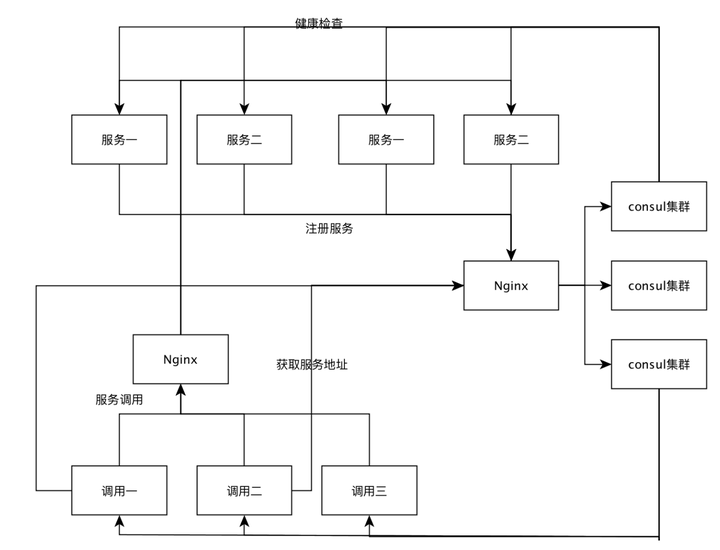
服务发现
转载:https://zhuanlan.zhihu.com/p/32027014
一、什么是服务发现
在传统的系统部署中,服务运行在一个固定的已知的 IP 和端口上,如果一个服务需要调用另外一个服务,可以通过地址直接调用,但是,在虚拟化或容器话的环境中,服务实例的启动和销毁是很频繁的,服务地址在动态的变化,如果需要将请求发送到动态变化的服务实例上,至少需要两个步骤:
服务注册 — 存储服务的主机和端口信息
服务发现 — 允许其他用户发现服务注册阶段存储的信息
服务发现的主要优点是可以无需了解架构的部署拓扑环境,只通过服务的名字就能够使用服务,提供了一种服务发布与查找的协调机制。服务发现除了提供服务注册、目录和查找三大关键特性,还需要能够提供健康监控、多种查询、实时更新和高可用性等。
有两种主要的服务发现方式:客户端发现(client-side service discovery)和服务端发现(server-side discovery)
1.1 客户端服务发现
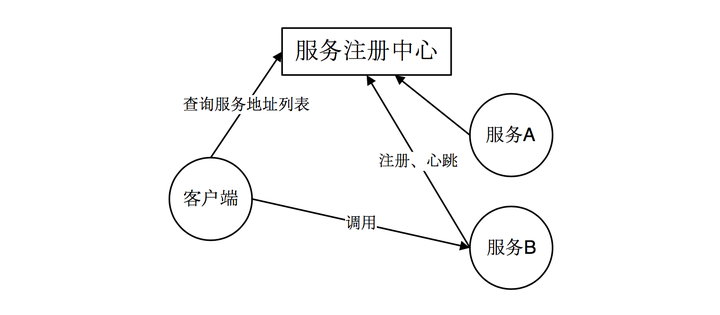
在使用客户端发现方式时,客户端通过查询服务注册中心,获取可用的服务的实际网络地址(IP 和端口)。然后通过负载均衡算法来选择一个可用的服务实例,并将请求发送至该服务。优点:架构简单,扩展灵活,方便实现负载均衡功能,缺点:强耦合,有一定开发成本。
1.2 服务端服务发现
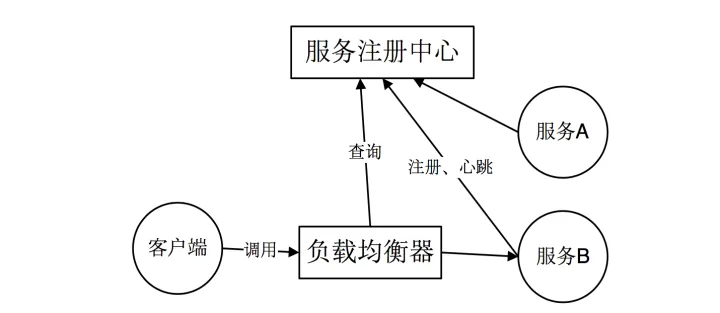
客户端向load balancer 发送请求。load balancer 查询服务注册中心找到可用的服务,然后转发请求到该服务上。和客户端发现一样,服务都要到注册中心进行服务注册和注销。优点:服务的发现逻辑对客户端是透明的。缺点:需要额外部署和维护高可用的负载均衡器。
1.3 服务注册中心
服务注册中心是服务发现的核心。它保存了各个可用服务实例的网络地址(IP Address 和Port)。服务注册中心必须要有高可用性和实时更新功能。有两种不同的方式来处理服务的注册和注销。一种是服务自己主动注册-自己注册。另一种是通过其他组件来管理服务的注册-第三方注册。
