DRF框架serializer反序列化校验之validators
反序列化过程中,除了校验字段类型和长度大小之外,还需要有其它的条件限制的校验,这时我们可以使用validators自定义校验项
一、唯一字段校验
1.引入validators模块
from rest_framework import validators
2.在需要唯一校验的字段类里面设置validators字段的属性,值为一个列表,在列表里面添加唯一校验UniqueValidator,除了UniqueValidator的唯一校验,还有其它的唯一校验,根据不同的场景选择使用即可

唯一校验UniqueValidator类一般接收两个参数,一个是queryset,需要传一个查询集,一个是message,为自定义的异常校验信息,代码如下:
from rest_framework import serializers from rest_framework import validators from .models import Projects class ProjectSerializer(serializers.Serializer): name = serializers.CharField(max_length=200, label="项目名称", help_text='项目名称', validators=[validators.UniqueValidator(queryset=Projects.objects.all(), message="项目名字段name必须唯一")]) leader = serializers.CharField(max_length=50, label="项目负责人", help_text='项目负责人') programmer = serializers.CharField(max_length=50, label="开发人员", help_text="开发人员") tester = serializers.CharField(max_length=50, label="测试人员", help_text="测试人员")
验证结果:
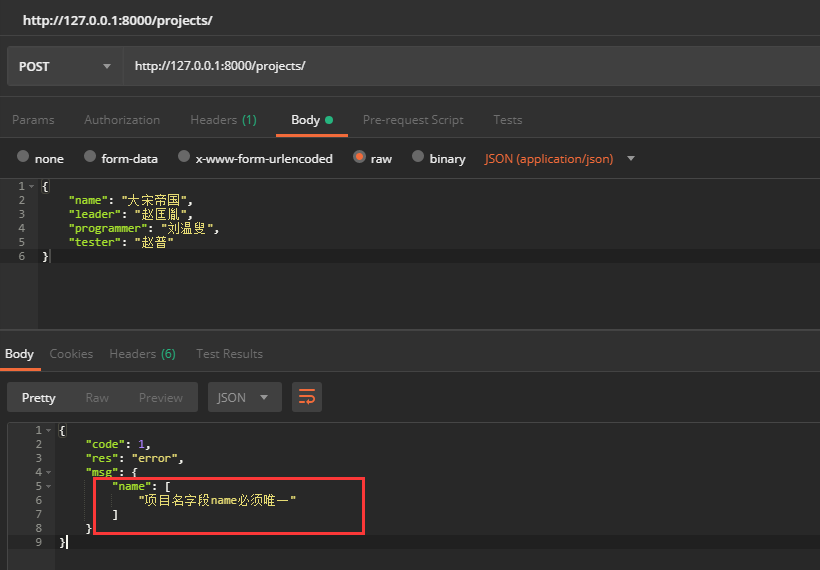
二、自定义校验器函数
假设我们规定name字段不能包含字符“X”,我们可以在类的外面定义一个函数,这个函数需要给定一个形参,用来接收待校验的数据,并且指定条件下要抛出serializers.ValidationError的异常,如果validators字段值的列表中有多个校验规则,校验过程中会全部进行校验,并以列表的形式返回一组异常校验信息
