数据挖掘入门系列教程(六)之数据集特征选择
数据挖掘入门系列教程(六)之数据集特征选择
这一篇博客主要来如何介绍从数据集中抽取合适的特征。
我们知道,在数据挖掘中,数据的训练算法很重要,但是同样我们对于数据的前置处理也不可忽视。因为我们对某个数据集的描述是使用特征来表示的。在前面的博客中无论我们是获得商品交易的相关性关系,还是使用决策树去对Iris进行分类,我们都是使用了数据集中所有的特征。但是实际上我们获取的数据真的有这么好吗?
举个例子,我们对西瓜进行分类,但是西瓜的编号实际上与训练毫无关系,因此我们会训练之前将去掉西瓜的编号。我们之所以去掉编号,是因为我们知道这个编号与西瓜的好坏毫无关系。但是如果给你一个陌生的数据集,有着成百上千的特征,我们又如何去除无关的数据特征得到有用的特征然后进行训练?
凭感觉?这里有两个问题:
- 数据集太大,这个太耗费人力
- 如果某个关键的特征取值很相近(或者相同)怎么办
这里说一下第二个问题。举个例子,西瓜的好坏与西瓜的颜色有关,但是如果你的数据集中西瓜的颜色全部一样,你还要不要使用这个特征进行训练呢?
肯定有人说,要!!但是如果这种特征取值相似的特征有1000个,你还要不要呢?在前面的博客中,我们可以看到使用Apriori算法进行计算,一旦\(K\)的值增大,基本上轻薄本就算不动这个数据了!
简介
通过前面的学习我们知道,无论是交易数据,还是Iris数据,他们都是一个一个的实体(视频,声音,文本也是),我们会通过选择一个一个的特征来描述某一个实体,这可以说是建模,同时这个模型的表示能够让数据挖掘的算法能够理解。
如何选择一些好的特征,这个也就是这篇博客要讨论的话题(本篇博客是探讨探讨如何从已有的特征中选择好的特征【也就是简化模型】,而不是自己去从数据集中(比如说声音)去寻找特征)。
这样做有什么好处呢?最简单的一个就是它能够降低真实世界的复杂度。比如说我要描述一个苹果长什么样,我肯定不需要去了解苹果是从哪里买的。但是同样也有缺点,因为我们在简化的过程中,可能会忽略某一些特征,但是这些特征可能刚好有着某一些有用的信息。
特征可以初略的分为两个类型:
- 数值型:数值特征,比如说Iris的花瓣长度是多少等等
- 类别型:类别特征(也可以称之为名义特征)比如说西瓜的颜色是浅绿色还是深绿色
对于数值型特征来说,如果两个特征值相差很小,则可以认为这两个特征很相似,但是对于类别型的特征值而言,没办法说他们是否相似,因为他们要不相同,要不不相同。因为名义特征没办法进行数学上的计算,因此我们可以将它们进行二值化变成数值特征。
同样反过来,数值型特征也可以通过离散化变成类别特征,比如说花瓣长度大于某一个值为类别0,反之则为类别1。但是很明显,这样会丢失一些数据细节。
下面将以不同的数据集为例,介绍一些用来简化模型的算法。
加载数据集Adult
数据集来自这里,同样在我的GIthub中也存在这个数据集。我们下载如下的数据集:
在adult.data中的部分数据如下,每一行代表的是一个人的数据,每一列表示的特征属性值(至于特征是什么,这个在adult.name文件中有介绍):