自己注册
使用 Self-Registration 的方式注册,服务实例必须自己主动的到注册中心注册和注销。比如可以使用 heartbeat 机制了实现。优点,非常简单,不需要任何其它辅助组件。缺点:各个服务和注册中心的耦合度比较高。
第三方注册
服务本身不必关心注册和注销功能。而是通过其他组件来实现服务注册功能。可以通过如事件订阅等方式来监控服务的状态,如果发现一个新的服务实例运行,就向注册中心注册该服务,如果监控到某一服务停止了,就向注册中心注销该服务。
二、常见的服务发现框架
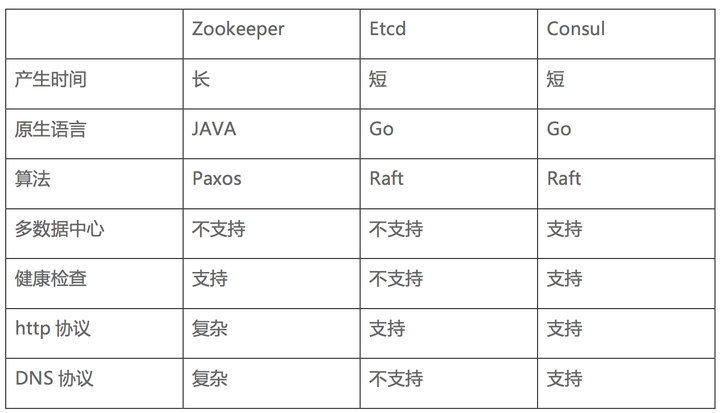
常见服务发现框架 Consul、 ZooKeeper以及Etcd
ZooKeeper 是这种类型的项目中历史最悠久的之一,它起源于 Hadoop。它非常成熟、可靠,被许多大公司(YouTube、eBay、雅虎等)使用。
Etcd是一个采用 HTTP 协议的健/值对存储系统,它是一个分布式和功能层次配置系统,可用于构建服务发现系统。其很容易部署、安装和使用,提供了可靠的数据持久化特性。搭配一些第三方工具,etcd(健/值对存储系统)+ Registrator(服务注册器) + Confd(轻量级的配置管理工具)
Consul 是强一致性的数据存储,使用 Gossip 形成动态集群。它提供分级键/值存储方式,不仅可以存储数据,而且可以用于注册器件事各种任务,从发送数据改变通知到运行健康检查和自定义命令
2.1 Consul 介绍
Consul 是一个支持多数据中心分布式高可用的服务发现和配置共享的服务软件,Consul 支持健康检查,并允许 HTTP 和 DNS 协议调用 API 存储键值对。一致性协议采用 Raft 算法,用来保证服务的高可用。使用 Gossip 协议管理成员和广播消息。
服务发现
Consul 的某些客户端可以提供一个服务,其它客户端可以使用 Consul 去发现这个服务的提供者,可以使用 DNS 或者 HTTP。
故障检测
通过健康检查,服务发现可以防止请求被路由到不健康的主机,并且可以使服务容易断开(不再提供服务),如服务是否返回 200 OK、内存使用率是否在 90% 以下。
多数据中心
