
GaussDB语法
Sqlserver和Gauss语法区别:
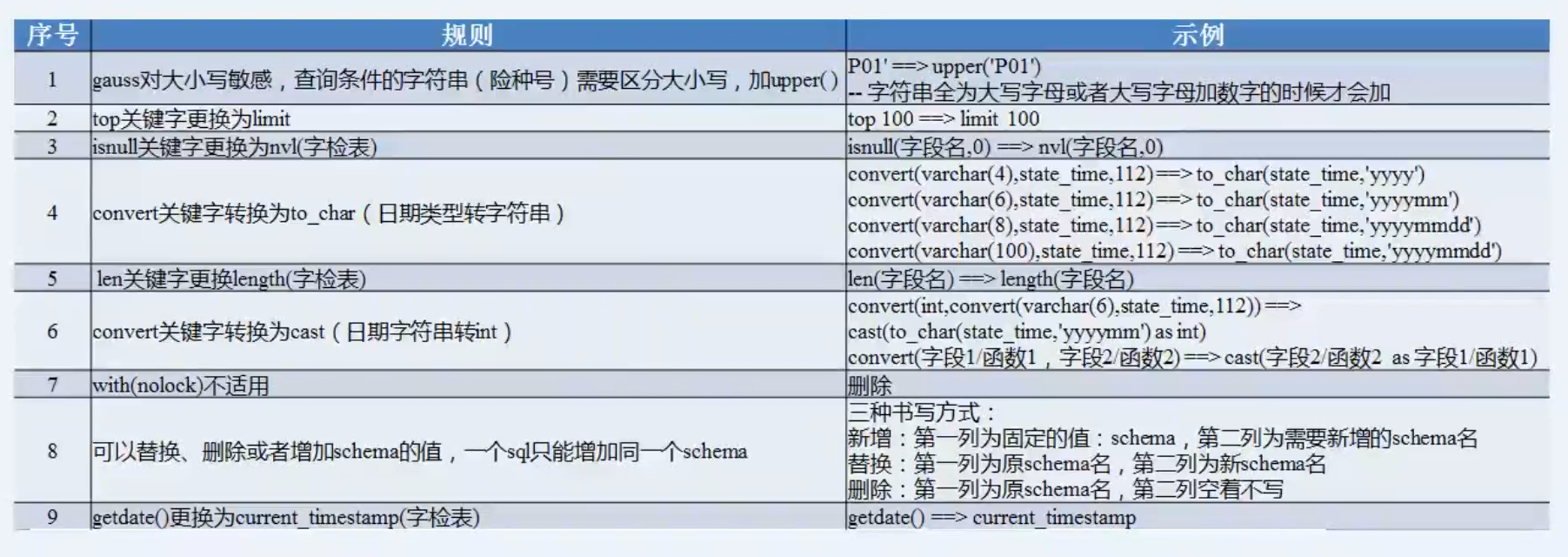
1、创建数据库用户。
CREATE USER joe WITH PASSWORD 'password';
查看所有用户:
SELECT * FROM pg_user;
查看数据库内核版本号:
select version();
2、创建数据库。
CREATE DATABASE mytpcds;
使用以下命令为数据库重新命名:
ALTER DATABASE db_tpcds RENAME TO human_tpcds;
使用\q 命令退出gaussdb数据库。
使用\l 命令查看数据库系统的数据库列表。
查看当前数据库存储编码:
show server_encoding
3、创建schema。
schema又称作模式。通过schema,允许多个用户使用同一数据库而不相互干扰。
GRANT ALL PRIVILEGES TO joe;
将myschema的usage权限赋给用户jack。
GRANT USAGE ON schema myschema TO jack;
将用户jack对于myschema的usage权限收回。
REVOKE USAGE ON schema myschema FROM jack;
如果在创建对象时不指定schema,则会将对象创建在当前的schema下。
查询当前schema的办法为:
show search_path;
查看所有Schema的列表:
SELECT * FROM PG_NAMESPACE;
查看属于某Schema下表的列表:
SELECT distinct(tablename),schemaname FROM PG_TABLES where schemaname = 'pg_catalog';
设置search_path配置参数指定寻找对象可用schema的顺序。在搜索路径列出的第一个schema会变成默认的schema。
SET SEARCH_PATH TO myschema, public;
4、创建表。
在创建对象时指定由“模式名称+对象名称”组成的完整对象名称,中间由符号“.”隔开。CREATE TABLE myschema.mytable (firstcol int);
场景一:若建表时包含主键/唯一约束,则选取HASH分布,分布列为主键/唯一约束对应的列。
场景二:若建表时不包含主键/唯一约束,但存在数据类型支持作分布列的列,则选取HASH分布,分布列为第一个数据类型支持作分布列的列。
场景三:若建表时不包含主键/唯一约束,也不存在数据类型支持作分布列的列,选取ROUNDROBIN分布。
|
分布方式 |
描述 |
适用场景 |
|---|---|---|
|
Hash |
表数据通过Hash方式散列到集群中的所有DN上。 |
数据量较大的事实表。 |
|
Replication |
集群中每一个DN都有一份全量表数据。 |
维度表、数据量较小的事实表。 |
|
Roundrobin |
表的每一行被轮番地发送给各个DN,因此数据会被均匀地分布在各个DN中。 |
数据量较大的事实表,且使用Hash分布时找不到合适的分布列。 |
修改表的分布列为不会更新的列,例如c_customer_sk。
alter table customer_t1 DISTRIBUTE BY hash (c_customer_sk);
5、权限分配。GRANT ... TO 分配,REVOKE ... FROM 收回。
将sysadmin所有可用权限授权给joe用户:
GRANT SELECT ON TABLE tpcds.reason TO joe;
将表tpcds.reason的所有权限授权给用户kim:
GRANT ALL PRIVILEGES ON tpcds.reason TO kim;
将某个库的所有权限授权给用户kim:
GRANT ALL PRIVILEGES ON DATABASE database_name TO kim;
将模式tpcds的使用权限授权给用户joe:
GRANT USAGE ON SCHEMA tpcds TO joe;
将模式tpcds的访问权限授权给角色tpcds_manager,并授予该角色在tpcds下创建对象的权限,不允许该角色中的用户将权限授权给其他人:
