

面试题-八股文
前言
今天为大家整理了目前互联网出现率最高的大厂面试题,所谓八股文也就是指文章的八个部分,文体有固定格式:由破题、承题、起讲、入题、起股、中股、后股、束股八部分组成,题目一律出自四书五经中的原文。
而JAVA面试八股文也就是为了考验大家的JAVA基础功底,所以强烈建议背诵全文。****
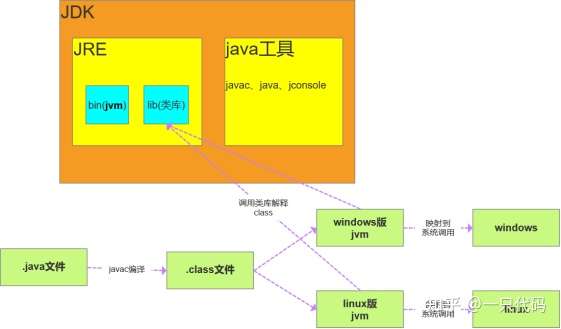
1、JDK JRE JVM
JDK:Java Develpment Kit java 开发工具
JRE:Java Runtime Environment
java运行时环境JVM:java Virtual Machine java 虚拟机
2、==和equals比较
==对比的是栈中的值,基本数据类型是变量值,引用类型是堆中内存对象的地址
equals:object中默认也是采用==比较,通常会重写Object
public boolean equals(Object obj) { return (this == obj); }
String
public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
上述代码可以看出,String类中被复写的equals()方法其实是比较两个字符串的内容。
public class StringDemo { public static void main(String args[]) { String str1 = "Hello"; String str2 = new String("Hello"); String str3 = str2; // 引用传递 System.out.println(str1 == str2); // false System.out.println(str1 == str3); // false System.out.println(str2 == str3); // true System.out.println(str1.equals(str2)); // true System.out.println(str1.equals(str3)); // true System.out.println(str2.equals(str3)); // true } }
3、hashCode与equals
hashCode介绍:
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,Java中的任何类都包含有hashCode() 函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用 到了散列码!(可以快速找到所需要的对象)
为什么要有hashCode:
以“HashSet如何检查重复”为例子来说明为什么要有hashCode:
对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,看该位置是否有 值,如果没有、HashSet会假设对象没有重复出现。但是如果发现有值,这时会调用equals()方法来 检查两个对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样就大大减少了equals的次数,相应就大大提高了执行速度。
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个 对象无论如何都不会相等(即使这两个对象指向相同的数据)
4、final
最终的
- 修饰类:表示类不可被继承
- 修饰方法:表示方法不可被子类覆盖,但是可以重载
- 修饰变量:表示变量一旦被赋值就不可以更改它的值。
(1) 修饰成员变量
- 如果final修饰的是类变量,只能在静态初始化块中指定初始值或者声明该类变量时指定初始值。
- 如果final修饰的是成员变量,可以在非静态初始化块、声明该变量或者构造器中执行初始值。
(2) 修饰局部变量
系统不会为局部变量进行初始化,局部变量必须由程序员显示初始化。因此使用final修饰局部变量时, 即可以在定义时指定默认值(后面的代码不能对变量再赋值),也可以不指定默认值,而在后面的代码 中对final变量赋初值(仅一次)
public class FinalVar { final static int a = 0;//再声明的时候就需要赋值 或者静态代码块赋值 /** static{ a = 0; } */ final int b = 0;//再声明的时候就需要赋值 或者代码块中赋值 或者构造器赋值 /*{ b = 0; }*/ public static void main(String[] args) { final int localA; //局部变量只声明没有初始化,不会报错,与final无关。localA = 0;//在使用之前一定要赋值 //localA = 1; 但是不允许第二次赋值 } }
(3) 修饰基本类型数据和引用类型数据
- 如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;
- 如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。但是引用的值是可变的。
public class FinalReferenceTest{ public static void main(){ final int[] iArr={1,2,3,4}; iArr[2]=-3;//合法 iArr=null;//非法,对iArr不能重新赋值 final Person p = new Person(25); p.setAge(24);//合法 p=null;//非法 } }
为什么局部内部类和匿名内部类只能访问局部final变量?
