DQL语句排序与分组
DQL语句排序与分组
一、DQL-排序
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。分内部排序和外部排序,若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。反之,若参加排序的记录数量很大,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。内部排序的过程是一个逐步扩大记录的有序序列长度的过程。
1.1、排序概述
将数据库表中杂乱无章的数据记录,通过字段的升序或降序的顺序排列的过程叫做排序。
1.2、排序语法
通过order by子句
格式:
select */字段列表 from 数据库表名 [where 条件表达式] [order by 字段名 [asc/desc]];
说明:
asc:升序,默认值
desc:降序
1.3、单列排序
按照一个字段进行排序
案例:
查看学生信息表中按照英语成绩升序排列,去掉成绩为null的学生。
mysql> select * from students where english is not null order by english;
+------+--------+------+------+---------+------+------------+-----------------+
| sid | sname | sex | age | english | math | entertime | remark |
+------+--------+------+------+---------+------+------------+-----------------+
| 6 | 王六 | 女 | 20 | 50.0 | 70.0 | 2017-09-01 | 他来自湖南 |
| 5 | 李三 | 男 | 19 | 60.0 | 88.0 | 2017-09-01 | 他来自湖北 |
| 2 | 李四 | 男 | 20 | 80.0 | 88.0 | 2017-09-01 | 他来自重庆 |
| 4 | 张八 | 男 | 18 | 80.0 | 85.0 | 2017-09-01 | 他来自天津 |
| 3 | 张红 | 女 | 19 | 86.0 | 80.0 | 2017-09-01 | 他来自北京 |
| 7 | 刘红 | 女 | 18 | 90.0 | 98.0 | 2017-09-01 | 他来自甘肃 |
| 1 | 张三 | 男 | 19 | 98.5 | 88.0 | 2017-09-01 | 他来自四川 |
+------+--------+------+------+---------+------+------------+-----------------+
7 行于数据集 (0.01 秒)
1.4、组合排序
按照多个字段进行排序,先按1字段排序,在按2字段排序,在按n字段排序
