推荐系统:召回、粗排、精排
排序系统
排序系统一般分为:召回和排序两个阶段。其中排序又分了粗排和精排。
召回
召回的目标是从千万级甚至亿级的候选中召回几千个,召回一般由多路组成,每一路会有不同侧重点(优化目标)。在推荐系统中,不同路代表了不同的优化目标。
排序
排序阶段就是把召回的结果进行排序,把topK(k一般都是个位数)结果作为推荐系统最终输出。区分粗排和精排,其实就是生成环境中成本和结果的一个平衡。
粗排
进入排序阶段的候选集一般很多,要考虑计算速度和成本,此时依然不能使用太复杂的模型和特征。
精排
经过粗排后,候选集已经比较少了,因此精排可以模型和特征做到极致,可以达到非常高的精度。
蜻蜓FM 推荐
推荐系统算法流程
级联结构简单,分工明确。兼顾了覆盖度、性能、准确性和多样性。
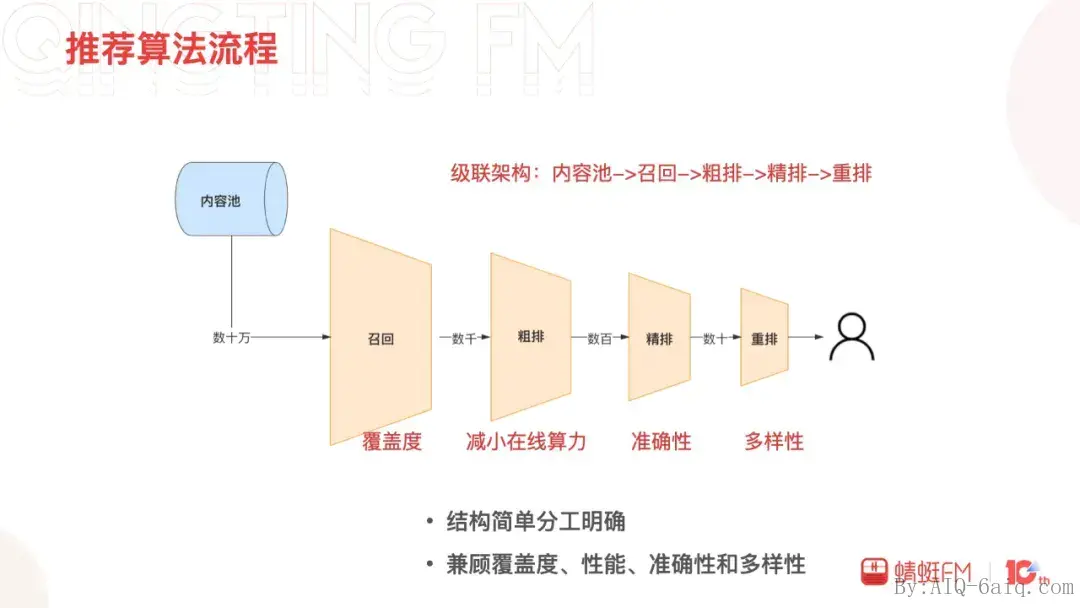
推荐算法的流程大致如下:内容池中达到推荐标准的内容的有几十万个,召回层从中选出用户可能喜欢的几千个进入粗排层,召回层的覆盖度决定了整体推荐内容的覆盖上限。粗排层从召回结果中挑选出几百个给到精排层,粗排层主要为了减小在线算力减轻精排的压力。精排层选几十个给到重排层,精排层专注于推荐的准确性。最后,重排层对推荐结果进行重新排序给到用户,这一层兼顾准确性的同时还需要保证多样性。
