
Python大数据分析之网络爬虫
一、字符串处理

二、正则表达式
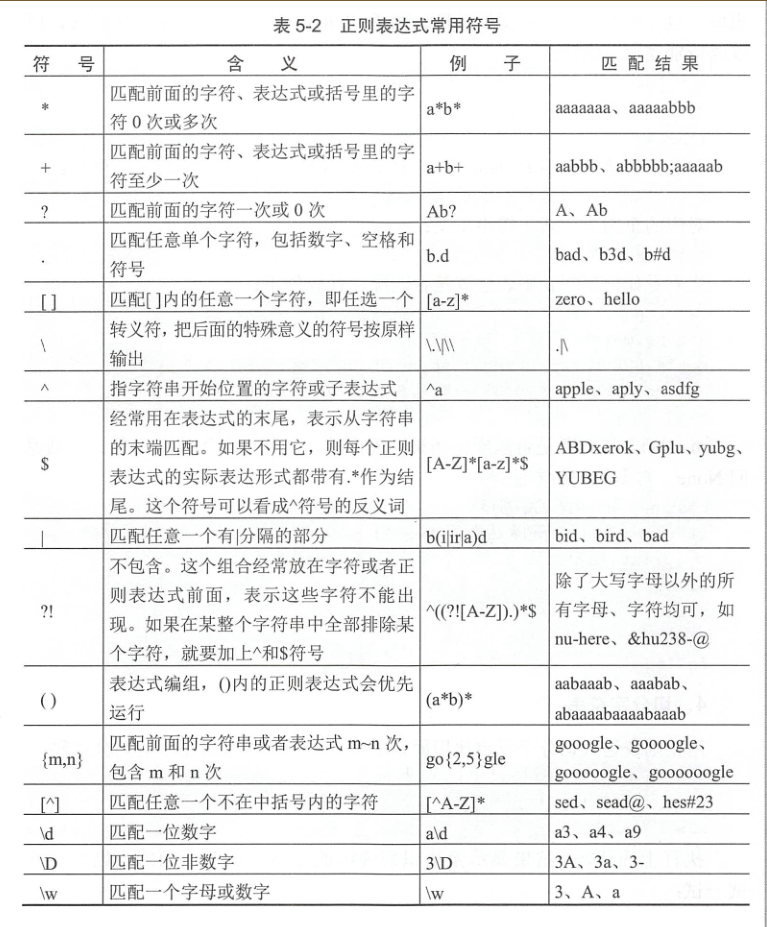
\d匹配一个数字,\D匹配一个非数字,\w匹配一个字母或数字,.可以匹配任意一个字符,*表示任意字符,+表示至少一个字符
?表示0个或1个字符,{n}表示n个字符,用{n,m}表示n~m个字符。
(1)\d{3} 表示匹配3个数字
(2)\s+ 表示至少匹配一个空格 ,\S 表示匹配任何非空白字符
[\s\S]* 可以包括换行符在内的任意字符
(3)\d{3,8}表示匹配3~8个数字
(4)[0-9a-zA-Z\_] 匹配一个数字、字母或者下划线
(5)A|B 匹配A或B
(6)^\d 表示匹配以数字开头
(7)\d$表示匹配以数字结尾
(8)match对象上用group()提取子串,group(0)是原始字符串,group(1)表示第一个子串……

>>> m.groups()
('010', '12345')
(9)正则匹配默认是贪婪匹配,加1个?表示采用非贪婪匹配


(10)如果一个正则表达式要重复使用,出于效率的考虑,可以预编译该正则表达式,接下来重复使用时
就不需要编译了,直接匹配即可。

三、编码处理
a="我叫胡胡"
str_gb2312=a.encode('gb2312') #将str转换为gb2312编码
str_utf8=str_gb2312.decode('gb2312').encode('utf-8') #先解码在编码成utf-8
利用第三方库chardet判断编码格式
import chardet
det=chardet.detect(a)
四、获取网页源码
import requests res=requests.get('http://www.nuc.edu.cn') content=res.text print(type(content))
五、从源码中提取信息
beautifulsoup可以从HTML或XML文件中提取数据,主要功能就是从网页抓取数据。
首先安装该库:pip install beautifulsoup4,还要安装html解释器:pip install lxml,接上面的代码。
from bs4 import BeautifulSoup soup=BeautifulSoup(content,'lxml') print(soup.prettify()) #按html格式打印内容 #从文档中找到所有<a>标签的链接 for a in soup.find_all('a'): print('attrs: ',a.attrs) #取a标签的属性 print('string: ',a.string) #取a标签的字符串 print('---------------') # attrs参数定义一个字典参数来搜索包含特殊属性的tag for tag in soup.find_all(attrs={'class':'menu-link','href':'#'}): print('tag: ',tag.name) print('attrs: ',tag.attrs) print('string: ',tag.string) print('---------------') #找出包含内容为教育部的标签 for tag in soup.find_all(name='a',text='教育部'): print('tag: ',tag.name) print('attrs: ',tag.attrs) print('string: ',tag.string) print('---------------') import re for tag in soup.find_all(attrs={'class':re.compile(r'\w{1,5}-\w{1,5}')}): print(tag) print('---------------')
六、数据存储
(1)保存到csv文件
csv="""id,name,score l,xiaohua,23 2,xiaoming,67 3,xiaogang,89""" with open(r"d:/1.csv",'w') as f: f.write(csv)
(2)保存到数据库
https://www.cnblogs.com/xiaohuhu/p/9387627.html
七、数据挖掘
爬取豆瓣电影top250数据。
import requests from bs4 import BeautifulSoup import re #获取网页源码,生成soup对象 def getSoup(url,headers): res = requests.get(url,headers=headers) return BeautifulSoup(res.text,'lxml') #解析数据 def getData(soup): data=[] ol=soup.find('ol',attrs={'class':'grid_view'}) for li in ol.find_all('li'): tep=[] titles=[] for span in li.find_all('span'): if span.has_attr('class'): if span.attrs['class'][0]=='title': titles.append(span.string.strip()) #获取电影名 elif span.attrs['class'][0]=='rating_num': tep.append(span.string.strip()) #获取评分 elif span.attrs['class'][0]=='inq': tep.append(span.string.strip()) #获取评论 tep.insert(0,titles) data.append(tep) print(tep) print("-------------") print(data) print("=============") return data #获取下一页链接 def nextUrl(soup): a=soup.find('a',text=re.compile('^后页')) if a: return a.attrs['href'] else: return None if __name__ == '__main__': headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"} url="https://movie.douban.com/top250" soup=getSoup(url,headers) data=getData(soup) print(data) nt=nextUrl(soup) while nt: soup=getSoup(url+nt,headers) print(getData(soup)) nt=nextUrl(soup)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号