CVPR 2018paper: DeepDefense: Training Deep Neural Networks with Improved Robustness第一讲
前言:好久不见了,最近一直瞎忙活,博客好久都没有更新了,表示道歉。希望大家在新的一年中工作顺利,学业进步,共勉!
今天我们介绍深度神经网络的缺点:无论模型有多深,无论是卷积还是RNN,都有的问题:以图像为例,我们人为的加一些东西,然后会急剧的降低网络的分类正确率。比如下图:

在生成对抗样本之后,分类器把alps 以高置信度把它识别成了狗,下面的一幅图,是把puffer 加上一些我们人类可能自己忽视的东西,但是对分类器来说,这个东西可能很重要,这样分类器就会去调节它,这就导致分类器以百分之百的置信度把puffer 分类成crab.
Adversarial examples 是在这篇文章首次提出的,Intriguing properties of neural networks (大家可以下载看看原文)官方话就是:在数据集中通过故意添加细微的干扰所形成输入样本,受干扰之后的输入导致模型以高置信度给出了一个错误的输出。 注意细微的干扰,也就是这种干扰对于人眼是可以忽略的,这才叫细微的干扰。
是啥子原因导致对抗样本呢?
对于这个,我感觉主要是判别模型的弊端引起的,无论是神经网络,也无论这个层数有多深,或者是SVM。分类的核心思想都是一个扩大不同样本之间边界的范围。下图:
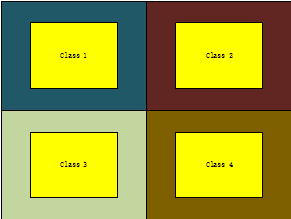
其实本来分类空间,class 1-4是黄色的区域,但是为了扩大与边界的距离,他会扩大每个class的范围,这样做的好处是可以让分类器更加容易得分类,但是坏处就是扩充了很多本不属于这个类别的区域。生成模型是根据y 生成一个p(X/y),这个p(X)可以计算得出,当然生成的p(X)越大越好。。。如果很低的话,模型依然可以正确分类的。对抗样本问题的存在,所以本质上是判别模型的缺陷。大家都知道神经网络是一个判别模型,本质上就是有个超复杂的决策超平面,把数据分开,目标是分类的错误率最低,也就是最小化经验风险,但是这个过程中并没有对每一个label本身建模,只是在几乎无限大的输入空间中构建了一个超复杂的决策超平面,这就导致了现有的正常数据只要偏移一点点(这个偏移一点点的度是很难把握的,因为有时候如果模型对某一个区域不敏感,你就算改变了很多,依然是没有效果的,也就是之前p(X)很小的情况),稍微超越决策边界,就会导致完全不同的结果,也就是被"欺骗"了。而人类大脑是对物体本身的生成式(generative)建模,稍微改变一点不会被欺骗。这也就是为什么有的大牛说神经网络不是模型(model),是一个分类器(classifier),因为它并不是一个建模(modelling)的过程,不理解数据是怎么产生的。
什么是攻击网络?那所谓的白盒攻击和黑盒攻击究竟又是什么呢?
攻击网络就是人为的根据网络的输入形式,然后输入相似的数据让网络判断错误。
白盒攻击:其实和软件工程里的白盒测试相类似,只是这里知道的是整个网络的模型和参数。
黑盒测试:就是不知道网络的模型以及参数,只知道输入和输出,这样通过输入与输出的关系去猜测网络的结构。
今天就讲到这里是一些基础性的介绍,下一张我们来详细的介绍CVPR 2018上的这篇文章,深度防御。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号