编译之后会生成两个class文件,Test.class Test1.class
public class Test { public static void main(String[] args) { } //局部final变量a,b public void test(final int b) {//jdk8在这里做了优化, 不用写,语法糖,但实际上也是有的,也不能修改 final int a = 10; //匿名内部类new Thread(){ public void run() { System.out.println(a); System.out.println(b); }; }.start(); } } class OutClass { private int age = 12; public void outPrint(final int x) { class InClass { public void InPrint() { System.out.println(x); System.out.println(age); } } new InClass().InPrint(); } }
5、String、StringBuffer、StringBuilder
String是final修饰的,不可变,每次操作都会产生新的String对象StringBuffer和StringBuilder都是在原对象上操作
StringBuffer是线程安全的,StringBuilder线程不安全的
StringBuffer方法都是synchronized修饰的性能:StringBuilder > StringBuffer > String
场景:经常需要改变字符串内容时使用后面两个
优先使用StringBuilder,多线程使用共享变量时使用StringBuffer
6、重载和重写的区别
重载: 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写: 发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类就不能重写该方法。
public int add(int a,String b) public String add(int a,String b) //编译报错
7、接口和抽象类的区别
- 抽象类可以存在普通成员函数,而接口中只能存在public abstract 方法。
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的。
- 抽象类只能继承一个,接口可以实现多个。
接口的设计目的,是对类的行为进行约束(更准确的说是一种“有”约束,因为接口不能规定类不可以有 什么行为),也就是提供一种机制,可以强制要求不同的类具有相同的行为。它只约束了行为的有无, 但不对如何实现行为进行限制。
而抽象类的设计目的,是代码复用。当不同的类具有某些相同的行为(记为行为集合A),且其中一部分行为的实现方式一致时(A的非真子集,记为B),可以让这些类都派生于一个抽象类。在这个抽象类中实 现了B,避免让所有的子类来实现B,这就达到了代码复用的目的。而A减B的部分,留给各个子类自己 实现。正是因为A-B在这里没有实现,所以抽象类不允许实例化出来(否则当调用到A-B时,无法执行)。
抽象类是对类本质的抽象,表达的是 is a 的关系,比如: BMW is a Car 。抽象类包含并实现子类的通用特性,将子类存在差异化的特性进行抽象,交由子类去实现。
而接口是对行为的抽象,表达的是 like a 的关系。比如: Bird like a Aircraft (像飞行器一样可以飞),但其本质上 is a Bird 。接口的核心是定义行为,即实现类可以做什么,至于实现类主体是谁、是如何实现的,接口并不关心。
使用场景:当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。
抽象类的功能要远超过接口,但是,定义抽象类的代价高。因为高级语言来说(从实际设计上来说也 是)每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。虽然接口在功 能上会弱化许多,但是它只是针对一个动作的描述。而且你可以在一个类中同时实现多个接口。在设计 阶段会降低难度
8、List和Set的区别
- List:有序,按对象进入的顺序保存对象,可重复,允许多个Null元素对象,可以使用Iterator取出 所有元素,在逐一遍历,还可以使用get(int index)获取指定下标的元素
- Set:无序,不可重复,最多允许有一个Null元素对象,取元素时只能用Iterator接口取得所有元 素,在逐一遍历各个元素
9、ArrayList和LinkedList区别
ArrayList:基于动态数组,连续内存存储,适合下标访问(随机访问),扩容机制:因为数组长度固 定,超出长度存数据时需要新建数组,然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会 涉及到元素的移动(往后复制一份,插入新元素),使用尾插法并指定初始容量可以极大提升性能、甚 至超过linkedList(需要创建大量的node对象)
LinkedList:基于链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询:需要逐一遍历
遍历LinkedList必须使用iterator不能使用for循环,因为每次for循环体内通过get(i)取得某一元素时都需 要对list重新进行遍历,性能消耗极大。
另外不要试图使用indexOf等返回元素索引,并利用其进行遍历,使用indexlOf对list进行了遍历,当结 果为空时会遍历整个列表。
10、HashMap和HashTable有什么区别?其底层实现是什么?
区别 :
(1) HashMap方法没有synchronized修饰,线程非安全,HashTable线程安全;
(2) HashMap允许key和value为null,而HashTable不允许
2.底层实现:数组+链表实现
jdk8开始链表高度到8、数组长度超过64,链表转变为红黑树,元素以内部类Node节点存在
- 计算key的hash值,二次hash然后对数组长度取模,对应到数组下标,
- 如果没有产生hash冲突(下标位置没有元素),则直接创建Node存入数组,
- 如果产生hash冲突,先进行equal比较,相同则取代该元素,不同,则判断链表高度插入链表,链表高度达到8,并且数组长度到64则转变为红黑树,长度低于6则将红黑树转回链表
- key为null,存在下标0的位置
数组扩容
11、ConcurrentHashMap原理,jdk7和jdk8版本的区别
数据结构:ReentrantLock+Segment+HashEntry,一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表结构
元素查询:二次hash,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部
锁:Segment分段锁 Segment继承了ReentrantLock,锁定操作的Segment,其他的Segment不受影响,并发度为segment个数,可以通过构造函数指定,数组扩容不会影响其他的segment
get方法无需加锁,volatile保证jdk8:
数据结构:synchronized+CAS+Node+红黑树,Node的val和next都用volatile修饰,保证可见性
查找,替换,赋值操作都使用CAS
锁:锁链表的head节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时,阻塞所有的读写操作、并发扩容
读操作无锁:
Node的val和next使用volatile修饰,读写线程对该变量互相可见数组用volatile修饰,保证扩容时被读线程感知
12、什么是字节码?采用字节码的好处是什么?