GRANT USAGE,CREATE ON SCHEMA tpcds TO tpcds_manager;
将用户manager的权限授权给senior_manager用户:
GRANT manager TO senior_manager;
查询某个用户的表权限:
select * from INFORMATION_SCHEMA.role_table_grants where grantee='testauth2';
6、存储类型。
|
存储类型 |
适用场景 |
|
行存 |
|
|
列存 |
|
行存表
CREATE TABLE默认创建表的类型。数据按行进行存储,即一行数据是连续存储。适用于对数据需要经常增删改的场景。
customer_t1 ( state_ID CHAR(2), state_NAME VARCHAR2(40), area_ID NUMBER );
列存表
数据按列进行存储,即一列所有数据是连续存储的。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询。
COMPRESSION参数指定压缩比,middle是中级别压缩
CREATE TABLE customer_t2 ( state_ID CHAR(2), state_NAME VARCHAR2(40), area_ID NUMBER ) WITH (ORIENTATION = COLUMN,COMPRESSION=middle);
);
7、从指定表插入数据到当前表。
INSERT INTO customer_t2 SELECT * FROM customer_t1;
8、根据查询结果创建一个新表,并且将查询到的数据插入到新表中。
SELECT * INTO tpcds.reason_t1 FROM tpcds.reason
9、字符处理函数
length(string)描述:获取参数string中字符的数目。
concat(str1,str2),等同于 str1||str2。
描述:将字符串str1和str2连接并返回。
lower(string)
描述:把字符串转化为小写。
replace(string text, from text, to text)
描述:把字符串string里出现地所有子字符串from的内容替换成子字符串to的内容。
substring(string [from int] [for int])
描述:截取子字符串,from int表示从第几个字符开始截取,for int表示截取几个字节。
cast('1234' as INTEGER)
描述:转换类型,如:把 string 转为 integer
ifnull(expr1, expr2)
描述:当expr1不为NULL时,返回expr1,否则返回expr2。
nullif(expr1, expr2)
描述:当且仅当expr1和expr2相等时,NULLIF才返回NULL,否则它返回expr1。
10、统计信息收集规则
(1)【建议】在执行了大批量插入/删除操作后,例行对表或全库执行ANALYZE语句更新统计信息。
(2)【强制】对于在批处理脚本或者存储过程中生成的中间临时表,也需要在完 成数据生成之后显式的调用ANALYZE。
(3)【建议】遇到性能问题的时候,建议先判断查询语句涉及的表是否都做了ANALYZE,如果有部分表没有做ANALYZE,需要先对这些表做ANALYZE规避统计信息缺失导致执行计划劣化的因素,然后重跑SQL再进行分析。
11、开发规范
(1)【强制】分布键作为关联条件时禁止带函数。
(2)【强制】表关联字段重复值较少时:执行效率 (join)> (exists)=(in) 尽量使用join来做表关联。