🆗,现在我们就可以使用python来加载数据集了。使用pandas,这个前面已经介绍了。
import pandas as pd
adult_data = pd.read_csv("Data/adult.data",header=None,names=["age","workclass","fnlwgt","education","education_num","marital-status","occupation","relationship","race","sex","capital-gain","capital-loss","hours-per-week","native-country","money"])
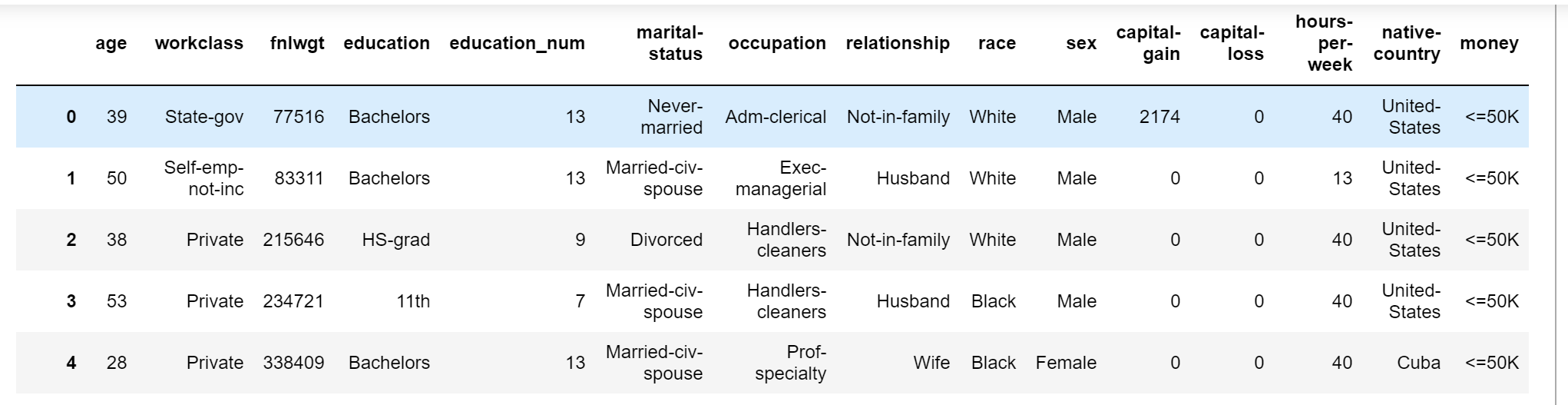
names表示的就是每一个特征的名字。adult_data的数据如下。特征代表什么意思,基本上通过特征名就可以理解了。如果不理解的可以看adult.name文件。最后一个特征为money,他是分类结果,含义是他每年的收入是否大于50K。
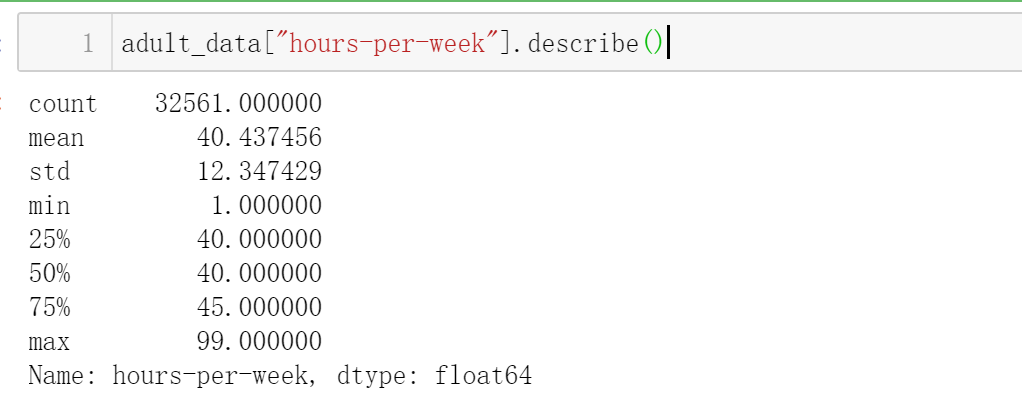
同样我们可以获得某一个特征的一些数学量(比如说平均值,标准差,等等),以hours-per-week为例:
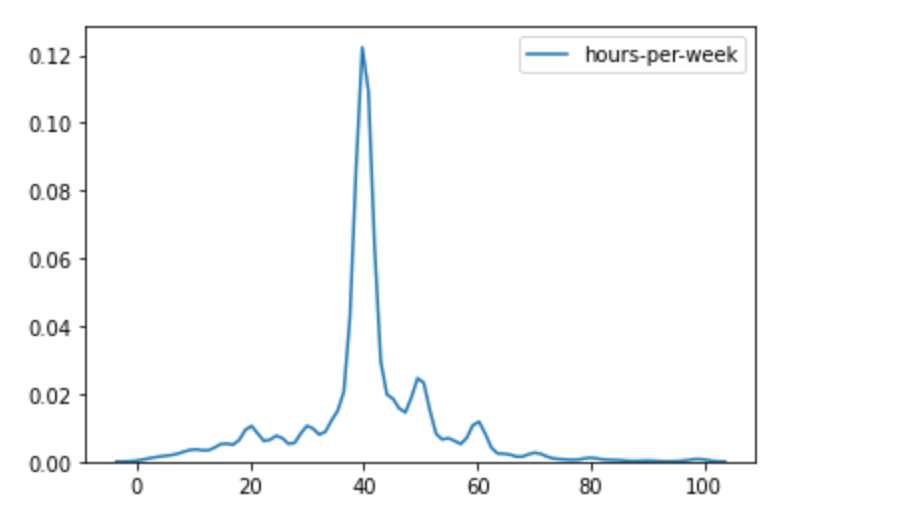
同样我们可以获得方差:

也可以获得方差:

数据分布如下:
同样,我们可以得到某一个特征的所有取值情况,在这里我们查看职业“occupation”的取值有哪一些:

?代表数据缺失。
特征选择
如何选择一个好的特征,这个是一门技术活,同样也是一门艺术活,因为特征的选择不是唯一的,也不是维持不变的,它需要根据我们的需求发生改变。比如说我们判断一个人的成绩好不好,肯定不需要知道他的名字。特征有很多,我们弱水三千,只取一瓢,原因如下:
- 降低复杂度:特征越小,我们耗费的计算时间也就越少。
- 降低噪音:比如说西瓜分类中,西瓜的id就毫无作用。
- 增加模型的可读性。
特征的选择有很多方法,下面介绍一些常用的简单的方法。
方差
我们可以很容易的理解,如果某一个特征的特征值都一样,或者说相互之间都很相似,那么我们可以理解为这个特征并没有提供什么有用的信息给我们,因此我们可以去掉这一个特征。那么如何判断是否特征值是否相似,emm,方差可以做到这个。
在scikit-learn中提供了VarianceThreshold转换器用来去除方差小于某一个阈值的列,具体的使用可以看官网。使用示例如下:
import numpy as np
X = np.arange(30).reshape((10, 3))
创建一个\(10 \times 3\)的矩阵。

然后我们对矩阵进行更改,将第二列的所有值都设为1:
X[:,1] = 1

然后我们使用转换器对数据集进行处理:
from sklearn.feature_selection import VarianceThreshold
# threshold代表的就是阈值,默认是0.0
vt = VarianceThreshold(threshold=0.0)
Xt = vt.fit_transform(X)
转换后的数据如下:

我们可以看到第二列的已经被去除了。
在VarianceThreshold有两个重要的函数:fit和transform,这些说明官网都有,这里稍微的啰嗦以下。fit函数是去计算array的方差,而transform函数就是去转换array数组,将反差小于阈值的去除。
我们可以通过variances_去查看具体的方差是多少。

以上面的adult.data数据为例,我们只使用数值类型数据对money进行预测。
首先,我们使用原始的数据进行预测:
在下面X的数据全部都是数值类型的数据。然后构建一个决策树,然后使用交叉验证得到预测的准确度。
X = adult_data[["age","education_num","capital-gain","capital-loss","hours-per-week"]]
Y = adult_data["money"]
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
dtc = DecisionTreeClassifier(random_state=14)
score = cross_val_score(dtc, X, Y, scoring='accuracy')
score.mean()
结果为:

然后我们使用转换器去除阈值小于200的方差。然后再构建一个决策树。
from sklearn.feature_selection import VarianceThreshold
X = adult_data[["age","education_num","capital-gain","capital-loss","hours-per-week"]].values
Y = adult_data["money"]
vt = VarianceThreshold(threshold=200)
Xt = vt.fit_transform(X)
# 构建决策树
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
dtc = DecisionTreeClassifier(random_state=14)
score = cross_val_score(dtc, Xt, Y, scoring='accuracy')
score.mean()
最后预测的准确度为:
比不处理特征提高了\(2\%\)左右,还行。不错不错~~
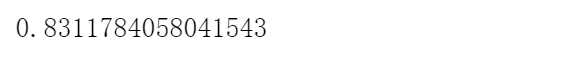
选择最佳特征
如何选择最佳的几个特征,在Apriori算法中我们已经见识到了,同时寻找几个最佳的特征还是挺耗费计算资源的,因此我们可以换一个方向,一次寻找一个特征(单变量),然后再选择几个比较好的特征。
在scikit-learn中提供了几个用于选择单变量特征的选择器。
- SelectKBest:选择k个最佳的特征。
- SelectPercentile:选择最佳的前r%g个特征。
下面将以几个选择方法来举例说明。
卡方验证\(X^2\)(Chi-Square Test)
卡方验证是什么,如果不知道的话非常建议看一看这一位博主的博客:结合日常生活的例子,了解什么是卡方检验。简单点来说,就是可以验证我们的假设是否正确。