java中的编译器和解释器:
Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。
编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系 统的机器码执行。在Java中,这种供虚拟机理解的代码叫做 字节码(即扩展名为 .class的文件),它不面向任何特定的处理器,只面向虚拟机。
每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java源程序经过编译器编译后变成字节 码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机 器上的机器码,然后在特定的机器上运行。这也就是解释了Java的编译与解释并存的特点。
Java源代码---->编译器---->jvm可执行的Java字节码(即虚拟指令)---->jvm---->jvm中解释器 >机器可执
行的二进制机器码 >程序运行。
采用字节码的好处:
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器, 因此,Java程序无须重新编译便可在多种不同的计算机上运行。
13、Java中的异常体系
Java中的所有异常都来自顶级父类Throwable。Throwable下有两个子类Exception和Error。
Error是程序无法处理的错误,一旦出现这个错误,则程序将被迫停止运行。
Exception不会导致程序停止,又分为两个部分RunTimeException运行时异常和CheckedException检 查异常。
RunTimeException常常发生在程序运行过程中,会导致程序当前线程执行失败。CheckedException常常发生在程序编译过程中,会导致程序编译不通过。
14、Java类加载器
JDK自带有三个类加载器:bootstrap ClassLoader、ExtClassLoader、AppClassLoader。
BootStrapClassLoader是ExtClassLoader的父类加载器,默认负责加载%JAVA_HOME%lib下的jar包和class文件。
ExtClassLoader是AppClassLoader的父类加载器,负责加载%JAVA_HOME%/lib/ext文件夹下的jar包和class类。
AppClassLoader是自定义类加载器的父类,负责加载classpath下的类文件。系统类加载器,线程上下 文加载器
继承ClassLoader实现自定义类加载器
15、双亲委托模型
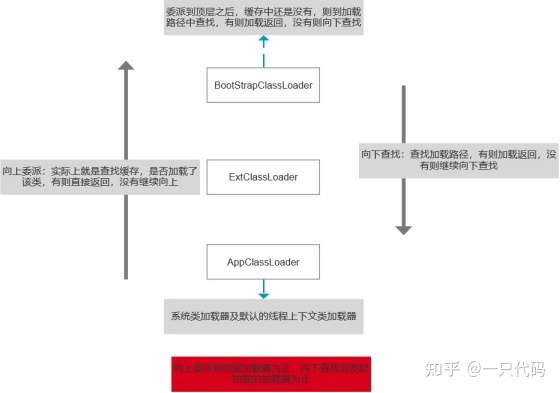
双亲委派模型的好处:
- 主要是为了安全性,避免用户自己编写的类动态替换 Java的一些核心类,比如 String。
- 同时也避免了类的重复加载,因为 JVM中区分不同类,不仅仅是根据类名,相同的 class文件被不同的 ClassLoader加载就是不同的两个类
16、GC如何判断对象可以被回收
- 引用计数法:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计 数为0时可以回收,
- 可达性分析法:从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的,那么虚拟机就判断是可回收对象。
引用计数法,可能会出现A 引用了 B,B 又引用了 A,这时候就算他们都不再使用了,但因为相互引用 计数器=1 永远无法被回收。
GC Roots的对象有:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即一般说的Native方法)引用的对象
可达性算法中的不可达对象并不是立即死亡的,对象拥有一次自我拯救的机会。对象被系统宣告死亡至 少要经历两次标记过程:第一次是经过可达性分析发现没有与GC Roots相连接的引用链,第二次是在由虚拟机自动建立的Finalizer队列中判断是否需要执行finalize()方法。
当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否 则,对象“复活”
每个对象只能触发一次finalize()方法
由于finalize()方法运行代价高昂,不确定性大,无法保证各个对象的调用顺序,不推荐大家使用,建议遗忘它。
17、线程的生命周期?线程有几种状态
\1. 线程通常有五种状态,创建,就绪,运行、阻塞和死亡状态。
\2. 阻塞的情况又分为三种:
(1) 、等待阻塞:运行的线程执行wait方法,该线程会释放占用的所有资源,JVM会把该线程放入“等待池”中。进入这个状态后,是不能自动唤醒的,必须依靠其他线程调用notify或notifyAll方法才能被唤醒,wait是object类的方法
(2) 、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入“锁池”中。
(3) 、其他阻塞:运行的线程执行sleep或join方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状 态。当sleep状态超时、join等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。sleep是Thread类的方法
\1. 新建状态(New):新创建了一个线程对象。
\2. 就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
\3. 运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
\4. 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。
\5. 死亡状态(Dead):线程执行完了或者因异常退出了run方法,该线程结束生命周期。
18、sleep()、wait()、join()、yield()的区别
\1. 锁池
所有需要竞争同步锁的线程都会放在锁池当中,比如当前对象的锁已经被其中一个线程得到,则其他线 程需要在这个锁池进行等待,当前面的线程释放同步锁后锁池中的线程去竞争同步锁,当某个线程得到 后会进入就绪队列进行等待cpu资源分配。
\2. 等待池
当我们调用wait()方法后,线程会放到等待池当中,等待池的线程是不会去竞争同步锁。只有调用了notify()或notifyAll()后等待池的线程才会开始去竞争锁,notify()是随机从等待池选出一个线程放 到锁池,而notifyAll()是将等待池的所有线程放到锁池当中
1、sleep 是 Thread 类的静态本地方法,wait 则是 Object 类的本地方法。
2、sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
sleep就是把cpu的执行资格和执行权释放出去,不再运行此线程,当定时时间结束再取回cpu资源,参与cpu 的调度,获取到cpu资源后就可以继续运行了。而如果sleep时该线程有锁,那么sleep不会释放这个锁,而 是把锁带着进入了冻结状态,也就是说其他需要这个锁的线程根本不可能获取到这个锁。也就是说无法执行程 序。如果在睡眠期间其他线程调用了这个线程的interrupt方法,那么这个线程也会抛出interruptexception异常返回,这点和wait是一样的。