--In子查询 select master_cntr_no from dwd.f_cntr a where prov_branch_code = '110000' and (master_cntr_no, cntr_no) in (select master_cntr_no, cntr_no from dwd.f_cw_prem where prov_branch_code = '110000') --exists子查询 select master_cntr_no from dwd.f_cntr a where prov_branch_code = '110000' and exists(select 1 from dwd.f_cw_prem b where prov_branch_code = '110000' and b.master_cntr_no = a.master_cntr_no and b.cntr_no = a.cntr_no) --join查询 select a.master_cntr_no from dwd.f_cntr a inner join dwd.f_cw_prem b on b.prov_branch_code = a.prov_branch_code and b.master_cntr_no = a.master_cntr_no and b.cntr_no = a.cntr_no where a.prov_branch_code = '110000'
(3)【强制】表关联字段有一定的重复值时,执行效率(exists)=(in)>(join) 尽量用exists 和 in替代join。
(4)【强制】当关联的表字段单值重复过多时,会造成中间结果集的大量翻倍,此时hash关联会有性能压力,还可能导致中间结果集下盘,从而造成大量的内存磁盘交互。
select a.data_src_id, b.prov_branch_code from dwd.f_cntr a inner join dwd.f_cw_prem b on a.data_src_id = b.data_src_id and a.prov_branch_code = b.prov_branch_code group by a.data_src_id, b.prov_branch_code --改写为 select a.data_src_id, b.prov_branch_code from (select data_src_id, prov_branch_code from dwd.f_cntr group by data_src_id, prov_branch_code) a inner join (select data_src_id, prov_branch_code from dwd.f_cw_prem group by data_src_id, prov_branch_code) b on a.data_src_id = b.data_src_id and a.prov_branch_code = b.prov_branch_code group by a.data_src_id, b.prov_branch_code
(5)【强制】任何情况下都不适用not in(子查询) 的方式。
(6)【强制】禁止使用标量子查询。
标量子查询是出现在select语句输出列中的子查询,如下述高亮部分即为一个标量子查询语句:
select id, (select count(*) from films f where f.did = s.id) from staffs_p1 s;
标量子查询往往会对导致SQL性能急剧劣化,在业务开发过程中禁止SQL语句中包含标量子查询。对于业务逻辑需要标量子查询的地方应当对业务进行逻辑的等价转换,把标量子查询改写为表关联。
(7)【强制】尽量使用UNION ALL 来代替UNION
(8)【强制】OR表达式改写UNION ALL
(9)【建议】关键字大写,如SELECT和WHERE,表名字段名小写。
12、查询回话,并强制kill会话
SELECT current_timestamp - query_start AS runtime, datname, usename, query,pid,* FROM pg_stat_activity
where state != 'idle' ORDER BY 1 desc;
根据上面查询出的“query”字段确定是否是要杀掉的sql,
然后使用pg_terminate_backend(‘xxxx’) 入参为上面查询到pid。
13、调用函数或存储过程
CALL [schema.] {func_name| procedure_name} ( param_expr );

 浙公网安备 33010602011771号
浙公网安备 33010602011771号