OpenCV -5 -GoogLeNet模型使用及CNN理论
OpenCV -5 -GoogLeNet模型使用及CNN理论
使用语言:Java 1.8
操作系统:windows x64
OpenCV:4.1.1
PS:玩这个的怎么都是C++啊,用Java玩的真少 ε=(´ο`*)))唉
关于GoogLeNet的介绍
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tD2wkRmI-1573039315640)(https://static.oschina.net/uploads/space/2018/0317/141419_uDBe_876354.png)]
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。VGG继承了LeNet以及AlexNet的一些框架结构。而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。
关于名字:GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,据说是为了向“LeNet”致敬,因此取名为“GoogLeNet”
神经网络,深度学习等等的东西的理论真的是灰常的复杂。看着头皮发麻。w(゚Д゚)w
请自行查看:理论参考资料:
- https://my.oschina.net/u/876354/blog/1637819 【这一篇灰常的好】
- https://dreamocean.github.io/2017/07/01/net-models/
- https://www.jianshu.com/p/cd73bc979ba9 [LeNet神经网络]
- https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ [LeNet神经网络英文原版]
整理的理论小抄
各种理论体系结构
-
**LeNet(1990年代):**最早的卷积神经网络之一,LeNet主要用来进行手写字符的识别与分类,并在美国的银行中投入了使用。LeNet的实现确立了CNN的结构,现在神经网络中的许多内容在LeNet的网络结构中都能看到,例如卷积层,Pooling层,ReLU层。虽然LeNet网络结构比较简单,但是刚好适合神经网络的入门学习。
-
**1990年代至2012年:**在1990年代末至2010年代初,卷积神经网络得到了发展。随着越来越多的数据和计算能力变得可用,卷积神经网络可以解决的任务变得越来越有趣。
-
AlexNet(2012)– 2012年,Alex Krizhevsky(及其他人)发布了AlexNet,它是LeNet的更深,更广泛的版本,并在2012年以较大的优势赢得了艰难的ImageNet大规模视觉识别挑战赛(ILSVRC)。相对于以前的方法和CNN的当前广泛应用而言,这是一项重大突破,可以归功于这项工作。
-
ZF Net(2013)– 2013年 ILSVRC冠军是Matthew Zeiler和Rob Fergus的卷积网络。它后来被称为ZFNet(以下简称蔡勒与宏泰网)。通过调整体系结构超参数,这是对AlexNet的改进。
-
GoogLeNet(2014)– 2014年 ILSVRC获奖者是Szegedy等人的卷积网络。来自Google。它的主要贡献是开发了一个Inception模块,该模块大大减少了网络中的参数数量(4M,而AlexNet为60M)。
-
VGGNet(2014)– ILSVRC 2014 的亚军是被称为VGGNet的网络。它的主要贡献在于表明网络深度(层数)是获得良好性能的关键因素。
-
ResNets(2015)–由Kaiming He(及其他人)开发的残差网络赢得了ILSVRC 2015的冠军。ResNets目前是最先进的卷积神经网络模型,并且是在实践中使用ConvNets的默认选择(截至2016年5月) )。
-