3、sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字。
4、sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
5、sleep 一般用于当前线程休眠,或者轮循暂停操作,wait 则多用于多线程之间的通信。
6、sleep 会让出 CPU 执行时间且强制上下文切换,而 wait 则不一定,wait 后可能还是有机会重新竞争到锁继续执行的。
yield()执行后线程直接进入就绪状态,马上释放了cpu的执行权,但是依然保留了cpu的执行资格, 所以有可能cpu下次进行线程调度还会让这个线程获取到执行权继续执行
join()执行后线程进入阻塞状态,例如在线程B中调用线程A的join(),那线程B会进入到阻塞队列,直到线程A结束或中断线程
public static void main(String[] args) throws InterruptedException { Thread t1 = new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("22222222"); } }); t1.start(); t1.join(); // 这行代码必须要等t1全部执行完毕,才会执行 System.out.println("1111"); } 22222222 1111
19、对线程安全的理解
不是线程安全、应该是内存安全,堆是共享内存,可以被所有线程访问
当多个线程访问一个对象时,如果不用进行额外的同步控制或其他的协调操作,调用这个对象的行为都可以获 得正确的结果,我们就说这个对象是线程安全的
堆是进程和线程共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分 配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是用完了 要还给操作系统,要不然就是内存泄漏。
在Java中,堆是Java虚拟机所管理的内存中最大的一块,是所有线程共享的一块内存区域,在虚 拟机启动时创建。堆所存在的内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及 数组都在这里分配内存。
栈是每个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈 互相独立,因此,栈是线程安全的。操作系统在切换线程的时候会自动切换栈。栈空间不需要在高级语 言里面显式的分配和释放。
目前主流操作系统都是多任务的,即多个进程同时运行。为了保证安全,每个进程只能访问分配给自己 的内存空间,而不能访问别的进程的,这是由操作系统保障的。
在每个进程的内存空间中都会有一块特殊的公共区域,通常称为堆(内存)。进程内的所有线程都可以 访问到该区域,这就是造成问题的潜在原因。
20、Thread、Runable的区别
Thread和Runnable的实质是继承关系,没有可比性。无论使用Runnable还是Thread,都会new
Thread,然后执行run方法。用法上,如果有复杂的线程操作需求,那就选择继承Thread,如果只是简单的执行一个任务,那就实现runnable。
//会卖出多一倍的票public class Test { public static void main(String[] args) { // TODO Auto-generated method stub new MyThread().start(); new MyThread().start(); } static class MyThread extends Thread{ private int ticket = 5; public void run(){ while(true){ System.out.println("Thread ticket = " + ticket--); if(ticket < 0){ break; } } } } } //正常卖出 public class Test2 { public static void main(String[] args) { // TODO Auto-generated method stub MyThread2 mt=new MyThread2(); new Thread(mt).start(); new Thread(mt).start(); } static class MyThread2 implements Runnable{ private int ticket = 5; public void run(){ while(true){ System.out.println("Runnable ticket = " + ticket--); if(ticket < 0){ break; } } } } }
原因是:MyThread创建了两个实例,自然会卖出两倍,属于用法错误
21、对守护线程的理解
守护线程:为所有非守护线程提供服务的线程;任何一个守护线程都是整个JVM中所有非守护线程的保姆;
守护线程类似于整个进程的一个默默无闻的小喽喽;它的生死无关重要,它却依赖整个进程而运行;哪 天其他线程结束了,没有要执行的了,程序就结束了,理都没理守护线程,就把它中断了;
注意: 由于守护线程的终止是自身无法控制的,因此千万不要把IO、File等重要操作逻辑分配给它;因为它不靠谱;
守护线程的作用是什么?
举例, GC垃圾回收线程:就是一个经典的守护线程,当我们的程序中不再有任何运行的Thread,程序就不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线 程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。
应用场景:(1)来为其它线程提供服务支持的情况;(2) 或者在任何情况下,程序结束时,这个线程必须正常且立刻关闭,就可以作为守护线程来使用;反之,如果一个正在执行某个操作的线程必须要 正确地关闭掉否则就会出现不好的后果的话,那么这个线程就不能是守护线程,而是用户线程。通常都 是些关键的事务,比方说,数据库录入或者更新,这些操作都是不能中断的。
thread.setDaemon(true)必须在thread.start()之前设置,否则会跑出一个IllegalThreadStateException异常。你不能把正在运行的常规线程设置为守护线程。
在Daemon线程中产生的新线程也是Daemon的。
守护线程不能用于去访问固有资源,比如读写操作或者计算逻辑。因为它会在任何时候甚至在一个操作 的中间发生中断。
Java自带的多线程框架,比如ExecutorService,会将守护线程转换为用户线程,所以如果要使用后台线 程就不能用Java的线程池。
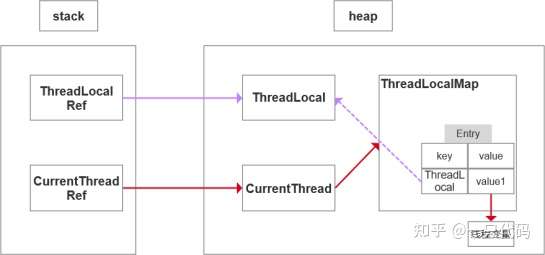