级联结构简单,分工明确。兼顾了覆盖度、性能、准确性和多样性。
多路召回
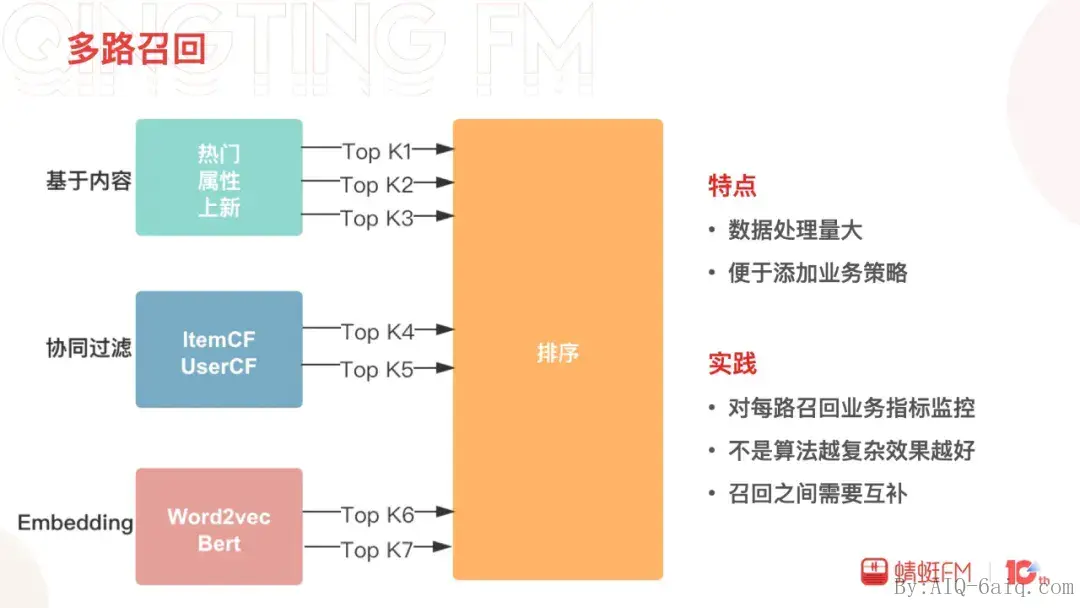
熟悉了推荐的算法的大致流程后,首先,我们来了解一下多路召回。多路召回在蜻蜓主要分为三类:基于内容、协同过滤和Embedding向量召回。基于内容的召回包括热门、属性、上新策略的召回;协同过滤包括User Based和Item Based;Embedding向量召回有Word2vec和Bert。召回环节处理的数据量大,复杂度不能太高,多路召回的设计可以方便加入新的策略或者算法。我们在实践中发现,早期建立完善指标,追踪每路召回的效果,有助优胜劣汰;召回的效果并不是召回算法越复杂越好,不同的业务特点不一样适合的召回也可能不一样,比如蜻蜓当下表现最优的召回来自ItemCF和热门;随着召回的算法越加越多,新的召回需要与现有召回有差异性、互补才会有存在的价值。召回环节还会承载业务及平台建设的使命比如用户和物品的冷启动、业务流量扶持等,召回环节的好坏直接决定了后续环节的上限。
粗排
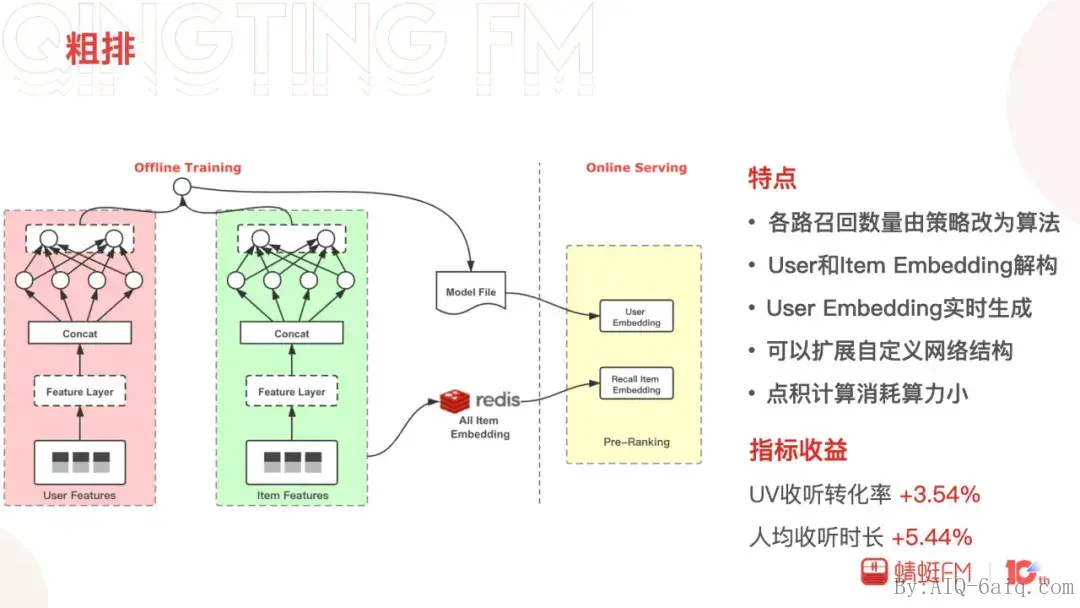