计算公式如下:
然后我们就可以根据自由度,\(X^2\),通过卡方表去判断我们假设的置信度。总的来说,\(X^2\)越小(在自由度相同的情况下),表示错误决策假设的概率越低。
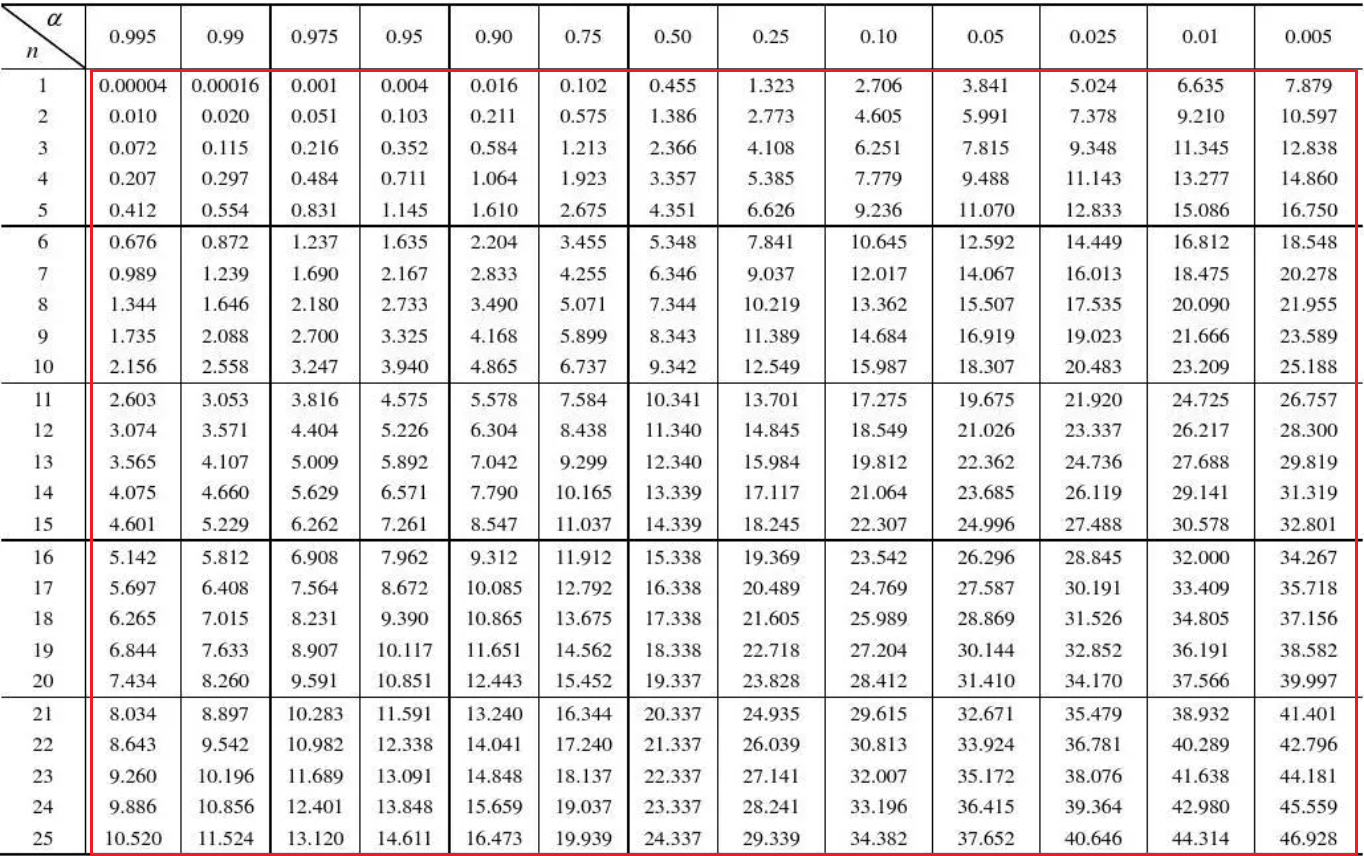
卡方表如下,\(\alpha\)表示的是错误拒绝假设的概率(\(1-\alpha\)也就是假设成立的概率),\(n\)表示的是自由度,红色框框表示就是\(X^2\)
还是以上面的数值型数据举例:
我们使用卡方验证从里面选取前3个最好的特征。在sklearn中的卡方验证,做出的\(H_0\)假设(The null hypothesis)默认代表两个变量之间相互独立(解释来自stackoverflow)。这样也就是说\(X^2\)的值越大也就代表着变量之间越相互依赖,也就是对数据挖掘的作用越大。more userful
X = adult_data[["age","education_num","capital-gain","capital-loss","hours-per-week"]].values
Y = adult_data["money"]
from sklearn.feature_selection import SelectKBest
# 导入卡方验证
from sklearn.feature_selection import chi2
# 选取前3个最好的节点
transformer = SelectKBest(score_func=chi2,k=3)
X_chi2 = transformer.fit_transform(X,Y)
transformer.scores_
卡方验证计算的结果如下:

同样,我们可以得到卡方验证的最大值的三个特征(也就是第1,3,4项特征)去构建决策树。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
dtc = DecisionTreeClassifier(random_state=14)
score = cross_val_score(dtc, X_chi2, Y, scoring='accuracy')
score.mean()
最后的精准度为:

emm,比方差的方法稍微差了一点。
皮尔逊相关系数(Pearson Correlation Coefficient)
皮尔逊相关系数具体是什么可以参考百度百科,或者其他博主的博客。在这里只简单的介绍一下。 皮尔逊系数主要是描述X与Y之间的关系,其值介于\(-1与1\)之间。
- 当相关系数为0时,X和Y两变量无关系。
- 当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
- 当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
计算公式如下:
至于怎么实现这个我们可以使用Scipy库。具体使用如下:
from scipy.stats import pearsonr
def pearsonr_fit(x,y):
scores=[]
p_values = []
for column in range(X.shape[1]):
# cur_p表示的双侧p值,x[:,column]表示的是X中的某一列
# 然后计算X中的某一列与y之间得到关系,返回相关系数和p_value
cur_score,cur_p = pearsonr(x[:,column],y)
# 因为相关系数可能为负数,所以取绝对值
scores.append(abs(cur_score))
p_values.append(cur_p)
return (np.array(scores),np.array(p_values))
然后我们通过调用这个函数就可以获得X中的每一列与y之间的关系,然后返回最佳的几个特征。
import numpy as np
X = adult_data[["age","education_num","capital-gain","capital-loss","hours-per-week"]].values
# 这里不使用">50K"等字符串是因为pearsonr不接受字符串数据。
Y = adult_data["money"] == " >50K"
transformer = SelectKBest(score_func=pearsonr_fit,k=3)
X_pearsonr = transformer.fit_transform(X,Y)
具体的皮尔逊系数如下:

在这里皮尔逊系数越大,代表两个变量越相关,也就是对于数据挖掘越有作用。因此我们选择第1,2,5项特征。
最后构建决策树:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
dtc = DecisionTreeClassifier(random_state=14)
score = cross_val_score(dtc, X_pearsonr, Y, scoring='accuracy')
score.mean()
得到的结果为:

emm,更低了。
PCA 主成分分析
在前面的几个方法中,我们都是从已有的特征中选择最佳的一个(或者几个)特征然后进行数据挖掘进行训练。但是我们没有考虑一个问题,如果特征之间联系紧密怎么办(比如说性别可以由两个特征表示,一个特征表示是否是男的,另外一个特征表示是否是女)?有人会说,这个有什么关系,都进行训练就行了。这样做确实是没有关系,但是我们不得不考虑计算机的计算能力是有限的,如果我们能够使用最少的信息(去除某一些相似的特征)尽可能的描述数据集的特征,这样必将大大的降低数据集的冗余程度。
这里我们使用广告的数据集:http://archive.ics.uci.edu/ml/machine-learning-databases/internet_ads/,同样在我的GIthub中也有这个数据集。稍微的解释一下这个数据集:
这个数据集从0到1557 都是一些网络图像的特征比如说URL,长宽,ALT等等特征(这些特征有很多相似的特征),然后第1558代表着这个图片是不是广告。
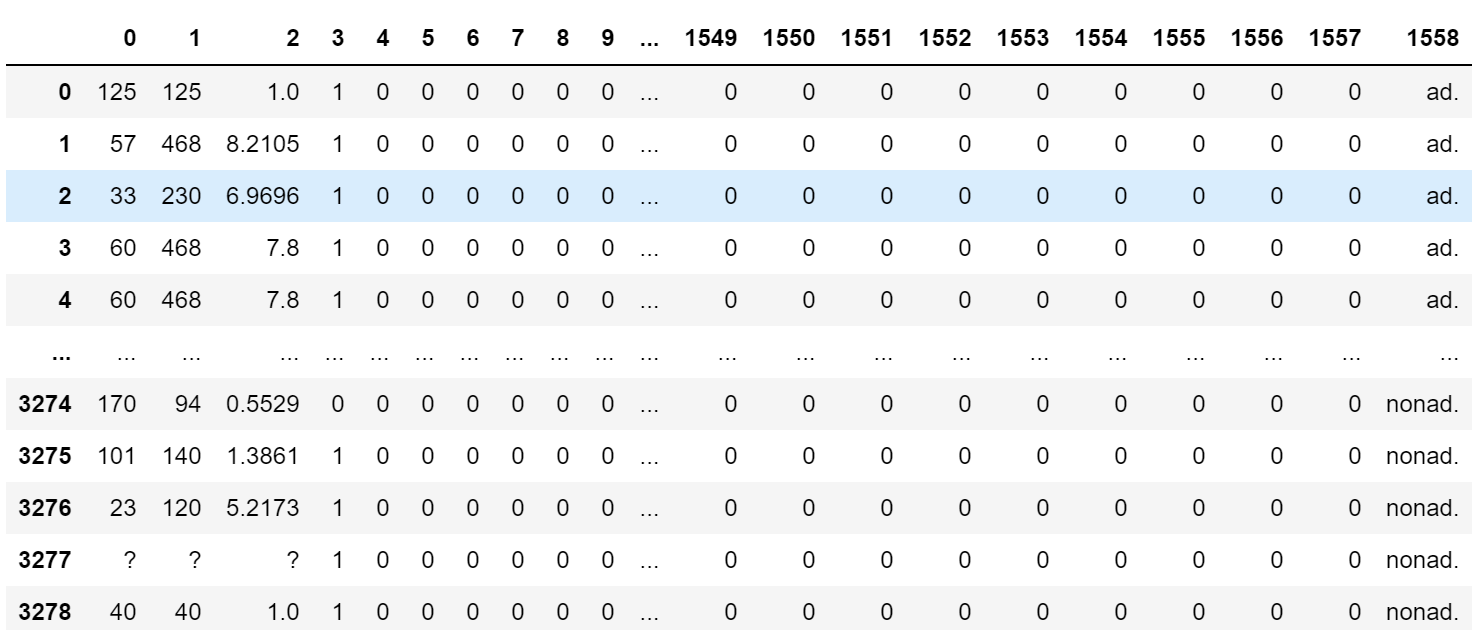
首先我们还是从处理数据集开始:
import pandas as pd
import numpy as np
from collections import defaultdict
def convert_number(x):
try:
return float(x)
except ValueError:
return np.nan
converters = defaultdict()
for i in range(1559 -1):
converters[i] = convert_number
converters[1558] = lambda x:1 if x.strip() == "ad." else 0
ads_data = pd.read_csv("Data/ad.data",header=None,converters=converters)
首先我们将数据从字符串转成float类型,然后将"ad."转换成1代表有广告,0代表没有广告。但是这里有一个问题,那就是在前面的一些特征可能缺失了(使用❓表示),因此我们使用NaN表示缺失的数据。

