
mysql优化整理(索引)
什么是索引?
索引是表记录的单个或多个字段重新组织的一种方法,其目的是提高数据库的查询速度,本质上就是一种数据结构。
索引的类型:primary(主键)、secondary(其他)
索引的数据结构
-
Innodb primary key
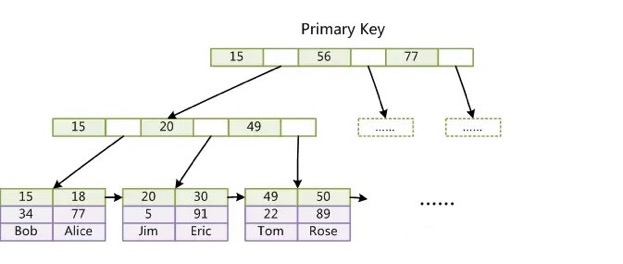
物理文件:

-
Innodb secondary key
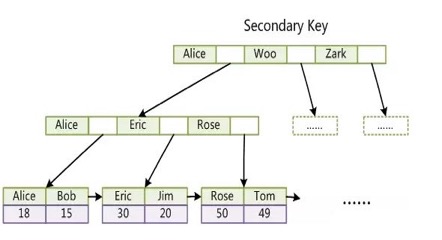
索引的优缺点
- 优点
在大数据前提下,多数情况都会加快查询的速度 - 缺点
每次的数据的更新、删除以及插入操作都需要对索引进行额外的维护,所以需要谨慎的创建索引,创建索引不是万能的,后面会介绍一些简单的技巧
小技巧
- 索引列都有default值
这个的主要问题是,数据库存储的数值存在数据类型转换的问题,如果有默认值,就可以达到快速区别的作用。 - 控制好索引长度
一般情况下,索引的字段只会存储255个字符长度,如果超出这部分之外的,其实作用不是很大,所以创建索引的字段长度最好是255以内的长度。 - 索引列的分组排序
对于创建索引的字段进行分组处理,使用union进行合并 - like语句的优化。
使用like的语句首先可以创建索引,其次尽量避免使用双百分号(%),尽量使用一个%完成,这样可以提升速度。 - 不在索引列上进行运算
不要对字段进行计算后查询(避免将计算写在等号左边,可以换一种写法放在等号右边)。 - 不使用NOT IN和!=操作
对于使用not in或者!=的查询语句,尽量使用in写法。 - 注意隐式转换的问题
和第一条差不多,我们存储的字段类型最好和我们查询语句的字段类型保持一致,这样可以提升访问速度。 - 创建组合索引可以将常用字段放在最左,这样单个查询条件也可以使用索引
再度整理