接着是粗排,早期的推进系统中粗排常常用简单的融合策略进行,实践中发现粗排中引入算法是值得的。策略的组合较多测试周期长,双塔模型的应用既解决了多路召回组合的效率问题,又避免了精排的性能问题。
双塔模型扩展性好便于自由添加自定义的网络,User和Item塔解偶,同时点积的计算所需算力小。在蜻蜓为了保障粗排推理数据的实时性,User向量的生成及点积的计算都是实时的。粗排的加入在数据指标指标上也获得了不错的收益,其中信息流UV收听转化率增加了3.54%,人均收听时长增加了5.44%。
精排
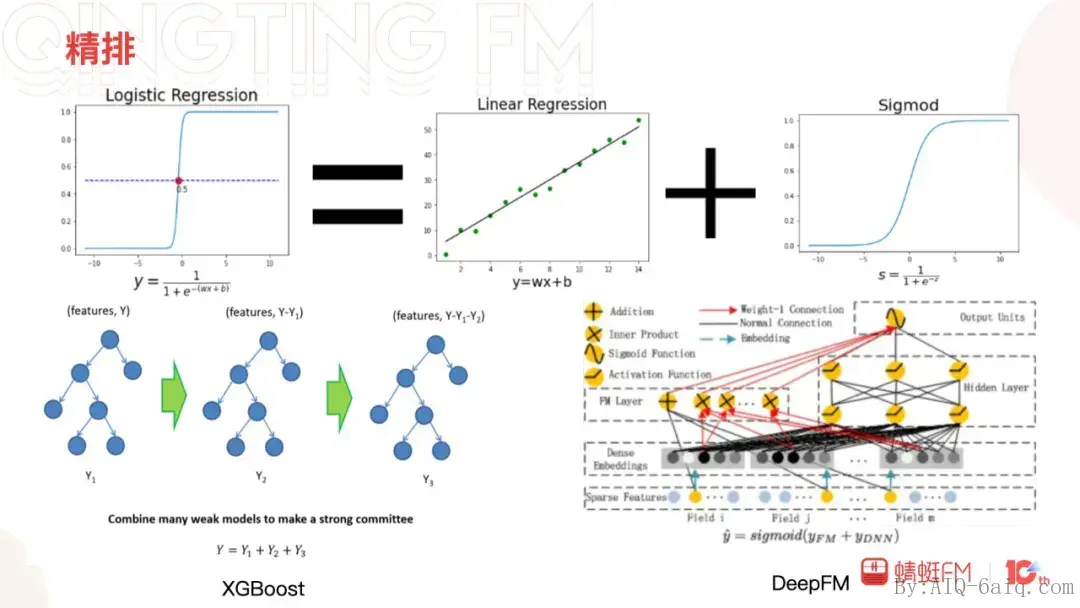
然后是精排,精排往往在推荐系统中最受关注,精排直接对准确性负责,相对容易拿到直接的收益。我们在精排的投入相对较大,从中获得的收益也相对颇多。蜻蜓的精排经历了三个阶段:线性模型的逻辑回归和FM、树模型的XGBoost以及神经网络模型的DeepFM。
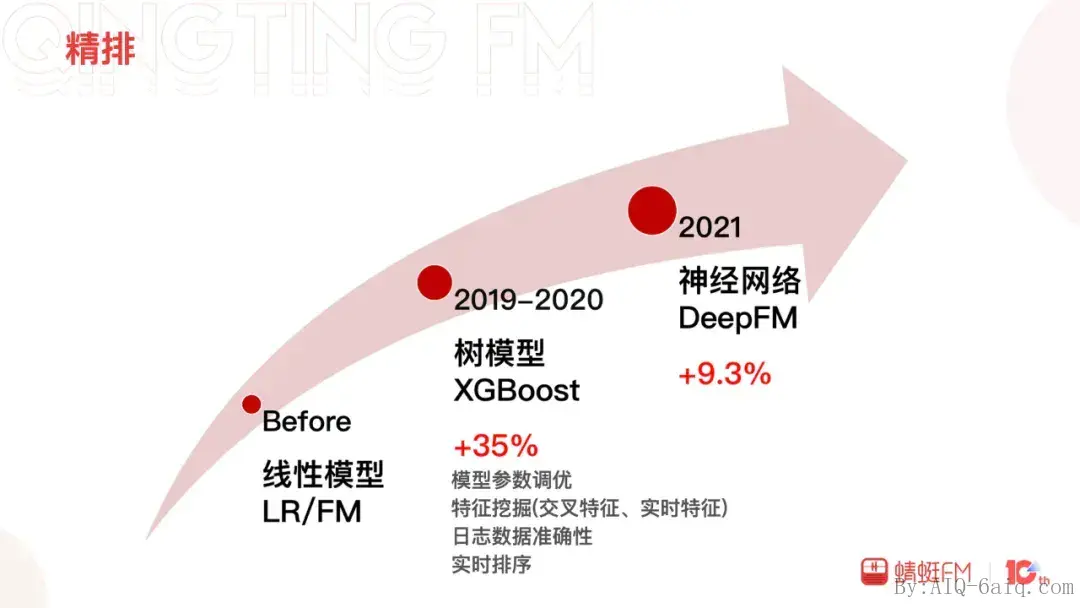
XGBoost迭代时间最久,其中模型参数的调优、特征挖掘(包括交叉特征和实时特征的引入)、日志数据的准确性优化以及实时排序,这些整体给在线收听数据带来了近35%的提升。