处理后的数据集如下:
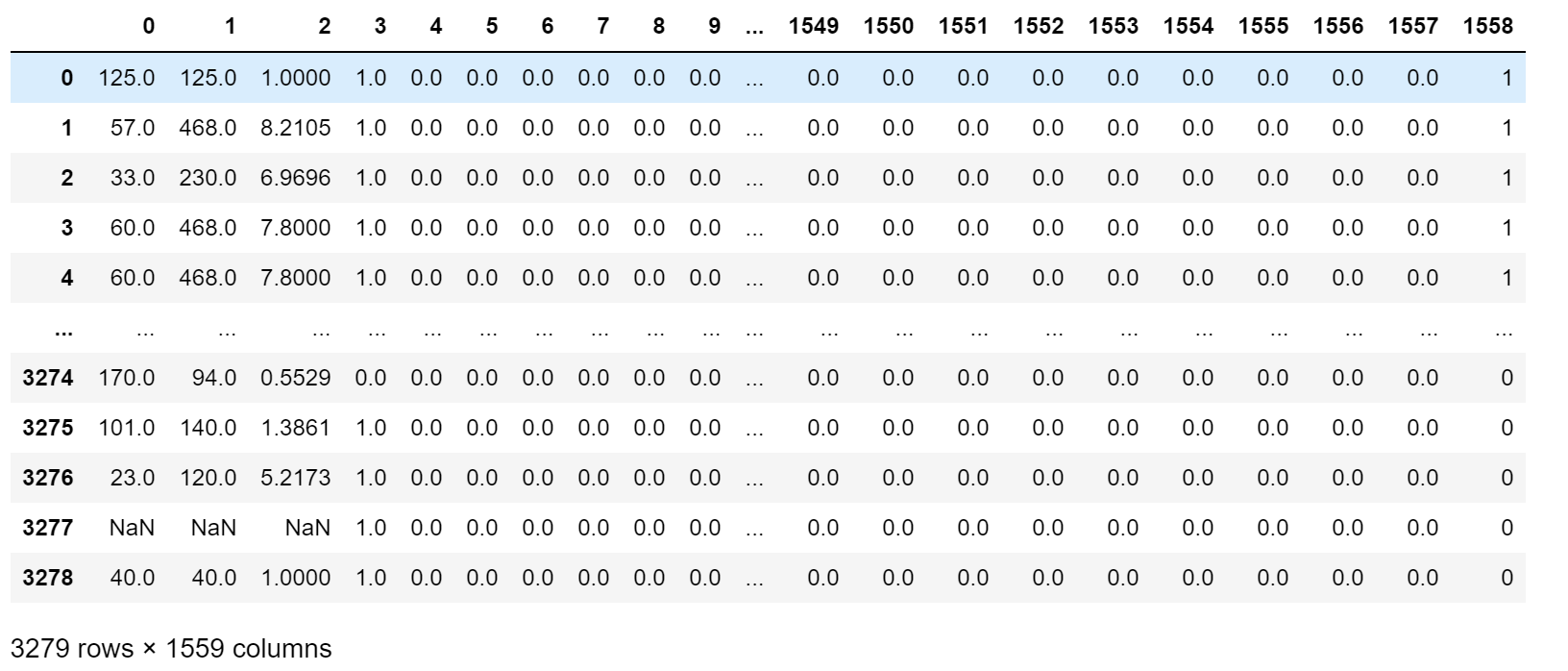
然后我们去除为NaN的数据:
data = ads_data.dropna(axis=0,how='any')
X = data.drop(1558,axis=1).values
Y = data[1558]
取出后的X数据集大小为:

首先我们什么特征都不去除,使用决策树进行预测:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
dtc = DecisionTreeClassifier(random_state=14)
score = cross_val_score(dtc, X, Y, scoring='accuracy')
print("准确度是:{}".format(score.mean()))
结果为:

前面我们介绍过这个ad的数据集里面肯定有很多的冗余信息,那么我们如何去除冗余信息,这里我们选择PCA算法(主成分分析算法Principal Component Analysis),目的是用较少的信息描述数据集的特征组合。具体的PCA算法可以看一下这个博主的博客:主成分分析(PCA)原理详解。
至于使用,我们可以使用sklearn中自带的库进行操作。
from sklearn.decomposition import PCA
# n_components 表示的组成分的数量,默认返回数据集中所有的特征
pca = PCA(n_components=5)
Xd = pca.fit_transform(X)
返回的结果就是主成分,根据方差的大小从大到小排序。方差越大,代表着这个特征越能够解释数据集中的大部分信息。我们可以查看每个特征的方差:
pca.explained_variance_ratio_