**DenseNet(2016年8月)–**最近由Gao Huang(及其他作者)发表的 Densely Connected卷积网络 使每一层都以前馈方式直接连接到其他每一层。事实证明,DenseNet在五个高度竞争的对象识别基准测试任务上比以前的最新体系结构有了显着改进。在此处检查Torch的实现。
厉害了,原来这种东东90年代就已经有在搞了,还商用了的。
接下来看看LeNet的理论就差不多了,近些年这些高级的,别说算法了,结构可能都看不懂。︿( ̄︶ ̄)︿
LeNet理论
[黑白]图像本身是一个二维数组,然后卷积核为n*n的矩阵,然后两个相乘就是卷积处理了。
在参考的文章里面有一些图片灰常简明的表示了这种算法:
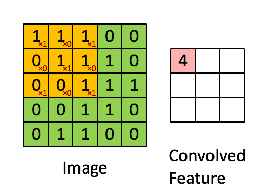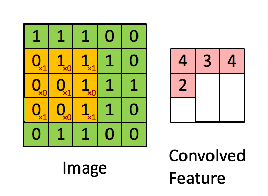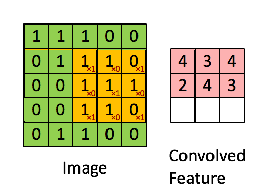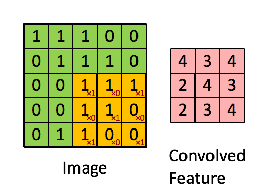

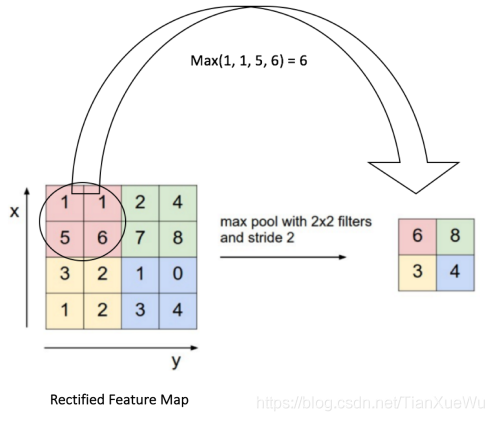
好的,这里4张图【侵删】,表示的分别是:图像本身数据,卷积示意图,同一幅图像用不同卷积核处理的效果,pooling池化运算。
在LeNet网络除去输入输出层总共有六层网络。就是:卷积,池化,卷积,池化,全连接层,全连接层,对应输出层。
大概就是这个样子了,具体的算法我是看不懂的╮(╯_╰)╭:
这里需要一个实例图片:LeNet网络的执行流程图【侵删】

GoogLeNet理论
GoogLeNet用的其实是与LeNet类似的东东,区别在与做了深度,宽度,以及算法的各种加深与优化。
GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
基于Inception构建了GoogLeNet的网络结构如下(共22层):
我是不知道这些层具体是干啥用的 ╮(╯_╰)╭
反正就是很牛逼的感觉:
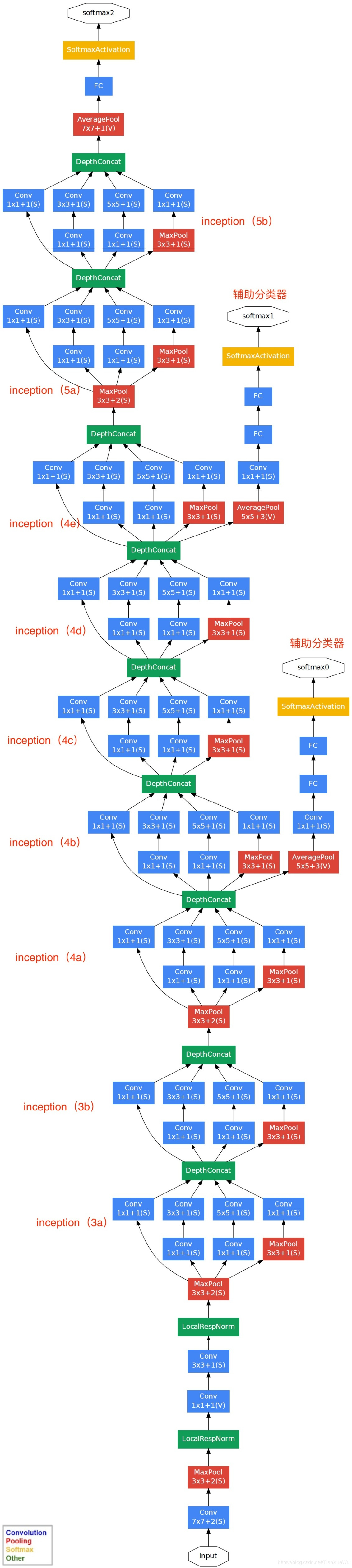
对上图说明如下::
牛逼啊!o( ̄▽ ̄)d,666666,简直神了,wow~ ⊙o⊙
实际使用GoogLeNet
好了,可以忽略那些理论了,实际使用训练好的模型还是灰常的简单的。
直接调用加载模型,然后调用一个方法就可以了。╮(╯_╰)╭
理论的东西,只是为了更好的理解预测方法的结果,只有在自己训练模型的时候会涉及到的,这个在下一篇要试着弄一下的。
直接代码说明吧:
代码中的模型会上传的资源,也可以去参考文章中找到链接地址。
(资源链接地址就不太好意思直接copy过来 )
public class GoogleNetToolsTest {
public static void main(String[] args) {
System.load("D:\\OpenCV\\opencv\\build\\java\\x64\\opencv_java411.dll");
imgTest();
}
private static void imgTest() {
/**
* 加载 GoogleNet模型
*/
String bvlc_googlenet = "D:/OpenCV/opencv/sources/samples/data/dnn/google_net/bvlc_googlenet.caffemodel";
String deploy_prototxt = "D:/OpenCV/opencv/sources/samples/data/dnn/google_net/deploy.prototxt";
String labels_txt_file ="D:/OpenCV/opencv/sources/samples/data/dnn/google_net/synset_words.txt";
Net googleNet = readNetFromCaffe(deploy_prototxt, bvlc_googlenet);
// 测试
Mat testImage = Imgcodecs.imread("D:/ijworkspace/meaen_test/data/test1.png");