22、ThreadLocal的原理和使用场景
每一个Thread 对象均含有一个ThreadLocalMap 类型的成员变量threadLocals ,它存储本线程中所有ThreadLocal对象及其对应的值
ThreadLocalMap 由一个个Entry 对象构成
Entry 继承自WeakReference<ThreadLocal<?>> ,一个Entry 由ThreadLocal 对象和Object 构成。由此可见, Entry 的key是ThreadLocal对象,并且是一个弱引用。当没指向key的强引用后,该key就会被垃圾收集器回收
当执行set方法时,ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap对象。再以当前ThreadLocal对象为key,将值存储进ThreadLocalMap对象中。
get方法执行过程类似。ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap
对象。再以当前ThreadLocal对象为key,获取对应的value。
由于每一条线程均含有各自私有的ThreadLocalMap容器,这些容器相互独立互不影响,因此不会存在 线程安全性问题,从而也无需使用同步机制来保证多条线程访问容器的互斥性。
使用场景:
1、在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。
2、线程间数据隔离
3、进行事务操作,用于存储线程事务信息。4、数据库连接,Session会话管理。
Spring框架在事务开始时会给当前线程绑定一个Jdbc Connection,在整个事务过程都是使用该线程绑定的connection来执行数据库操作,实现了事务的隔离性。Spring框架里面就是用的ThreadLocal来实现这种隔离
23、ThreadLocal内存泄露原因,如何避免
内存泄露为程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露 堆积后果很严重,无论多少内存,迟早会被占光,不再会被使用的对象或者变量占用的内存不能被回收,就是内存泄露。
强引用:使用最普遍的引用(new),一个对象具有强引用,不会被垃圾回收器回收。当内存空间不足,
Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不回收这种对象
如果想取消强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样可以使JVM在合适的时间就会回收该对象。
弱引用:JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用
java.lang.ref.WeakReference类来表示。可以在缓存中使用弱引用。
ThreadLocal的实现原理,每一个Thread维护一个ThreadLocalMap,key为使用弱引用的ThreadLocal实例,value为线程变量的副本
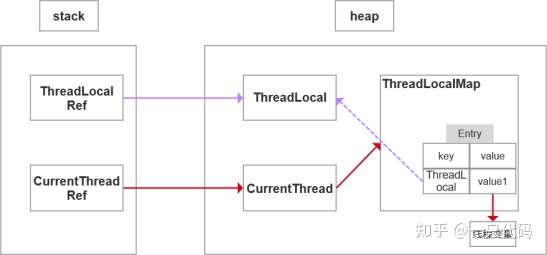
hreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal不存在外部强引用时, Key(ThreadLocal)势必会被GC回收,这样就会导致ThreadLocalMap中key为null, 而value还存在着强引用,只有thead线程退出以后,value的强引用链条才会断掉,但如果当前线程再迟迟不结束的话,这 些key为null的Entry的value就会一直存在一条强引用链(红色链条)
key 使用强引用
当hreadLocalMap的key为强引用回收ThreadLocal时,因为ThreadLocalMap还持有ThreadLocal的强 引用,如果没有手动删除,ThreadLocal不会被回收,导致Entry内存泄漏。
key 使用弱引用
当ThreadLocalMap的key为弱引用回收ThreadLocal时,由于ThreadLocalMap持有ThreadLocal的弱 引用,即使没有手动删除,ThreadLocal也会被回收。当key为null,在下一次ThreadLocalMap调用set(),get(),remove()方法的时候会被清除value值。
因此,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread一样长,如果没有手动删除对应key就会导致内存泄漏,而不是因为弱引用。
ThreadLocal正确的使用方法
每次使用完ThreadLocal都调用它的remove()方法清除数据
将ThreadLocal变量定义成private static,这样就一直存在ThreadLocal的强引用,也就能保证任何时候都能通过ThreadLocal的弱引用访问到Entry的value值,进而清除掉 。
24、并发、并行、串行的区别
串行在时间上不可能发生重叠,前一个任务没搞定,下一个任务就只能等着并行在时间上是重叠的,两个任务在同一时刻互不干扰的同时执行。
并发允许两个任务彼此干扰。统一时间点、只有一个任务运行,交替执行
25、为什么用线程池?解释下线程池参数?
1、降低资源消耗;提高线程利用率,降低创建和销毁线程的消耗。
2、提高响应速度;任务来了,直接有线程可用可执行,而不是先创建线程,再执行。
3、提高线程的可管理性;线程是稀缺资源,使用线程池可以统一分配调优监控。
- corePoolSize代表核心线程数,也就是正常情况下创建工作的线程数,这些线程创建后并不会 消除,而是一种常驻线程
- maxinumPoolSize代表的是最大线程数,它与核心线程数相对应,表示最大允许被创建的线程数,比如当前任务较多,将核心线程数都用完了,还无法满足需求时,此时就会创建新的线程,但 是线程池内线程总数不会超过最大线程数
- keepAliveTime 、 unit 表示超出核心线程数之外的线程的空闲存活时间,也就是核心线程不会消除,但是超出核心线程数的部分线程如果空闲一定的时间则会被消除,我们可以通过setKeepAliveTime来设置空闲时间
- workQueue用来存放待执行的任务,假设我们现在核心线程都已被使用,还有任务进来则全部放 入队列,直到整个队列被放满但任务还再持续进入则会开始创建新的线程
- ThreadFactory实际上是一个线程工厂,用来生产线程执行任务。我们可以选择使用默认的创建工厂,产生的线程都在同一个组内,拥有相同的优先级,且都不是守护线程。当然我们也可以选择 自定义线程工厂,一般我们会根据业务来制定不同的线程工厂
- Handler任务拒绝策略,有两种情况,第一种是当我们调用shutdown 等方法关闭线程池后,这时候即使线程池内部还有没执行完的任务正在执行,但是由于线程池已经关闭,我们再继续想线程 池提交任务就会遭到拒绝。另一种情况就是当达到最大线程数,线程池已经没有能力继续处理新提 交的任务时,这是也就拒绝
26、简述线程池处理流程
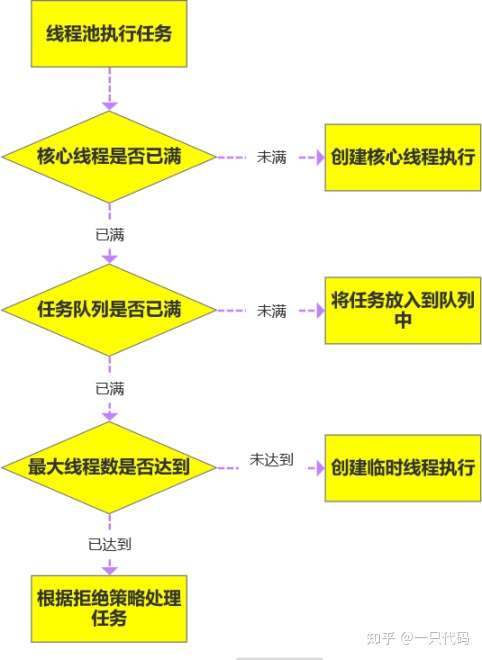
27、线程池中阻塞队列的作用?为什么是先添加列队而不是先创建最大线程?