XGBoost之后我们尝试过许多模型包括XGBoost+LR,Wide&Deep等均没有取得预期的收益,在DeepFM上的尝试探索则获得了9.3%收听相关指标的提升。DeepFM顺理成章地成为了精排模型的主力,也开启了蜻蜓推荐算法在深度学习道路上的大门。
重排

最后是重排,重排跟召回一样承载了很多业务向的目标和期许。这里主要讲一下多样性,提升多样性一方面希望打破推荐系统的信息茧房,另一方面也希望提升用户的长期使用体验。开始是通过打散策略实现,当前主要是MMR和DPP两个算法在尝试迭代,实验中MMR表现优于DPP,这里简单介绍一下。MMR(Maximal Marginal Relevance)最大边际相关性算法,保证相关性的同时提高多样性。通过λ参数来调节多样性和相关性的权重,λ越大相关性越高,λ越小则多样性越高。
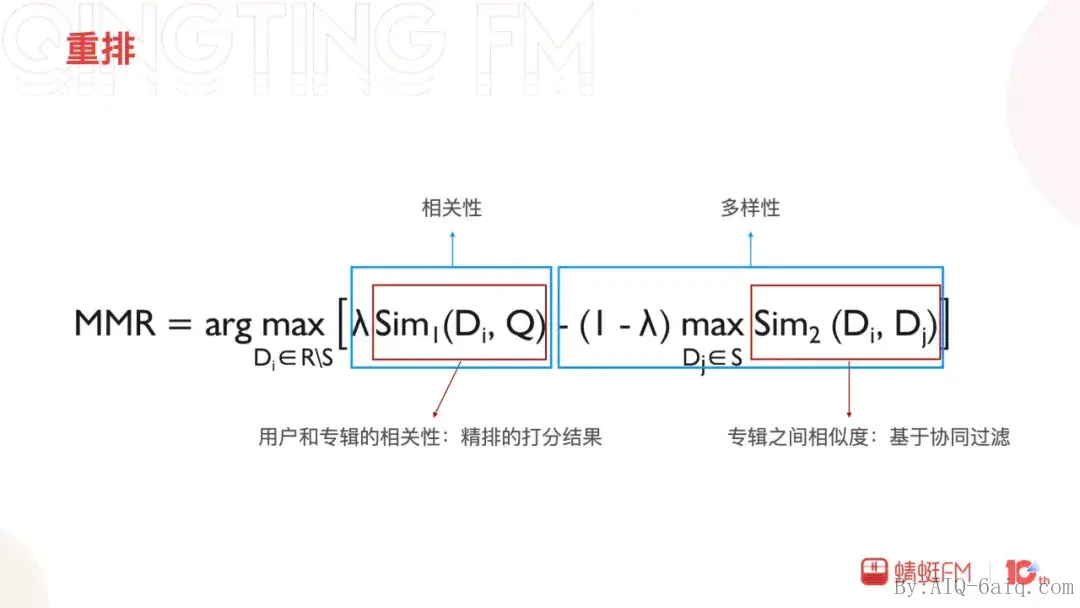
MMR算法中有两个相似度,用户和物品的相似度用精排的打分值来表示,物品之间的相似度基于协同过滤的物品相似度。重排的预期是达到帕累托最优,在其他指标都不降低的情况下,提升多样性指标。最终也达到了预期,人均曝光专辑数量增加8.84%,人均收听二级分类数量提升7.06%。
架构
整体架构