Consul 不需要复杂的配置即可简便的扩展到多个数据中心,查找其它数据中心的服务或者只请求当前数据中心的服务。
键值存储
灵活的键值存储,提供动态配置、特征标记、协作、Leader 选举等功能,通过长轮询实现配置改变的即时通知。
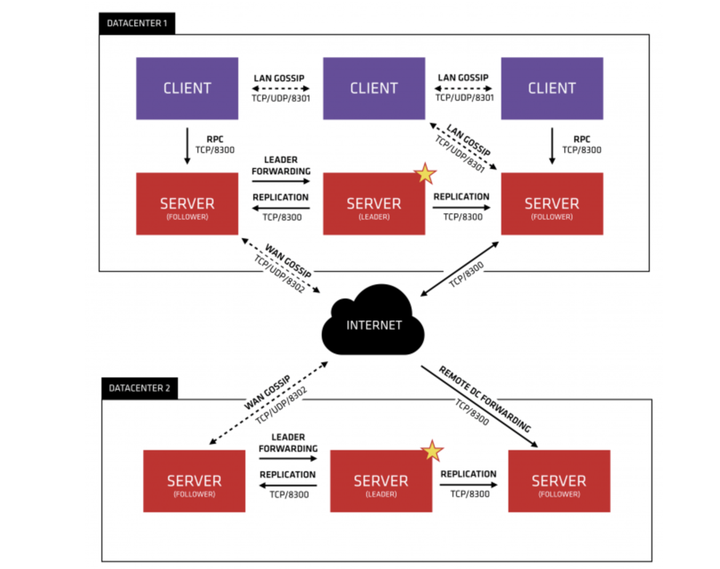
Agent - Agent 是在 Consul 集群的每个成员之上长期运行的一个守护进程, 是 Consul 的核心进。Agent 必须运行。Agent 可以运行在 Server 模式或者 Client 模式,由于所有的节点都必须运行一个 Agent,所有的节点都可以运行 DNS 和 HTTP 接口,以及负责运行健康检查和保持服务同步。
Server - Server 是具备一组扩展职责的 Agent,包括:参与 Raft 法定人数,维护集群状态,响应 RPC 请求,与其它数据中心交换广域网流言,以及转发请求到 Leader 或者远程数据中心。每一个数据中心至少要有一个 Server,推荐要有3-5个 Server。
Client - Client 是转发所有 RPC 到 Server 节点的 Agent。Client 是一个非常轻量级的进程,用来注册服务,运行健康检查,以及转发查询到 Server。Client 是相对无状态的。Client 执行的唯一的后台活动是参与局域网的流言池。这只有一个很小的资源开销,并且只消耗少量的网络带宽。
2.2 Raft 算法
一致性协议采用 Raft 算法,一致性(Consensus),它是指多个服务器在状态达成一致,但是在一个分布式系统中,因为各种意外可能,有的服务器可能会崩溃或变得不可靠,它就不能和其他服务器达成一致状态。这样就需要一种 Consensus 协议,一致性协议是为了确保容错性,也就是即使系统中有一两个服务器当机,也不会影响其处理过程。
为了以容错方式达成一致,我们不可能要求所有服务器 100% 都达成一致状态,只要超过半数的大多数服务器达成一致就可以了,假设有 N 台服务器,N/2 +1 就超过半数,代表大多数了。
在 Raft 中,任何时候一个服务器可以扮演下面角色之一:
Leader: 处理所有客户端交互,日志复制等,一般一次只有一个 Leader.
