且我也不想做手工标注类别的狠人。
数据集:Github
数据集中一共有95条推特,同时对每一条推特进行标记,1代表这条推特中“python”表示编程语言,0代表非编程语言(至于数据集为什么这么少,估计上面的那一位博主也不想做一个狼人去手工标注那么多数据集)。
加载数据集如下:
在数据集中,数据是以json格式保存的,在json中“text”表示推文内容:
import json
import os
# 推文数据集
data_file = "./Data/python_tweets.json"
# 类别数据集
class_file = "./Data/python_classes.json"
data_list = []
class_list = []
# 加载推文
with open(data_file) as f:
for line in f:
# 如果内容为空
if(len(line.strip()) == 0):
continue
data_list.append(json.loads(line)["text"])
# 加载类别
with open(class_file) as f:
class_list = json.loads(f.read())
import numpy as np
class_list = np.array(class_list)
data_list = np.array(data_list)
数据集我们已经加载完毕了,然后我们就要从文本中提取特征。
文本转化
文本数据转成算法可识别的特征有很多种方式,比如说文本的语言,长短,以及来源都是一种特征,根据不同的需求我们需要不同的特征。在这篇博客中,我们的目的是为了判断“Python”的分类,因此我们需要获得文本的内容特征。
我们可以使用一种很简单但是却不错的方法,那就是统计数据集中每一条推文中每种单词出现的情况。《Python数据挖掘入门与实践》称之为布袋模型。有多种统计方法:
-
统计每一种单词出现的次数。比如说“go go go, come on”中"go"出现了三次
-
统计每一种单词出现的词率。比如说“go go go, come on”中"go"的词频是\(\frac{3}{6}\)(包括逗号)
-
统计每一种单词是否出现。比如说“go go go, come on”中"go"出现了为True
-
词频-逆文档频率法。以后做介绍
这里我们使用第三种方法,那么首先第一个步骤就是我们得对其进行分词。与中文的jieba分词类似,不过这里我们是将一个单词分为一个词。这里使用NLTK库进行分词,使用如下:

NLTK库安装可以看一下其他博主的博客,但是在下载package的时候要记得挂代理下载,或者从其他地方下载好离线安装(不然一杯茶一根烟,一个package下一天)。
这里我们自定义一个转换器,目的是对数据集进行预处理。在下面的代码中主要是对推文进行分词,然后将出现过的词进行保存。
from sklearn.base import TransformerMixin
from nltk import word_tokenize
class NLTKBOW(TransformerMixin):
def fit(self,X,y=None):
return self
def transform(self,X):
return [
{
word:True for word in word_tokenize(document)
}for document in X
]
通过这种处理后,部分的数据如下:
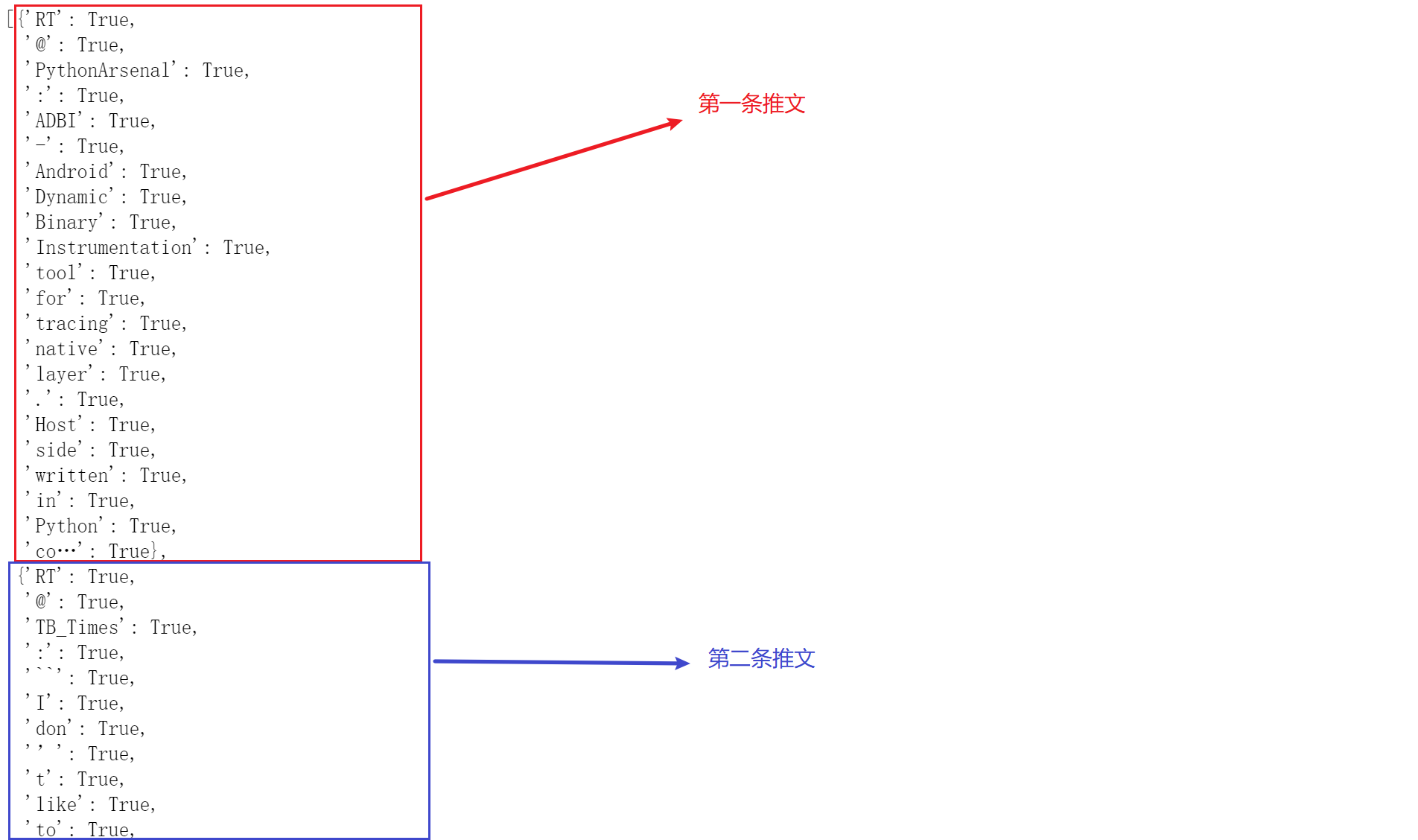
将字典转成矩阵
通过上面的操作我们获得了一个字典的列表,但是对于sklean的分类器,它并不直接支持这些数据格式的操作,so,我们需要将这些数据转成矩阵,这里我们可以使用DictVectorizer(也是一个转化器,可以用于流水线)进行操作。举个官方的例子:
from sklearn.feature_extraction import DictVectorizer