- 创建合理的索引或者组合索引
- 改写语句,对于没有创建索引的语句,可以使用其他形式转换成具有索引的查询语句
- 链表查询时,最好使用inner形式或者是union合并;另外最好把条件限制到最低,这样符合要求的语句就会更少,查询速度会更快。
- 减少并发量
有时候发现单个执行很快,多个并发执行会有这个问题。 - 缩小查询范围
比如使用in的时候,in里面字段最多不超过20个,limit也需要减少个数。 - 使用主、从库,进行读写分离
- 其他的可能需要检查机器本身的问题了:内存、磁盘等等。
其他
查看是否使用索引方式:可以使用 explain + sql语句,查看所查询的语句是否使用了创建的索引,进而优化自己的索引创建。
- 未创建索引的查询
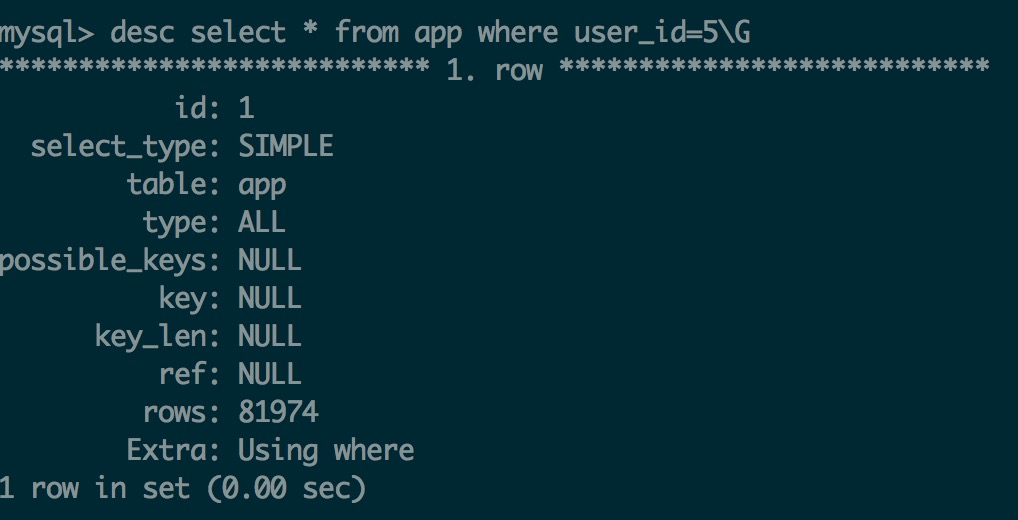
主要字段说明:select_type(简单查询)、table(表名)、type(索引类型)、prosible_key(可能的索引字段)、key(使用到的索引字段)、key_len(索引字段长度)、rows(查询行数)、Extra(额外信息)
- 创建索引的查询
我这里创建了idx_appid_userid的组合索引,进行查询之后:
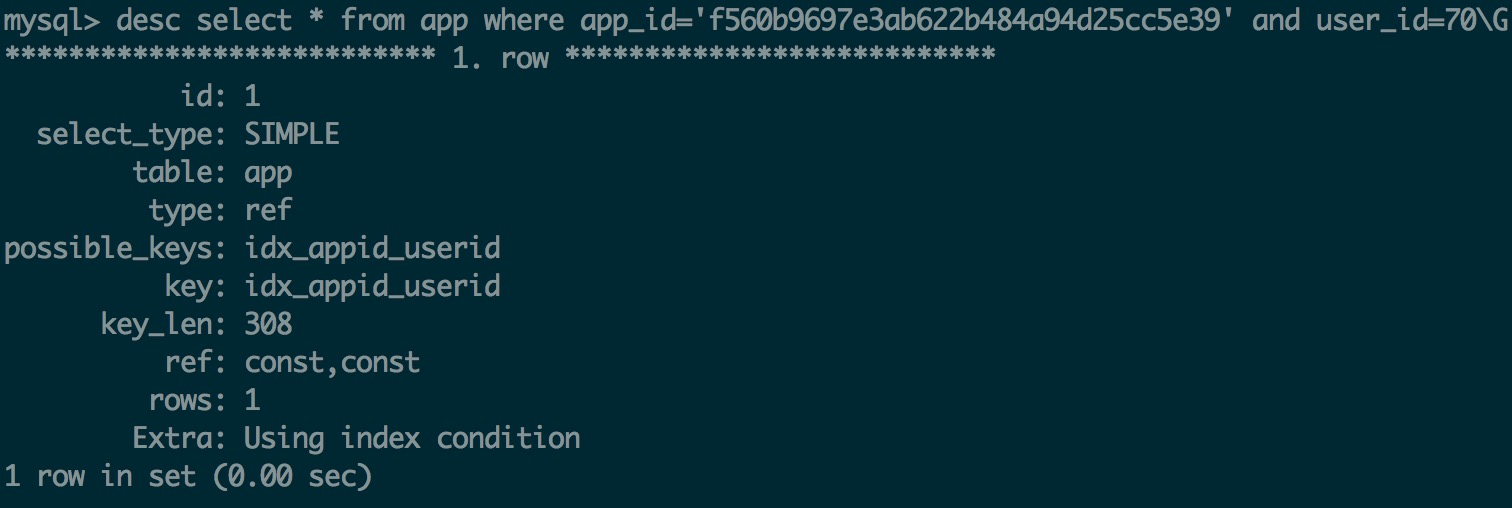
我们可以发现之前的字段值发生了变化,可以看出来使用了我们创建的索引,额外信息中也提到使用到了索引条件。
使用上述方式进行优化后,之前整理过的记一次pending请求问题查找过程,有很大的改善,不过这个优化需要一直跟进。
小结
总体的原则就是:尽最大的努力,结合业务情况,减少数据库服务器的I/O,即可大幅度提升服务器的速度。
本文主要参考#高级DBA李丹的分享,再加上一些实战整理而成,由于是初步接触数据库相关的东西,有描述不准确的欢迎指正。另外,如果有其他好的方案也可以推荐给我,不胜感激~

