Hive
Hive简介
Hive 是一种大数据处理工具,使用类SQL 的HiveQL 语言实现数据查询,它底层封装了Hadoop ,所有Hive 的数据都存储在Hadoop 兼容的HDFS中。
更官方的描述:
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
简单点说:
Hive就是一个大数据处理工具,它可以把开发者编写的SQL转换为MapReduce或Spark任务(对HDFS或HBase上的数据进行处理),这样开发者可以用更简单的方法(编写SQL语句)开发大数据程序。
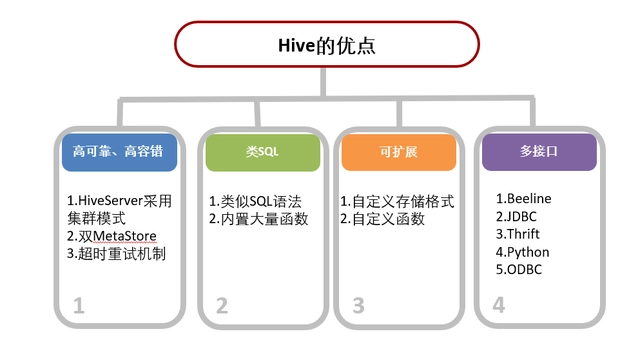
Hive的优点
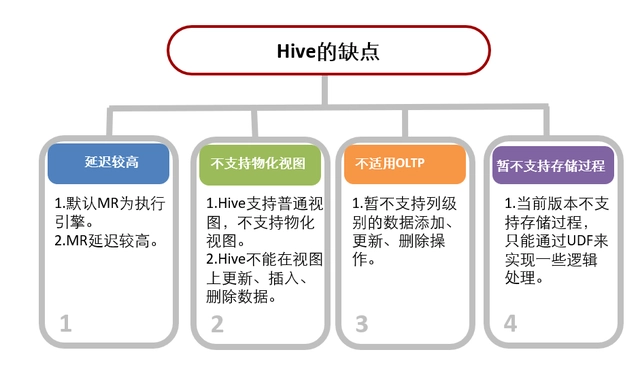
Hive缺点
Hive数据存储模型
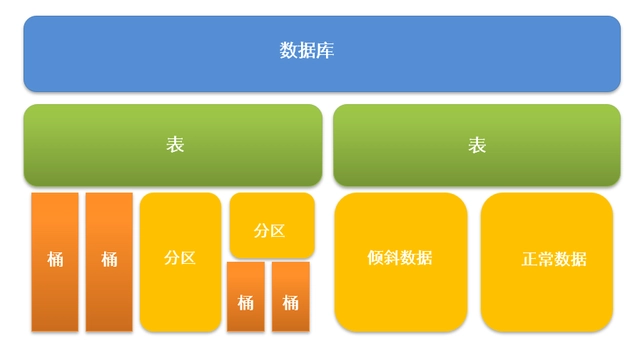
数据库:创建表时如果不指定数据库,则默认为default数据库。
表:物理概念,实际对应HDFS上的一个目录。
分区:对应所在表所在目录下的一个子目录。
桶:对应表或分区所在路径的一个文件
Hive支持的函数
数学函数,如round(),floor(),abs(),rand()等。
日期函数,如to_date(),month(),day()等。
字符串函数,如trim(),length(),substr()等
Hive基本操作
创建表
CREATE TABLE IF NOT EXISTS example.employee(
Id INT COMMENT 'employeeid',
Company STRING COMMENT 'your company',
Money FLOAT COMMENT 'work money',)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
查询
SELECT id, name FROM employee WHERE salary >= 10000;
SELECT department, avg(salary) FROM employee GROUP BY department;
SELECT id, salary, date FROM employee_a UNION ALL
SELECT id, salary, date FROM employee_b;
资料:
https://baijiahao.baidu.com/s?id=1661040592082632323&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/95923527
https://www.cnblogs.com/wenBlog/p/12163444.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号