格式:
select */字段列表 from 数据库表名 [where 条件表达式] [order by 字段名1 [asc/desc],字段名2 [asc/desc],...,字段名n [asc/desc]];
案例:
查看学生信息表中先按照数学成绩升序排列,在按照英语成绩降序排列,最后去掉成绩为null的学生。
mysql> select * from students where english is not null order by math,english desc;
+------+--------+------+------+---------+------+------------+-----------------+
| sid | sname | sex | age | english | math | entertime | remark |
+------+--------+------+------+---------+------+------------+-----------------+
| 6 | 王六 | 女 | 20 | 50.0 | 70.0 | 2017-09-01 | 他来自湖南 |
| 3 | 张红 | 女 | 19 | 86.0 | 80.0 | 2017-09-01 | 他来自北京 |
| 4 | 张八 | 男 | 18 | 80.0 | 85.0 | 2017-09-01 | 他来自天津 |
| 1 | 张三 | 男 | 19 | 98.5 | 88.0 | 2017-09-01 | 他来自四川 |
| 2 | 李四 | 男 | 20 | 80.0 | 88.0 | 2017-09-01 | 他来自重庆 |
| 5 | 李三 | 男 | 19 | 60.0 | 88.0 | 2017-09-01 | 他来自湖北 |
| 7 | 刘红 | 女 | 18 | 90.0 | 98.0 | 2017-09-01 | 他来自甘肃 |
+------+--------+------+------+---------+------+------------+-----------------+
7 行于数据集 (0.02 秒)
二、DQL 分组
数据分组是根据统计研究的需要,将原始数据按照某种标准划分成不同的组别,分组后的的数据称为分组数据。
数据分组应遵循两个基本原则:
穷尽性原则
这一原则就是要求调查的每一单位都能无一例外地划归到某一组去,不会产生“遗漏”现象。
互斥性原则
这一原则就是要求将调查单位分组后,各个组的范围应该互不相容、互为排斥。即每个调查单位在特定的分组标志下只能归属某一组,而不能同时或可能同时归属到几个组。
2.1、分组概述
- 什么是分组
分组就是将一组行记录按列或表达式的值分组成摘要行记录。通过GROUP BY子句返回每个分组的一个行记录。换句话说,它减少了在结果集中的行数。
- 分组语法
– 语法
格式:
select */字段列表 from 数据库表名 [group by 分组字段名 [having 条件表达式]];– 分组方式
将学生信息表中男、女同学进行分组

原始数据
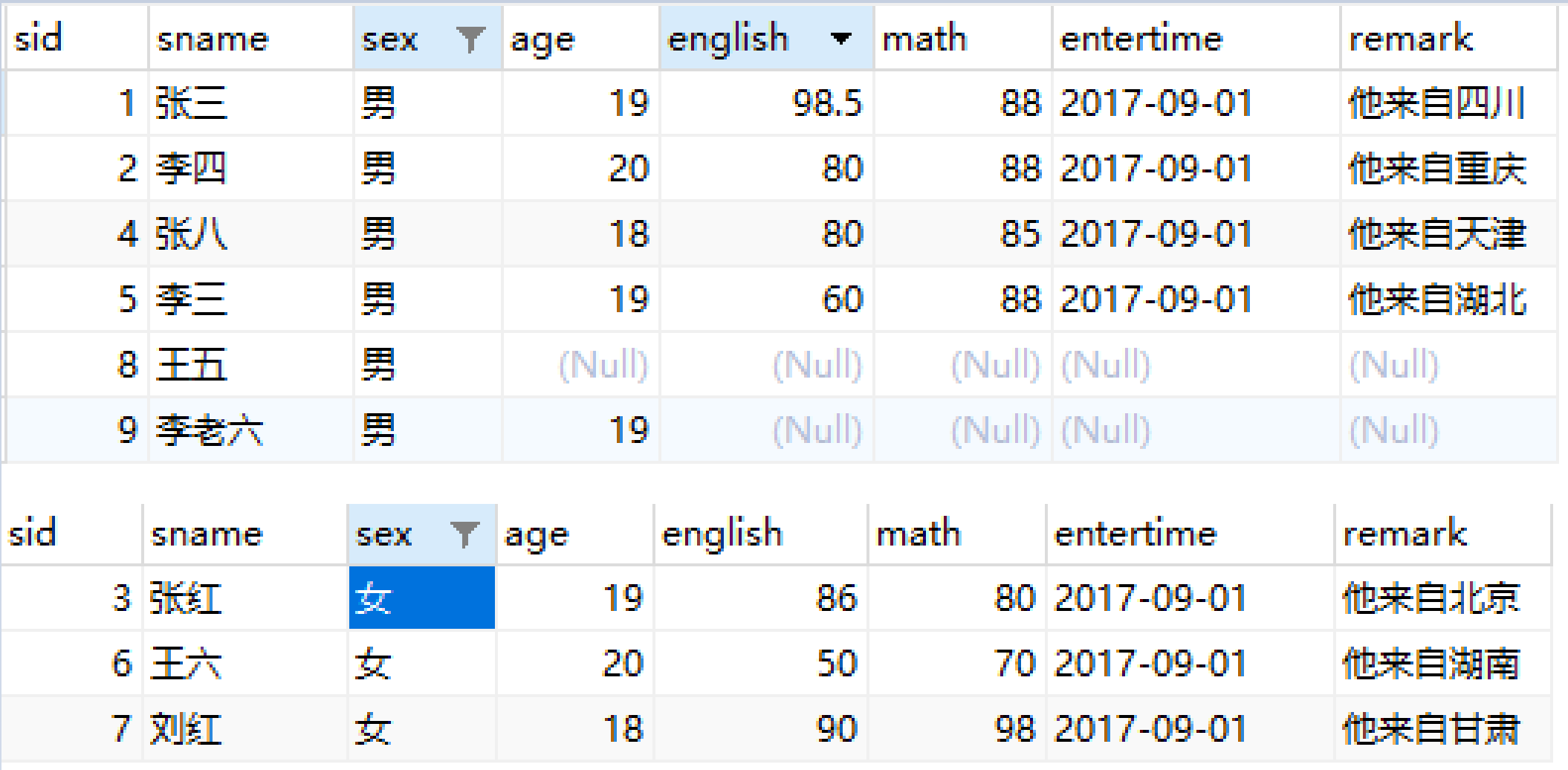
分组为:男一组,女一组
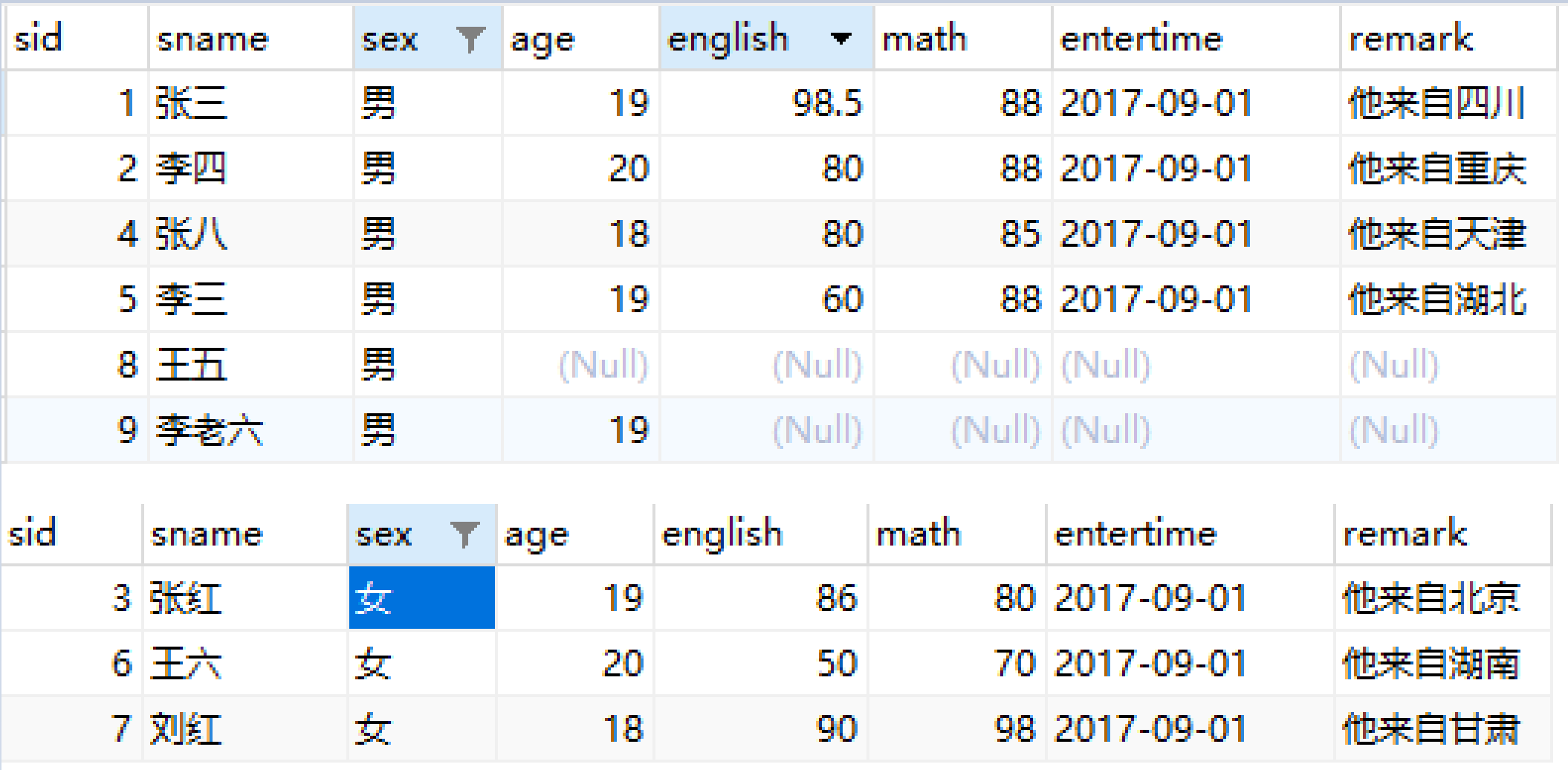
返回每组第一条数据

2.2、分组应用
- 实际分组方式
mysql> select sex from students group by sex;
+------+
| sex |
+------+
| 男 |
| 女 |
+------+
2 行于数据集 (0.01 秒)注意:
当我们使用某个字段分组,在查询的时候也需要将这个字段查询出来,否则看不到数据属于哪组的。
单独分组没什么用处,分组的目的就是为了统计,一般分组会跟聚合函数一起使用。
案例:
查询学生信息表中男、女同学的人数
mysql> select sex,count(*) from students group by sex;
+------+----------+
| sex | count(*) |
+------+----------+
| 男 | 6 |
| 女 | 3 |
+------+----------+
2 行于数据集 (0.01 秒)- where与having
– where**
查询学生信息表中数学成绩在80分以上的,男、女同学的人数
#where后面不能用聚合函数
mysql> select sex,count(*) from students where math>80 group by sex;
+------+----------+
| sex | count(*) |
+------+----------+
| 男 | 4 |
| 女 | 1 |
+------+----------+
2 行于数据集 (0.01 秒)注意:
where是将不符合条件的先去掉,在分组。
– having
查询学生信息表中男、女同学的人数,人数超过3人显示
#having n>3 可以写成 having count(*)>3
mysql> select sex,count(*) as n from students group by sex having n>3;
+------+---+
| sex | n |
+------+---+
| 男 | 6 |
+------+---+
1 行于数据集 (0.03 秒)注意:
having是先分组,在将分组后不符合条件的去掉。
– where与having区别
where 子句
在分组之前过滤数据,即先过滤再分组。
where 后面不可以使用聚合函数。
having 子句
在分组之后过滤数据,即先分组再过滤。
having 后面可以使用聚合函数。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!