//GoogLeNet accepts only 224x224 RGB-images
Mat inputBlob = blobFromImage(testImage, 1, new Size(224, 224), new Scalar(104, 117, 123));
googleNet.setInput(inputBlob,"data");
Mat prob = googleNet.forward("prob");
//维度变成1*1000
Mat probMat = prob.reshape(1, 1);
//最大相似度
Core.MinMaxLocResult MMR = Core.minMaxLoc(probMat);
org.opencv.core.Point matchLoc = MMR.maxLoc;
//最大相似度对应的索引
double Nameindex = matchLoc.x;
System.out.println("匹配标签:"+Nameindex);
//映射训练标签集
String lableName = readGoogleNetLabels(labels_txt_file).get((int)Nameindex);
System.out.println("结果:"+matchLoc+"置信度"+MMR.maxVal*100+"%");
System.out.println("匹配标签:"+lableName);
}
/**
* 加载GoogleNet对应额标签文件 可以识别的1000个标签
* @return
*/
private static List<String> readGoogleNetLabels(String lablesTxt) {
List lables = new ArrayList<String>();
File file = new File(lablesTxt);
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
// 一次读入一行,直到读入null为文件结束
while ((tempString = reader.readLine()) != null) {
// 显示行号
lables.add(tempString.substring(10));
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
return lables;
}
}
结果
使用的方式还是和之前的年龄性别预测一样样的。
这里说明一下,测试了一些图片,对任务识别不了,物体识别中对于主体比较突出的识别率还是很高的。如果识别的物体很小的话,识别率就偏低了。
以下是比较好的测试图片识别结果:
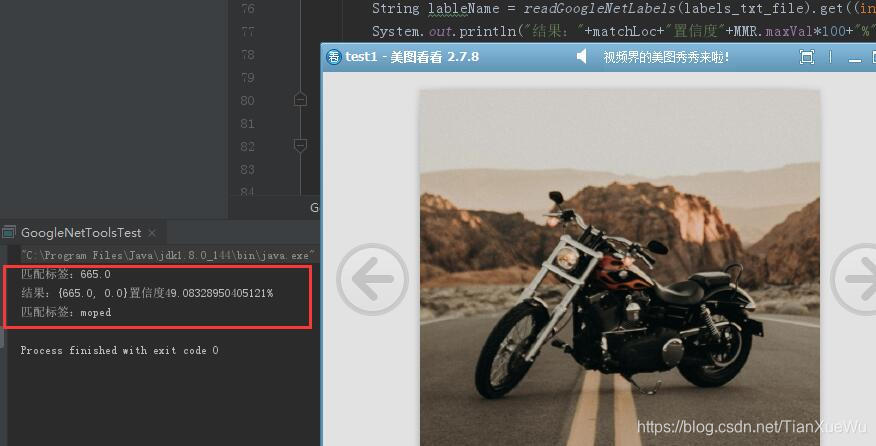
实际使用参考文章:
- https://blog.csdn.net/qq_30815237/article/details/87916157【模型文件在此参考文章给出了】
- https://blog.csdn.net/Daker_Huang/article/details/86736072
小结一下
写到这里使用这个模型,果然还是觉得现在查的资料,用java来玩的真少 ε=(´ο`*)))唉
相对于使用来说,想要理解CNN之类的这种算法,对于我这种普通人来说,头疼。。都看不怎么懂!
计划一下,接下来就是试试自己来训练个模型玩一下了。(想想都晕 (¦3」∠)
2019-11-06 小杭 ୧(๑•̀◡•́๑)૭
本文来自博客园,作者:小-杭,转载请注明原文链接:https://www.cnblogs.com/xiaohangblog/articles/16296471.html
欢迎转载小杭的博客,记得关注点赞收藏哦 (#^.^#)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号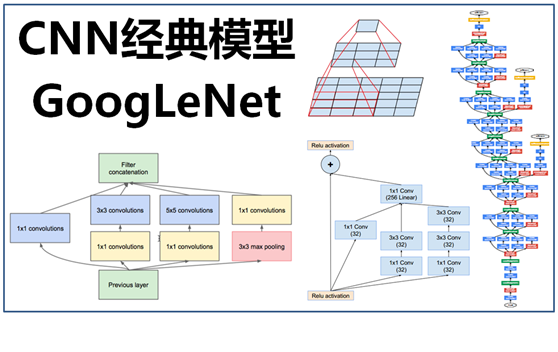{kind=link}