Follower: 选民,完全被动
Candidate: 可以被选为一个新的领导人。
Raft 阶段分为两个,首先是选举过程,然后在选举出来的领导人带领进行正常操作,比如日志复制等。
选举过程
任何一个节点都可以成为 Candidate,Follower 会等待一个随机时间 election timeout (150ms-300ms) 后成为 Candidate, Candidate 会向其他节点发送选举请求,其他节点会回复这个请求,当绝大多数节点同意时,Candidate 成为 Leader,如果在这个过程中,有一个 Follower 宕机,没有收到请求选举的要求,Candidate 可以自己选自己,只要达到 N/2 + 1 的大多数票,Candidate 还是可以成为 Leader的。
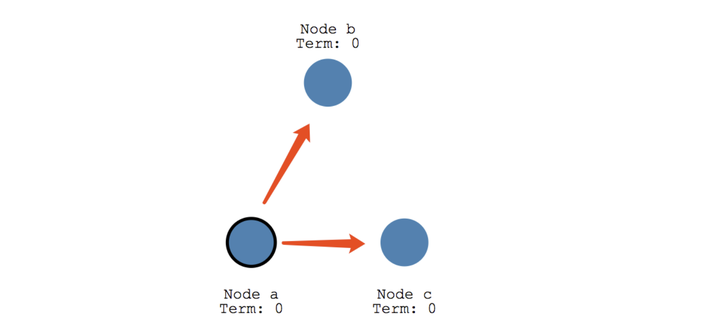
如果同时有两个候选人向大家邀票,这时通过类似加时赛来解决,两个候选者在一段 timeout比如 300ms 互相不服气的等待以后,因为双方得到的票数是一样的,一半对一半,那么在300ms 以后,再由这两个候选者发出邀票,这时同时的概率大大降低,那么首先发出邀票的的候选者得到了大多数同意,成为领导者 Leader,而另外一个候选者后来发出邀票时,那些Follower 选民已经投票给第一个候选者,不能再投票给它,它就成为落选者了,最后这个落选者也成为普通 Follower 一员了。
当一个 Leader 产生之后,它可以向选民也就是 Follower 们发出指令,比如进行日志复制。
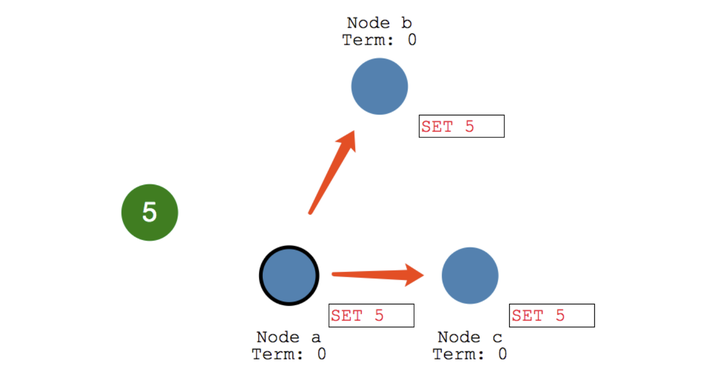
Raft 协议强依赖 Leader 节点的可用性来确保集群数据的一致性。当 Leader 产生之后,所有的更改都会通过 Leader,比如客户端发出一个更改,Leader 会将这个更改写入日志中,并通过心跳向 Follower 们发出一个日志复制的指令,当 Follow 将日志写入磁盘之后会发出一个response,当 Leader 收到绝大多数 response 则认为这个更改被提交,并会在下一个心跳的时候,通知所有 Follow 进行更新。
Raft 协议过程可参看动画:http://thesecretlivesofdata.com/raft/
2.3 Gossip协议
当一个Consul Agent 启动后,它没有任何其它节点的知识:它是一个孤立的集群。想了解其它的集群成员,Agent 必须加入一个已经存在的集群。要加入已经存在的集群,它只需要知道一个已经存在的成员。Agent 加入后,它将通过流言协议和这个成员进行交流,并很快的发现集群中的其它成员。Consul Agent 可以加入任何一个其它的 Agent,不只是 Server 模式的Agent。
Gossip 是一个点对点的通信协议,在这个协议中,节点之间定期交换状态信息。Gossip 协议每隔一秒运行一次,节点和不超过的三个节点交换信息,因此所有的节点能够很快知道集群中其他节点的信息。每一个 gossip 信息有一个版本,因此在信息的交换中,旧的信息会被新的状态信息覆盖。
首先要传播谣言就要有种子节点。种子节点每秒都会随机向其他节点发送自己所拥有的节点列表,以及需要传播的消息。任何新加入的节点,就在这种传播方式下很快地被全网所知道。
-
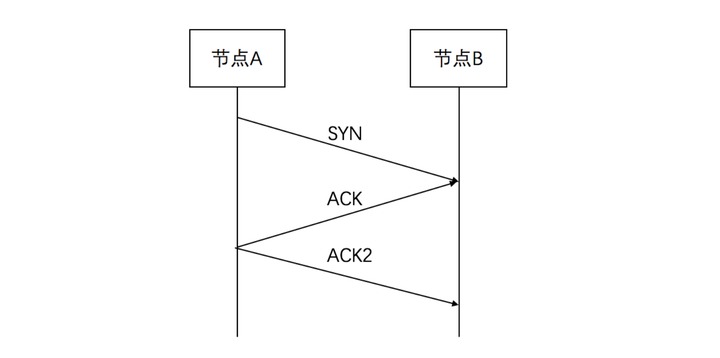
SYN: 节点 A 随机选择一些节点,这里可以只选择发送摘要,即不发送value,避免消息过大。
-
ACK: 节点 B 接收到消息后,会将其与本地的合并,这里合并采用的是对比版本,版本较大的说明数据较新。
比如节点 A 向节点 B 发送数据 C (key, value, 2),而节点 B 本机存储的是 C (key, value1, 3),那么因为 B 的版本比较新,合并之后的数据就是B本机存储的数据,然后会发回 A 节点。 -
