使用cycle构造无限循环迭代器
一、引入方式
from itertools import cycle
二、使用方法
我们先来看看它的源码
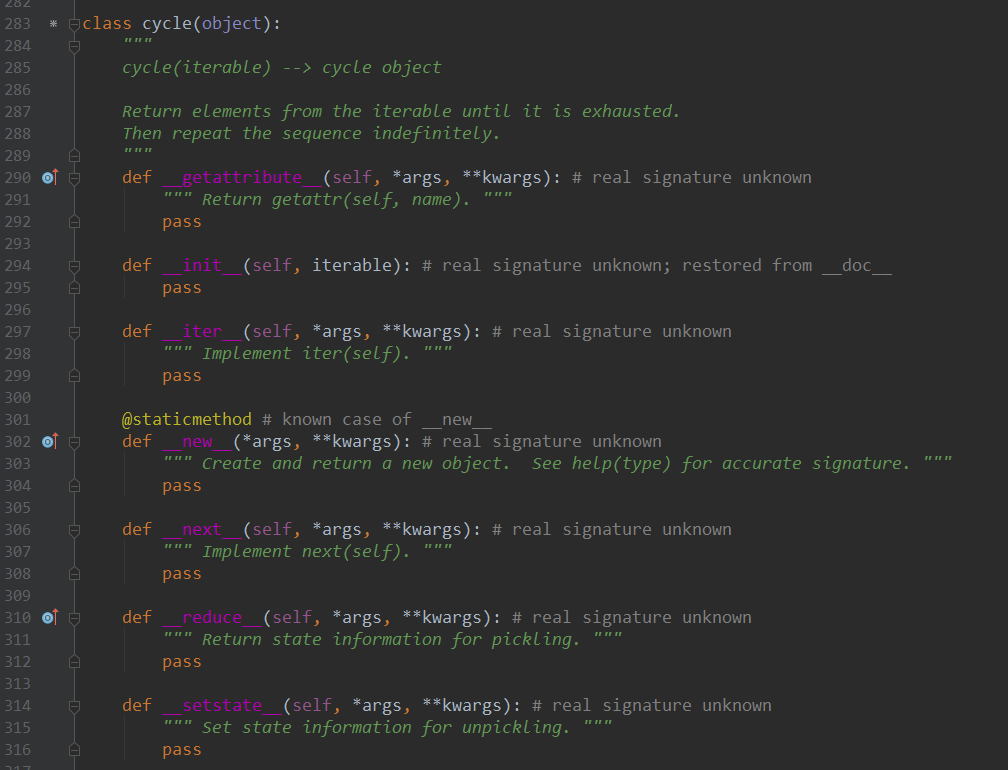
cycle它接收一个可迭代对象,可以将一个可迭代对象转换为一个可以无限迭代的迭代器
源码里我们可以看到它实现了__iter__和__next__的魔术方法,说明它既是可迭代对象也是一个迭代器,我们可以使用for循环和next()方法去操作它
我们先来看看以普通的方式去遍历一个列表
li = ['python', 'java', 'c', 'ruby', 'php', 'javascript'] for i in li: print(i)
打印结果:
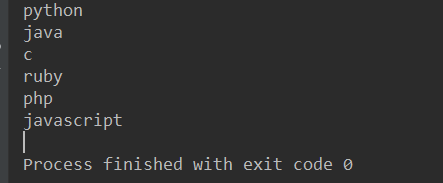
可以看到,遍历直到最后一个元素取完后就不再遍历了
接下来我们使用cycle来创建一个无限迭代的迭代器
from itertools import cycle li = ['python', 'java', 'c', 'ruby', 'php', 'javascript'] cycle_iter = cycle(li) for i in cycle_iter: print(i)
打印结果:
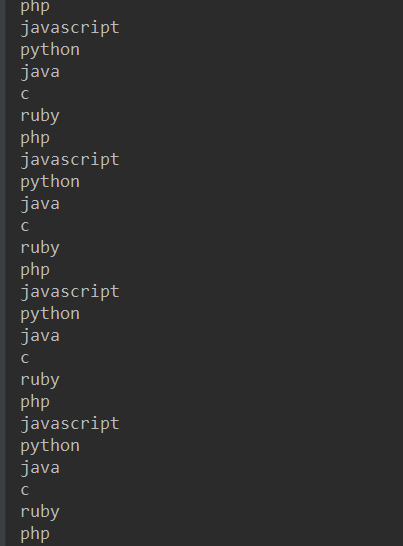
......