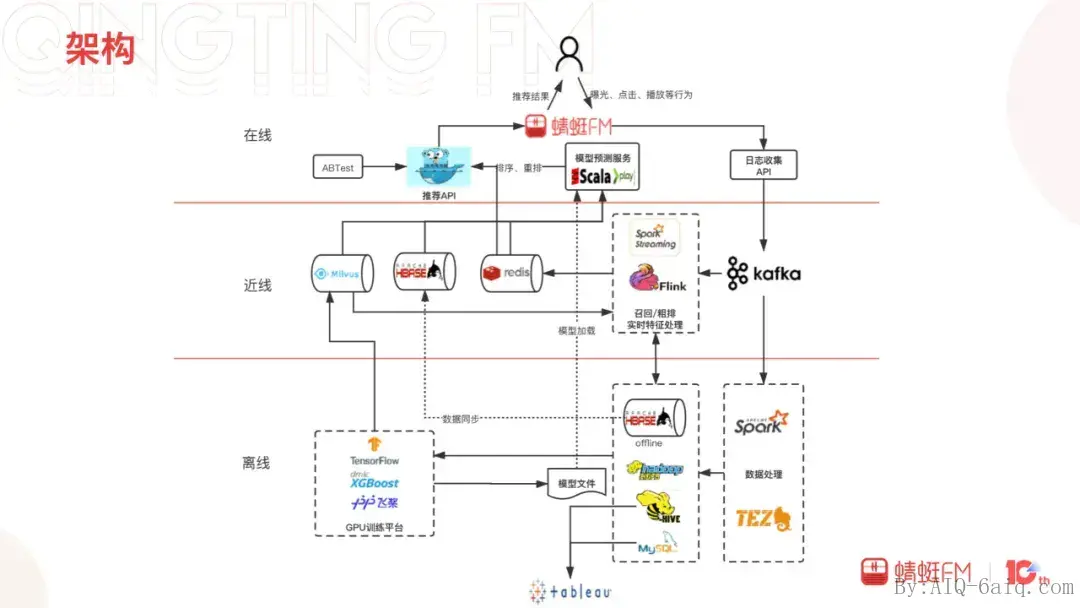
推荐系统能高效稳定地运作,离不开优秀的架构支持。蜻蜓的推荐架构是典型的三层架构,即离线、近线、在线三层。离线层负责数据的处理、模型的训练以及数据报表;近线层实时特征处理、召回、粗排;在线层承载了用户请求响应、精排、重排以及投放系统等业务逻辑。
算法模型部署
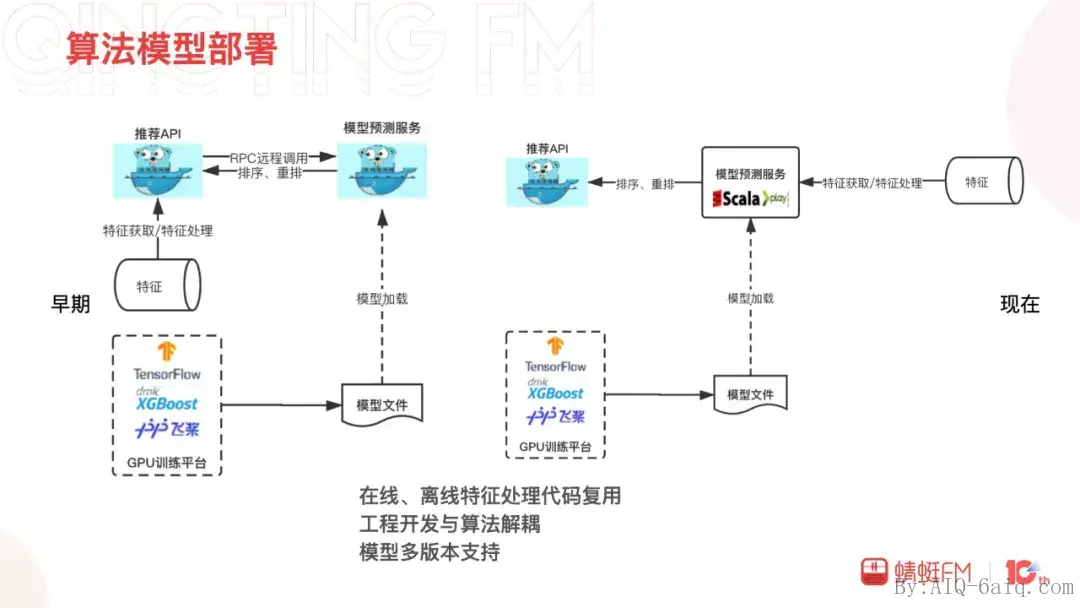
算法模型如何高效地部署到线上?是算法和工程同学共同面临的挑战。开始的时候我们的模型预测服务和推荐API都是用Golang实现,特征的获取处理在推荐API测完成,模型预测服务负责加载模型并对对获取的数据进行预测。在线特征拼接处理使用Golang,离线特征拼接处理使用Scala,跨语言的对齐与校验耗费了开发很多的时间。离线和在线能否公用一套算子进行特征的拼接与处理?为此我们将模型预测服务切换成了Scala的Play框架,基于Scala开发出了一个feature获取处理的库,给Spark和Play共同使用,保证了特征处理逻辑层面的一致性。同时,模型预测服务中增加了对多模型、多版本的支持以及模型的自动更新进一步提高了模型部署的效率。
展望
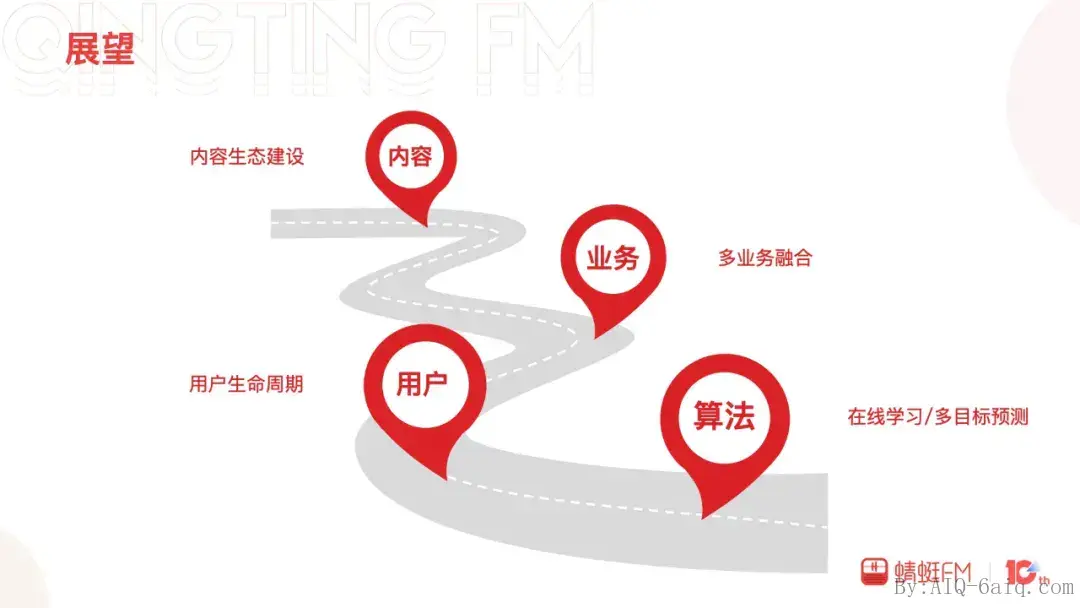
首页信息流推荐从0到1建立起来,迭代、优化、完善到现在取得了不错的增长,面向未来还有许多工作需要我们去尝试和探索。内容方面,如何帮助新品内容一步一步变成曝款,产品、研发、运营如何合作建立出完善的内容生态系统;业务方面,信息流支持的业务越来越多包括专辑、直播、听单、节目、广播等,多业务如何更好的融合在一起也是一个挑战;用户方面,新用户的冷启动,沉默用户、潜在流失用户如何激活还有很长的路要走;算法方面,模型的训练如何做到更加实时,多目标的排序是否有望代替单目标排序。这些都将是我们接下来探索的方向。
资料:
https://wenku.baidu.com/view/89326fdfadf8941ea76e58fafab069dc5022470b.html
https://www.zhihu.com/question/376156175
https://zhuanlan.zhihu.com/p/502646853
https://www.zhihu.com/question/376156175
https://www.6aiq.com/article/1622071506236

 浙公网安备 33010602011771号
浙公网安备 33010602011771号