

数据采集实践学习二(C#)
前一篇文章写到我获取数据的方式不是通过分析HTML获得,而是通过分析请求链接,然后模拟请求方法获取数据,这只是一种方法。而且是在我通过分析HTML获取不到的情况下,曲线救国,参考别人文章实现的。很高兴,我实现了自己获取数据的目标。我以为这样就算结束了。可是,今天又发现了另外一种方法,而且是通过分析HTML实现的,看到它,我感觉太不可思议了,我花了那么多的时间都没有实现,怎么现在又可以了。现在兴趣正浓,赶紧操刀实践一番。于是有了这篇,算是意外之喜吧!
先说明一下实现思路,原来它是通过调用WebBrowser控件来实现的。怪不得它可以获取HTML,然后分析获取数据。管你什么动态解析,ajax,现在我是浏览器行为了,所有的都逃不过我的法眼。真的是不错的选择方式。
说明一下,包含三个地方。
一个解析获取解析HTML类,一个事件类,一个调用的地方。上次我是拿那个情趣网站实验,结果大家都说我好污,好污,其实我是一个好人,一个让大家都有动力兴趣的好人,代码写累了,看看图片,又鸡血了,我不信大家对美图不感兴趣。学习与欢乐同行,自娱自乐。好了,这次避免大家的想法,我拿我们的博客园实验,我只是获取前面三个页面,太多了也是一样的效果,没有必要,说明方法可行就可以了。
开始代码吧
一个解析类

using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading; using System.Threading.Tasks; using System.Windows.Forms; namespace WebBrowserCrawlerdemo { //这种感觉只适合单个页面数据抓取//可以抓取多个页面如博客园的数据 //http://www.cnblogs.com/rookey/p/5019090.html /// <summary> /// 通过WebBrowser抓取网页数据 /// WebBrowserCrawler webBrowserCrawler=new WebBrowserCrawler(); /// 示例:File.WriteAllText(Server.MapPath("sample.txt"),webBrowserCrawler.GetReult(http://www.in2.cc/sample/waterfalllab.htm)); /// </summary> public class WebBrowserCrawler { // WebBrowser private WebBrowser _WebBrowder; //最後結果 private string _Result { get; set; } //網址 private string _Path { get; set; } //当一直在抓取资料,允许等待的的最大秒数,超时时间(秒) private int _MaxWaitSeconds { get; set; } public delegate bool MyDelegate(object sender, TestEventArgs e); /// <summary> /// 是否达到停止加载条件 /// </summary> public event MyDelegate IsStopEvent; /// <summary> /// 對外公開的Method /// </summary> /// <param name="url">URL Path</param> /// <param name="maxWaitSeconds">最大等待秒数</param> /// <returns></returns> public string GetReult(string url, int maxWaitSeconds = 60) { _Path = url; _MaxWaitSeconds = maxWaitSeconds <= 0 ? 60 : maxWaitSeconds; var mThread = new Thread(FatchDataToResult); //Apartment 是處理序當中讓物件共享相同執行緒存取需求的邏輯容器。 同一 Apartment 內的所有物件都能收到 Apartment 內任何執行緒所發出的 //.NET Framework 並不使用 Apartment;Managed 物件必須自行以安全執行緒 (Thread-Safe) 的方式運用一切共 //因為 COM 類別使用 Apartment,所以 Common Language Runtime 在 COM Interop 的狀況下呼叫出 COM 物件時必須建立 Apartment 並且加以初 //Managed 執行緒可以建立並且輸入只容許一個執行緒的單一執行緒 Apartment (STA),或者含有一個以上執行緒的多執行緒 Apartment (MT //只要把執行緒的 ApartmentState 屬性設定為其中一個 ApartmentState 列舉型別 (Enumeration),即可控制所建立的 Apartment 屬於哪種 //因為特定執行緒一次只能初始化一個 COM Apartment,所以第一次呼叫 Unmanaged 程式碼之後就無法再變更 Apartment //From : http://msdn.microsoft.com/zh-tw/library/system.threading.apartmentstate. mThread.SetApartmentState(ApartmentState.STA); mThread.Start(); mThread.Join(); return _Result; } /// <summary> /// Call _WebBrowder 抓取資料 /// For thread Call /// </summary> private void FatchDataToResult() { _WebBrowder = new WebBrowser(); _WebBrowder.ScriptErrorsSuppressed = true; _WebBrowder.Navigate(_Path); DateTime firstTime = DateTime.Now; //處理目前在訊息佇列中的所有 Windows //如果在程式碼中呼叫 DoEvents,您的應用程式就可以處理其他事件。