ACK2: 节点 A 接收到 ACK 消息,将其应用到本机的数据中。
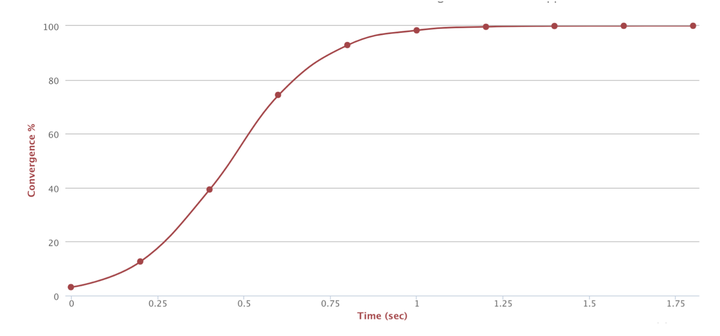
下图是对Gossip协议收敛情况的模拟
Gossip interval:0.2 秒
节点数:30 nodes
gossip fanout:3 nodes
参考文献
- 微服务系统中的服务发现机制 http://www.jianshu.com/p/ece3e0ffc70c
- Consul 源码地址 https://github.com/hashicorp/consul
- Consul 可执行文件地址 https://www.consul.io/downloads.html
- Consul 官方地址 https://www.consul.io/
- Consul 官方演示 http://demo.consul.io/ui/
- 服务发现系统Consul介绍 http://www.codeweblog.com/服务发现系统consul介绍/
- Consul 原理和使用简介 https://blog.coding.net/blog/intro-consul?type=hot
- Consul 修炼 http://blog.csdn.net/column/details/consul.html
- Consul 调研 http://blog.csdn.net/younger_china/article/details/52243700
- 分布式系统的Raft算法 http://www.jdon.com/artichect/raft.html
- Raft 动画 http://thesecretlivesofdata.com/raft/
- Raft 一致性算法 http://blog.csdn.net/cszhouwei/article/details/38374603
- Raft 为什么是更易理解的分布式一致性算法 https://www.cnblogs.com/mindwind/p/5231986.html
- 节点间通信协议之gossip协议 https://www.cnblogs.com/dyf6372/p/3528193.html
- Cassandra 学习笔记之 Gossip 协议 http://blog.csdn.net/aesop_wubo/article/details/20401431
- Consul 集群架构 http://blog.csdn.net/maoyeqiu/article/details/77478732
- 初识服务发现及Consul框架的简单使用 https://www.cnblogs.com/newP/p/6349316.html
- Consul 的整体架构 http://blog.csdn.net/u012422829/article/details/77887753
- 服务发现:Zookeeper vs etcd vs Consul http://dockone.io/article/667
- 搭建 Consul 集群 https://www.cnblogs.com/shanyou/p/6286207.html
- Gossip 算法 http://blog.csdn.net/chen77716/article/details/6275762
- 分布式系统协调 http://www.cnblogs.com/shanyou/p/4714838.html
- Gossip 协议实现 https://segmentfault.com/a/1190000010635808

 浙公网安备 33010602011771号
浙公网安备 33010602011771号