NeurIPS2018: DropBlock: A regularization method for convolutional networks
NIPS 改名了!改成了neurips了。。。
深度神经网络在过参数化和使用大量噪声和正则化(如权重衰减和 dropout)进行训练时往往性能很好。dropout 广泛用于全连接层的正则化,但它对卷积层的效果没那么好。原因可能在于卷积层中的激活单元是空间关联的,使用 dropout 后信息仍然能够通过卷积网络传输到下一层。相比于dropout一个一个扔掉神经元,自然而然我们就要成块成块扔。因此就产生了这种叫dropblock的方法来对卷积网络进行正则化约束,它会丢弃特征图相邻区域中的单元。此外,在训练过程中逐渐增加丢弃单元的数量会带来更高的准确率,使模型对超参数选择具备更强的鲁棒性。
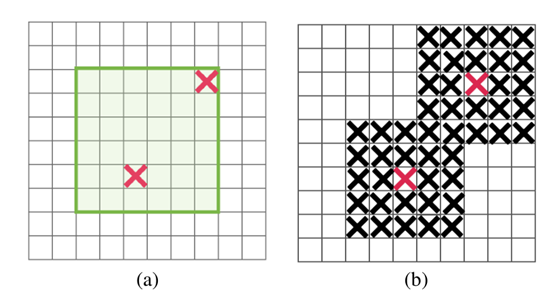
如下图更加形象生动:

图(a)中图片狗的区域是包含语义信息的,(b)中dropout扔神经元基本是这样随机扔,这就导致了很多狗这个实例的相关性信息被保存下来了,如(c), dropblock的思想是随机找一些点,然后自定义一个区域(block)把这里的信息一股脑全扔了。这样语义信息就不会冗余,从一定程度上使学习到的特征更加鲁棒。
如何操作:
block_size: 控制block的区域大小
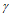 : 控制丢掉多少神经元,注意这里的神经元不是真正丢了,而是某一次不用它的概率。
: 控制丢掉多少神经元,注意这里的神经元不是真正丢了,而是某一次不用它的概率。

参数设置:
Blocksize设置为1的时候和dropout类似,但是只在图中绿色区域丢
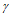 设置:
设置:
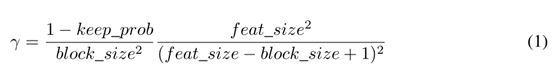
Keep_prob 为保存信息的比率
feat_size 为整个feature map的大小
feat_size-block_size+1 为绿色区域的大小,我把它命名为语义信息区域吧。。
我的想法:
读了这篇文章,我倒是有些想法,我们的目标不是去除图像像素之间的冗余特征吗,那么我们根据这样一句话:
the m best features are not the best m features....在卷积层与全连接层的中间加一个去冗余层。
扔特征的目标是不是就是找出含有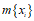 个特征的特征子集S?其实相对于也是丢弃一部分特征
个特征的特征子集S?其实相对于也是丢弃一部分特征
那我们这样:
1:与标签的最大相关性:
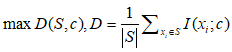 (2)
(2)
C为类别,S 为特征子集,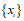 为第i个特征。
为第i个特征。
变量间的最小冗余度:
 (3)
(3)
其中I函数为给定两个随机变量x和y,他们的概率密度函数(对应于连续变量)为p(x),p(y),p(x,y)p(x),p(y),p(x,y),则互信息为 :
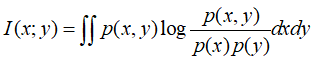
那么我们整个神经网络优化公式为:
传统损失 - 公式(2)+公式(3)
当然上面思想主要来自于mrmr算法,正好可以结合卷积来做一下。一点初步的idea,有空实现下,在来分享。