D = [{'foo': 1, 'bar': 1}, {'foo': 1, 'baz': 1},{'baz':1,'dd':1}]
dv = DictVectorizer(sparse=False)
y = dv.fit_transform(D)
x = dv.feature_names_
print(x)
print(y)
其中sparse代表的是是否生成稀疏矩阵(默认为True)。结果如下:

贝叶斯分类器
在sklearn中提供了多种贝叶斯分类器用于使用,具体使用可以看官方文档。在这里,因为我们的数据是二值化数据(True or False),因此我们使用专门用于二值分类特征的Bernoulli Naive Bayes分类器。
-
如果特征值\(x_i\)值为1,那么\(P\left(x_{i} | y_{k}\right)=P\left(x_{i}=1 | y_{k}\right)\)
-
如果特征值\(x_i\)值为0,那么\(P(x_{i}|y_{k}) = 1-P(x_{i}=1|y_{k})\)
其中1代表这个值出现,0代表没有出现。这个意味着"没有某一个特征也是一个特征"。
综上:
F1 评估
前面博客中我们都是使用accuracy进行评估,但是这里可能会有一个问题,如果我的测试集中100个样本,99个反例,1个正例。这个时候有一个进水了的模型,无论怎样它都将数据预测成反例,那么,\(accuracy = 99\%\)。但是实际上这个模型是个“水”模型,因此我们选择另一个常用的评价指标F1值。
F1值以每个类别为基础进行定义,包括两个概念:
假如我们有一个集合,里面有两个类(苹果100个,梨子100个),假设我们现在以识别苹果为目标,然后识别出了90个苹果和20个梨子。
-
准确率(precision):准确度也就是正确率。
\[正确率 = \frac{90}{90+20} = 0.818 \] -
召回率(recall):召回率是指被正确预测为某个类别的个体数量与数据集中该类别个体总量的比例。
\[召回率 = \frac{90}{100} = 0.9 \]
F1值就是准确率和召回率的调和平均数。
流水线走起
通过前面的操作,我们涉及了:
- 文本布袋模型转化
- 字典转矩阵
- 贝叶斯分类
- F1值评估
流水线的介绍在前面的博客已经介绍过了,这里就不多介绍了。
#流水线
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
pipeline = Pipeline([('布袋模型转换',NLTKBOW()),
('字典列表转矩阵',DictVectorizer(sparse=True)),
('素贝叶斯分类器',BernoulliNB())],
verbose=True
)
scores = cross_val_score(pipeline,data_list,class_list,scoring='f1')
print(scores)
import numpy as np
print("Score: {}".format(np.mean(scores)))
最后的结果如下:
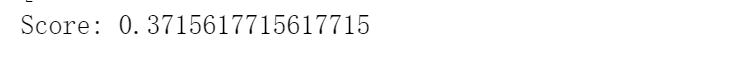
emm,这个也太低了吧,使用accuracy评判评判标准结果如下:
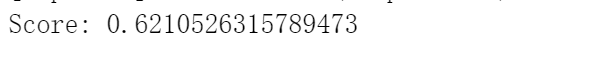
gan!!!训练了个寂寞……
总结
上面之所以预测结果如此之差,主要是因为数据集太少了,才95条数据,如果数据集大一点的话,应该会得到更好的结果。
项目地址:Github
参考
- 带你理解朴素贝叶斯分类算法
- 理解朴素贝叶斯分类的拉普拉斯平滑
- 《机器学习——周志华》
- 《Python数据挖掘入门与实践》
- 使用朴素贝叶斯进行社会媒体挖掘之推特
- 知乎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号