1、一般的队列只能保证作为一个有限长度的缓冲区,如果超出了缓冲长度,就无法保留当前的任务 了,阻塞队列通过阻塞可以保留住当前想要继续入队的任务。
阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使得线程进入wait状态,释放cpu资源。
阻塞队列自带阻塞和唤醒的功能,不需要额外处理,无任务执行时,线程池利用阻塞队列的take方法挂起,从而维持核心线程的存活、不至于一直占用cpu资源
2、在创建新线程的时候,是要获取全局锁的,这个时候其它的就得阻塞,影响了整体效率。
就好比一个企业里面有10个(core)正式工的名额,最多招10个正式工,要是任务超过正式工人数
(task > core)的情况下,工厂领导(线程池)不是首先扩招工人,还是这10人,但是任务可以稍微积压一下,即先放到队列去(代价低)。10个正式工慢慢干,迟早会干完的,要是任务还在继续增加,超 过正式工的加班忍耐极限了(队列满了),就的招外包帮忙了(注意是临时工)要是正式工加上外包还 是不能完成任务,那新来的任务就会被领导拒绝了(线程池的拒绝策略)。
28、线程池中线程复用原理
线程池将线程和任务进行解耦,线程是线程,任务是任务,摆脱了之前通过 Thread 创建线程时的一个线程必须对应一个任务的限制。
在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对
Thread 进行了封装,并不是每次执行任务都会调用 Thread.start() 来创建新线程,而是让每个线程去执行一个“循环任务”,在这个“循环任务”中不停检查是否有任务需要被执行,如果有则直接执行,也就是调用任务中的 run 方法,将 run 方法当成一个普通的方法执行,通过这种方式只使用固定的线程就将所有任务的 run 方法串联起来。
29、如何实现一个IOC容器
1、配置文件配置包扫描路径
2、递归包扫描获取.class文件
3、反射、确定需要交给IOC管理的类
4、对需要注入的类进行依赖注入
- 配置文件中指定需要扫描的包路径
- 定义一些注解,分别表示访问控制层、业务服务层、数据持久层、依赖注入注解、获取配置文件注 解
- 从配置文件中获取需要扫描的包路径,获取到当前路径下的文件信息及文件夹信息,我们将当前路 径下所有以.class结尾的文件添加到一个Set集合中进行存储
- 遍历这个set集合,获取在类上有指定注解的类,并将其交给IOC容器,定义一个安全的Map用来存储这些对象
- 遍历这个IOC容器,获取到每一个类的实例,判断里面是有有依赖其他的类的实例,然后进行递归注入
30、spring是什么?
轻量级的开源的J2EE框架。它是一个容器框架,用来装javabean(java对象),中间层框架(万能胶) 可以起一个连接作用,比如说把Struts和hibernate粘合在一起运用,可以让我们的企业开发更快、更简洁
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架
--从大小与开销两方面而言Spring都是轻量级的。
--通过控制反转(IoC)的技术达到松耦合的目的
--提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务进行内聚性的开发
--包含并管理应用对象(Bean)的配置和生命周期,这个意义上是一个容器。
--将简单的组件配置、组合成为复杂的应用,这个意义上是一个框架。
31、谈谈你对AOP的理解
系统是由许多不同的组件所组成的,每一个组件各负责一块特定功能。除了实现自身核心功能之外,这 些组件还经常承担着额外的职责。例如日志、事务管理和安全这样的核心服务经常融入到自身具有核心 业务逻辑的组件中去。这些系统服务经常被称为横切关注点,因为它们会跨越系统的多个组件。
当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。
日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。 在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
AOP:将程序中的交叉业务逻辑(比如安全,日志,事务等),封装成一个切面,然后注入到目标对象(具体业务逻辑)中去。AOP可以对某个对象或某些对象的功能进行增强,比如对象中的方法进行增强,可以在执行某个方法之前额外的做一些事情,在某个方法执行之后额外的做一些事情
32、谈谈你对IOC的理解
容器概念、控制反转、依赖注入
ioc容器:实际上就是个map(key,value),里面存的是各种对象(在xml里配置的bean节点、@repository、@service、@controller、@component),在项目启动的时候会读取配置文件里面的bean节点,根据全限定类名使用反射创建对象放到map里、扫描到打上上述注解的类还是通过反射创建对象放到map里。
这个时候map里就有各种对象了,接下来我们在代码里需要用到里面的对象时,再通过DI注入
(autowired、resource等注解,xml里bean节点内的ref属性,项目启动的时候会读取xml节点ref属性根据id注入,也会扫描这些注解,根据类型或id注入;id就是对象名)。
控制反转:
没有引入IOC容器之前,对象A依赖于对象B,那么对象A在初始化或者运行到某一点的时候,自己必须主动去创建对象B或者使用已经创建的对象B。无论是创建还是使用对象B,控制权都在自己手上。
引入IOC容器之后,对象A与对象B之间失去了直接联系,当对象A运行到需要对象B的时候,IOC容器会主动创建一个对象B注入到对象A需要的地方。
通过前后的对比,不难看出来:对象A获得依赖对象B的过程,由主动行为变为了被动行为,控制权颠倒过来了,这就是“控制反转”这个名称的由来。
全部对象的控制权全部上缴给“第三方”IOC容器,所以,IOC容器成了整个系统的关键核心,它起到了一种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个“粘合剂”,对象与对 象之间会彼此失去联系,这就是有人把IOC容器比喻成“粘合剂”的由来。
依赖注入:
“获得依赖对象的过程被反转了”。控制被反转之后,获得依赖对象的过程由自身管理变为了由IOC容器主动注入。依赖注入是实现IOC的方法,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中。
33、BeanFactory和ApplicationContext有什么区别?