例如,如果您的表單將資料加入 ListBox 並將 DoEvents 加入程式碼中,則當另一個視窗拖到您的表單上時,該表單將重 //如果您從程式碼移除 DoEvents,您的表單將不會重新繪製,直到按鈕按一下的事件處理常式執 //通过不断循环把整个页面都加载完,然后从中获取自己想要的信息。可以结合这个JumonyParser一起用 while ((DateTime.Now - firstTime).TotalSeconds <= _MaxWaitSeconds) { if (_WebBrowder.Document != null && _WebBrowder.Document.Body != null && !string.IsNullOrEmpty(_WebBrowder.Document.Body.OuterHtml) && this.IsStopEvent != null) { string html = _WebBrowder.Document.Body.OuterHtml; bool rs = this.IsStopEvent(null, new TestEventArgs(html)); if (rs) { this._Result = html; break; } } Application.DoEvents(); } _WebBrowder.Dispose(); } } }
事件类
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace WebBrowserCrawlerdemo { public class TestEventArgs:EventArgs { public string Html { get; set; } public TestEventArgs(string html2) { this.Html = html2; } } }
调用端 先来一个界面吧
代码
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.IO; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; namespace WebBrowserCrawlerdemo { public partial class Form1 : Form { public Form1() { InitializeComponent(); } public void test(int num) { WebBrowserCrawler obj = new WebBrowserCrawler(); obj.IsStopEvent += new WebBrowserCrawler.MyDelegate((sender, e) => { //当前html中已经加载了我想要的数据,返回true// //return e.Html.Contains("<div id=\"post_list\">"); return e.Html.Contains("<div class=\"post_item\">"); }); string url = string.Format("http://www.cnblogs.com/#p{0}", num); string html = obj.GetReult(url); //获取采集的数据 if (!string.IsNullOrEmpty(html)) { //处理数据 Write(html); } } private void btntest_Click(object sender, EventArgs e) { for (int i = 1; i < 4; i++) { test(i); } } //http://www.cnblogs.com/akwwl/p/3240813.html public void Write( string html) { string path = @"D:\练习\MyPictureDownloader\WebBrowserCrawlerdemo\bin\Debug\test\test.txt"; FileStream fs = new FileStream(path, FileMode.Append); //获得字节数组 byte[] data = System.Text.Encoding.Default.GetBytes(html); //开始写入 fs.Write(data, 0, data.Length); //清空缓冲区、关闭流 fs.Flush(); fs.Close(); } } }
说明一下,我数据是保存到TXT文件里,没有去分析什么目标数据了,只要整个页面获取就可以了,我是通过追加的形式保存的。
e.Html.Contains("<div id=\"post_list\">"); 分析为啥不是这个,我用它结果获取不到数据。原来是这样的。
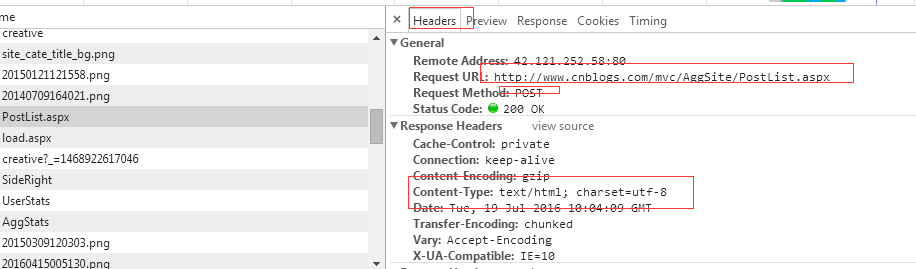
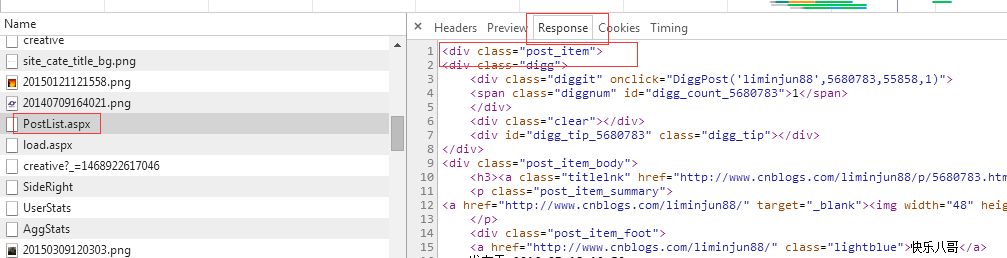
返回的是html元素格式,通过它,请求都还没有结束,没有获取到数据,肯定不行了。于是改成上面那个了。可以获取数据。
结果如图,我只有获取三页因此三个<body>标签,我也检验对比了,事实就是三页的数据。
如果你还想获取目标数据,可以借助一些HTML分析类如: Jumony,HtmlAgilityPack。
好了,已经下班了。内容也介绍完了。
参考:
http://www.cnblogs.com/rookey/p/5019090.html
http://www.cnblogs.com/akwwl/p/3240813.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?