其中第一个特征的方差对数据集总体方差的贡献率为\(85.36\%\)。后面的依次递减。
用PCA算法处理数据一个不好的地方在于,得到的主成分往往是其他几个特征的复杂组合,
例如,上述第一个特征就是通过为原始数据集的1558个特征(虽然很多特征值为0)分别乘以不
同权重得到的,前三个特征的权重依次为- 0.092、 - 0.995和- 0.024。经过某种组合得到的特征,
如果没有丰富的研究经验,理解起来很困难。 ——《Python数据挖掘入门与实践》
然后是用决策树进行分类:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
dtc = DecisionTreeClassifier(random_state=14)
score = cross_val_score(dtc, Xd, Y, scoring='accuracy')
print("准确度是:{}".format(score.mean()))
结果为:

比使用所有特征的准确度稍微差了一点(差了约\(0.3 \%\)),但是使用的特征却大大的减少了(一个是使用了1557个特征,一个是只使用了5个特征)。总的来说结果还是不错的。
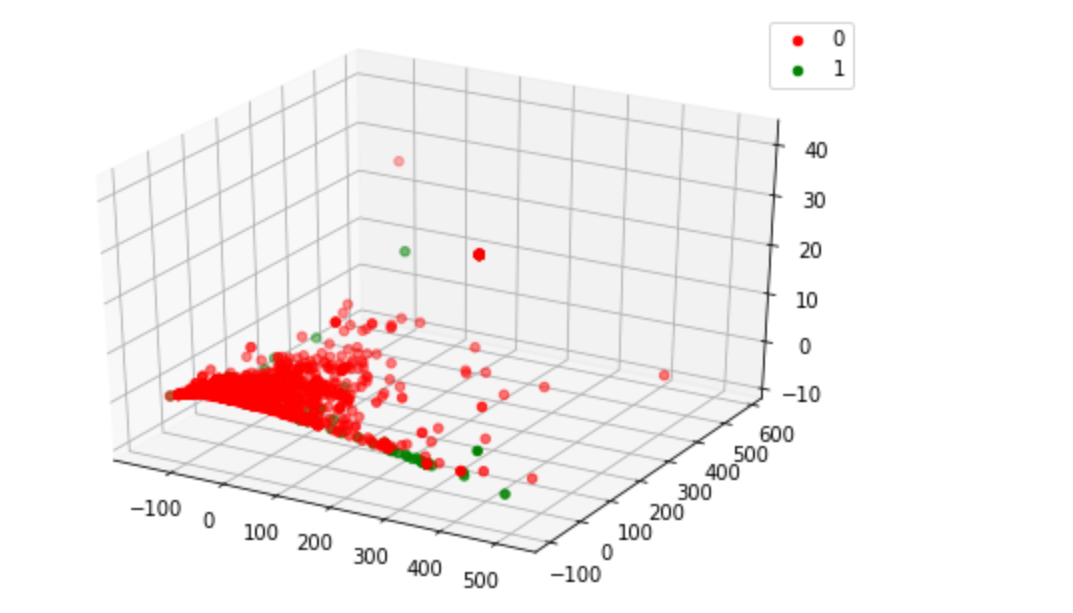
我们也可以通过画图来表示前三个特征与ad和noad的关系:
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
data = ads_data.dropna(axis=0,how='any')
Y = data[1558]
classes = set(Y)
colors = ['red', 'green']
fig = plt.figure()
ax = Axes3D(fig)
for cur_class, color in zip(classes, colors):
mask = (Y == cur_class).values
ax.scatter(Xd[mask,0], Xd[mask,1],Xd[mask,2],color=color, label=int(cur_class),marker='o')
plt.legend()
plt.show()
总结
这篇博客主要是介绍怎么从数据集种提取出好的特征降低数据集的复杂度和冗余度。涉及了:
- 方差
- 卡方验证
- 皮尔逊相关系数
- PCA算法
看起来实现并不难,那是因为有了很多优秀的框架已经帮我们做好了这些事情。这样节约了我们写代码的时间,避免重复造轮子,但是这样并不代表我们会用就行 ,我们真正应该做的是理解里面的原理和背后的数学知识,知其所以然。
项目地址:GitHub
参考:
- 《Python数据挖掘入门与实践》
- 主成分分析(PCA)原理详解
- 百度百科——皮尔森相关系数
- 结合日常生活的例子,了解什么是卡方检验
- Sklearn Chi2 For Feature Selection

 浙公网安备 33010602011771号
浙公网安备 33010602011771号