ApplicationContext是BeanFactory的子接口
ApplicationContext提供了更完整的功能:
①继承MessageSource,因此支持国际化。
②统一的资源文件访问方式。
③提供在监听器中注册bean的事件。
④同时加载多个配置文件。
⑤载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。
- BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问 题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
- ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我 们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
- 相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
- BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
- BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的 使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
34、描述一下Spring Bean的生命周期?
1、解析类得到BeanDefinition
2、如果有多个构造方法,则要推断构造方法
3、确定好构造方法后,进行实例化得到一个对象
4、对对象中的加了@Autowired注解的属性进行属性填充
5、回调Aware方法,比如BeanNameAware,BeanFactoryAware 6、调用BeanPostProcessor的初始化前的方法
7、调用初始化方法
8、调用BeanPostProcessor的初始化后的方法,在这里会进行AOP 9、如果当前创建的bean是单例的则会把bean放入单例池
10、使用bean
11、Spring容器关闭时调用DisposableBean中destory()方法
35、Spring Boot、Spring MVC 和 Spring 有什么区别
spring是一个IOC容器,用来管理Bean,使用依赖注入实现控制反转,可以很方便的整合各种框架,提供AOP机制弥补OOP的代码重复问题、更方便将不同类不同方法中的共同处理抽取成切面、自动注入给方法执行,比如日志、异常等
springmvc是spring对web框架的一个解决方案,提供了一个总的前端控制器Servlet,用来接收请求, 然后定义了一套路由策略(url到handle的映射)及适配执行handle,将handle结果使用视图解析技术 生成视图展现给前端
springboot是spring提供的一个快速开发工具包,让程序员能更方便、更快速的开发spring+springmvc
应用,简化了配置(约定了默认配置),整合了一系列的解决方案(starter机制)、redis、mongodb、es,可以开箱即用
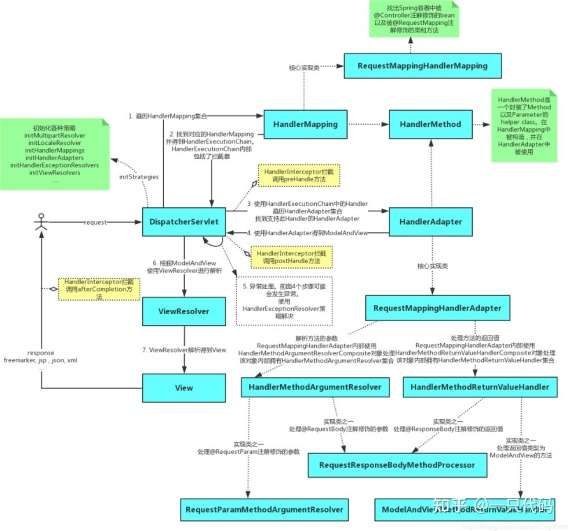
36、SpringMVC 工作流程
1) 用户发送请求至前端控制器 DispatcherServlet。
2) DispatcherServlet 收到请求调用 HandlerMapping 处理器映射器。
3) 处理器映射器找到具体的处理器(可以根据 xml 配置、注解进行查找),生成处理器及处理器拦截器
(如果有则生成)一并返回给 DispatcherServlet。
4) DispatcherServlet 调用 HandlerAdapter 处理器适配器。
5) HandlerAdapter 经过适配调用具体的处理器(Controller,也叫后端控制器) 6)Controller 执行完成返回 ModelAndView。
7)HandlerAdapter 将 controller 执行结果 ModelAndView 返回给 DispatcherServlet。8) DispatcherServlet 将 ModelAndView 传给 ViewReslover 视图解析器。
9) ViewReslover 解析后返回具体 View。
10) DispatcherServlet 根据 View 进行渲染视图(即将模型数据填充至视图中)。
11) DispatcherServlet 响应用户。
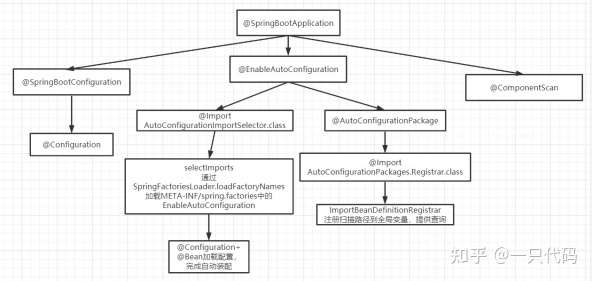
37、Spring Boot 自动配置原理?