我们可以发现当遍历到最后一个元素结束后又会回到第一个元素,就这样无限循环下去形成了死循环,跟while死循环很相似
接下来我们使用next()进行迭代,看看会发生什么
from itertools import cycle li = ['python', 'java', 'c', 'ruby', 'php', 'javascript'] cycle_iter = cycle(li) print(next(cycle_iter)) print(next(cycle_iter)) print(next(cycle_iter)) print(next(cycle_iter)) print(next(cycle_iter)) print(next(cycle_iter)) print(next(cycle_iter)) print(next(cycle_iter))
打印结果: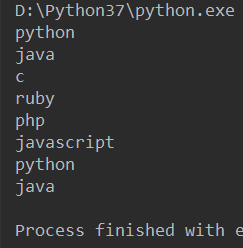
我们发现当最后一个元素迭代完后,又继续迭代第一个元素,这跟普通的迭代器不一样,普通的迭代器最后一个元素迭代完后继续迭代,会抛出迭代停止的异常
三、应用场景
准备一批数据需要循环使用,并且需要一定的顺序,并不希望随机选取一个使用,这时cycle就起到了很好的作用,以我工作中为例,需要针对某知名网站爬取数据时,网站对你的请求频率做了限制,而你又需要更高效的获取这些数据,就可以使用cookie池,在循环发起请求时,就可以用next()方法按顺序去迭代获取cookie池中的数据用来发送请求,迭代完最后一个cookie后,又会回到第一个cookie,这样一来,当账号比较多时,每个账号使用到的频率时间就不会太大,也就达到了预期效果,部分代码截图示例:
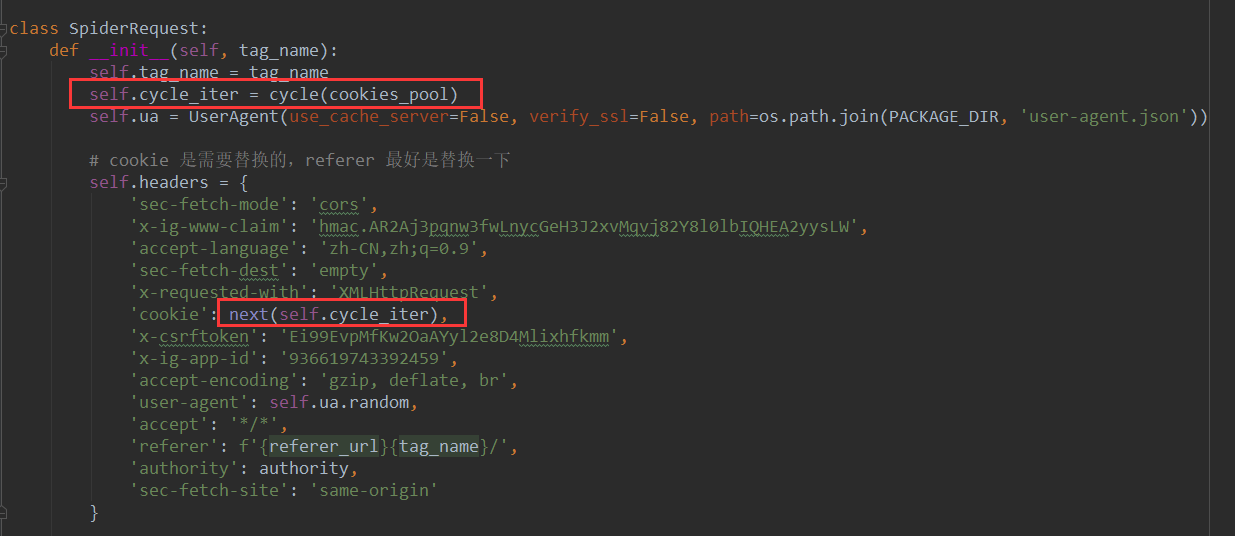
温馨提示:爬虫一定要遵守网络相关法律,切不要存侥幸心理去触碰法律的底线,遵守被爬取对象的安全要求,不要暴力爬取,不要爬取涉及到安全和隐私的相关信息!
-------------------------------------------
个性签名:不忘初心,方得始终!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