@Import + @Configuration + Spring spi
自动配置类由各个starter提供,使用@Configuration + @Bean定义配置类,放到META-
INF/spring.factories下
使用Spring spi扫描META-INF/spring.factories下的配置类使用@Import导入自动配置类
38、如何理解 Spring Boot 中的 Starter
使用spring + springmvc使用,如果需要引入mybatis等框架,需要到xml中定义mybatis需要的bean
starter就是定义一个starter的jar包,写一个@Configuration配置类、将这些bean定义在里面,然后在starter包的META-INF/spring.factories中写入该配置类,springboot会按照约定来加载该配置类
开发人员只需要将相应的starter包依赖进应用,进行相应的属性配置(使用默认配置时,不需要配置),就可以直接进行代码开发,使用对应的功能了,比如mybatis-spring-boot--starter,spring- boot-starter-redis
39、什么是嵌入式服务器?为什么要使用嵌入式服务器?
节省了下载安装tomcat,应用也不需要再打war包,然后放到webapp目录下再运行 只需要一个安装了 Java 的虚拟机,就可以直接在上面部署应用程序了springboot已经内置了tomcat.jar,运行main方法时会去启动tomcat,并利用tomcat的spi机制加载springmvc
40、mybatis的优缺点
优点:
1、基于 SQL 语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL 写在XML 里,解除 sql 与程序代码的耦合,便于统一管理;提供 XML 标签, 支持编写动态 SQL 语句, 并可重用。
2、与 JDBC 相比,减少了 50%以上的代码量,消除了 JDBC 大量冗余的代码,不需要手动开关连接;
3、很好的与各种数据库兼容( 因为 MyBatis 使用 JDBC 来连接数据库,所以只要JDBC 支持的数据库
MyBatis 都支持)。
4、能够与 Spring 很好的集成;
5、提供映射标签, 支持对象与数据库的 ORM 字段关系映射; 提供对象关系映射标签, 支持对象关系组件维护。
缺点:
1、SQL 语句的编写工作量较大, 尤其当字段多、关联表多时, 对开发人员编写SQL 语句的功底有一定要求。
2、SQL 语句依赖于数据库, 导致数据库移植性差, 不能随意更换数据库。
41、#{}和${}的区别是什么?
#{}是预编译处理、是占位符, ${}是字符串替换、是拼接符。
Mybatis 在处理#{}时,会将 sql 中的#{}替换为?号,调用 PreparedStatement 来赋值;
Mybatis 在处理${}时, 就是把${}替换成变量的值,调用 Statement 来赋值;
#{} 的变量替换是在DBMS 中、变量替换后,#{} 对应的变量自动加上单引号
${} 的变量替换是在 DBMS 外、变量替换后,${} 对应的变量不会加上单引号使用#{}可以有效的防止 SQL 注入, 提高系统安全性。
42、索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。 索引的原理:就是把无序的数据变成有序的查询
\1. 把创建了索引的列的内容进行排序
\2. 对排序结果生成倒排表
\3. 在倒排表内容上拼上数据地址链
\4. 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
43、索引设计的原则?
查询更快、占用空间更小
\1. 适合索引的列是出现在where子句中的列,或者连接子句中指定的列
\2. 基数较小的表,索引效果较差,没有必要在此列建立索引
\3. 使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间, 如果搜索词超过索引前缀长度,则使用索引排除不匹配的行,然后检查其余行是否可能匹配。
\4. 不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进 行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
\5. 定义有外键的数据列一定要建立索引。
\6. 更新频繁字段不适合创建索引
\7. 若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
\8. 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
\9. 对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
\10. 对于定义为text、image和bit的数据类型的列不要建立索引。
44、如何实现接口的幂等性
- 唯一id。每次操作,都根据操作和内容生成唯一的id,在执行之前先判断id是否存在,如果不存在则执行后续操作,并且保存到数据库或者redis等。
- 服务端提供发送token的接口,业务调用接口前先获取token,然后调用业务接口请求时,把token 携带过去,务器判断token是否存在redis中,存在表示第一次请求,可以继续执行业务,执行业务完成后,最后需要把redis中的token删除
- 建去重表。将业务中有唯一标识的字段保存到去重表,如果表中存在,则表示已经处理过了
- 版本控制。增加版本号,当版本号符合时,才能更新数据
- 状态控制。例如订单有状态已支付 未支付 支付中 支付失败,当处于未支付的时候才允许修改为支付中等
45、Spring Cloud和Dubbo的区别
底层协议:springcloud基于http协议,dubbo基于Tcp协议,决定了dubbo的性能相对会比较好 注册中心:Spring Cloud 使用的 eureka ,dubbo推荐使用zookeeper
模型定义:dubbo 将一个接口定义为一个服务,SpringCloud 则是将一个应用定义为一个服务
SpringCloud是一个生态,而Dubbo是SpringCloud生态中关于服务调用一种解决方案(服务治理)
46、Kafka的性能好在什么地方
kafka不基于内存,而是硬盘存储,因此消息堆积能力更强
顺序写:利用磁盘的顺序访问速度可以接近内存,kafka的消息都是append操作,partition是有序的, 节省了磁盘的寻道时间,同时通过批量操作、节省写入次数,partition物理上分为多个segment存储, 方便删除
传统:
- 读取磁盘文件数据到内核缓冲区
- 将内核缓冲区的数据copy到用户缓冲区
- 将用户缓冲区的数据copy到socket的发送缓冲区
- 将socket发送缓冲区中的数据发送到网卡、进行传输
零拷贝:
- 直接将内核缓冲区的数据发送到网卡传输
- 使用的是操作系统的指令支持
kafka不太依赖jvm,主要理由操作系统的pageCache,如果生产消费速率相当,则直接用pageCache
交换数据,不需要经过磁盘IO


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~