from rest_framework import serializers from rest_framework import validators from .models import Projects def name_is_not_contain_x(value): if 'X' in value.upper(): raise serializers.ValidationError("项目名字段name不能包含x的大小写字符") class ProjectSerializer(serializers.Serializer): name = serializers.CharField(max_length=200, label="项目名称", help_text='项目名称', validators=[validators.UniqueValidator(queryset=Projects.objects.all(), message="项目名字段name必须唯一"), name_is_not_contain_x],) leader = serializers.CharField(max_length=50, label="项目负责人", help_text='项目负责人') programmer = serializers.CharField(max_length=50, label="开发人员", help_text="开发人员") tester = serializers.CharField(max_length=50, label="测试人员", help_text="测试人员")
验证结果:
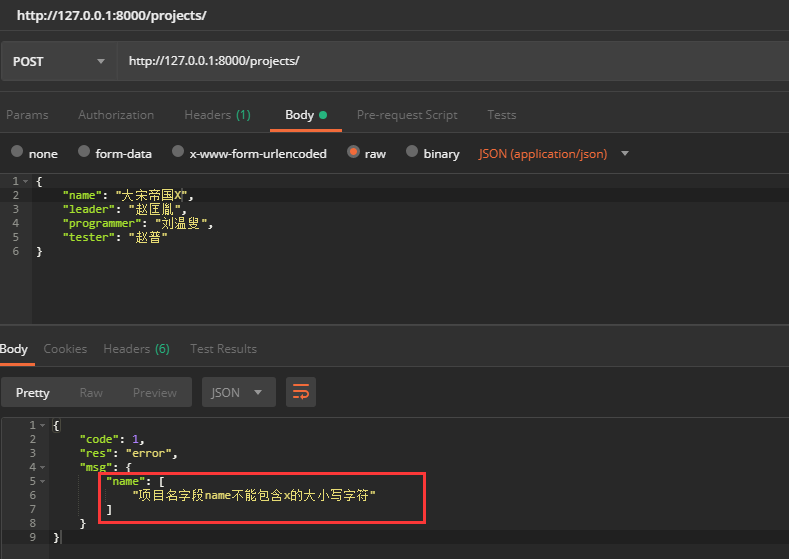
三、自定义校验器方法
上面第二种采用的是在序列化器类外面创建的校验器函数,同样的也可以在类里面创建一个校验器方法,不同的有以下几点:
- 方法名必须以validate_作为前缀,后缀为对应的字段名
- 一定要返回校验之后的值
- 不需要放在validators的列表中就可以生效
def validate_name(self, value): if '项目' in value: raise serializers.ValidationError("项目名称name字段不能包含‘项目’字符") return value
验证结果:
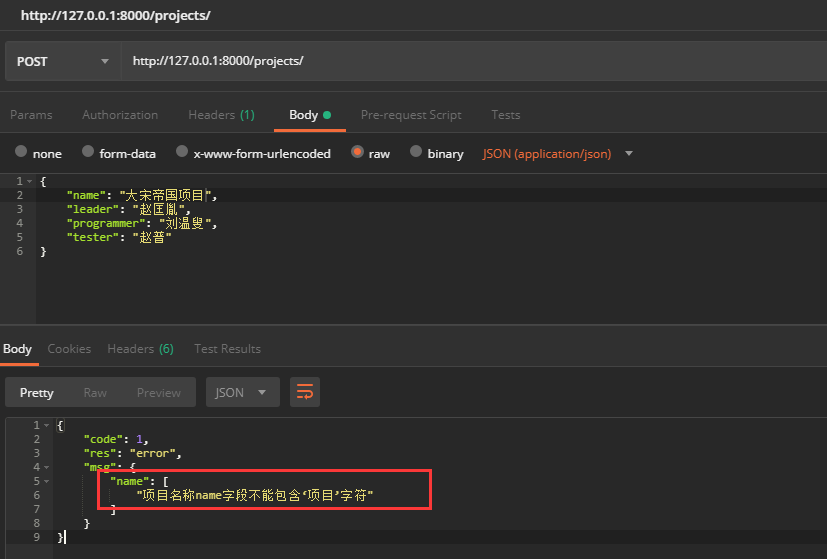
三、自定义多字段校验器方法
- 上面我们都是单字段进行校验,如果是多字段同时进行校验,就需要用到该方法
- 方法名固定为validate,形参固定为attrs
- attrs返回一个QueryDict,字段名可以通过字典的方法进行取值,如:attrs['name'] 或者 attrs.get('name')
- 必须返回attrs
不需要放在validators的列表中就可以生效
def validate(self, attrs): if 'A' in attrs.get('name') and 'B' in attrs.get('leader'): raise serializers.ValidationError("项目名称字段name不包含A的同时项目负责人字段leader也不能包含B") return attrs
验证结果:
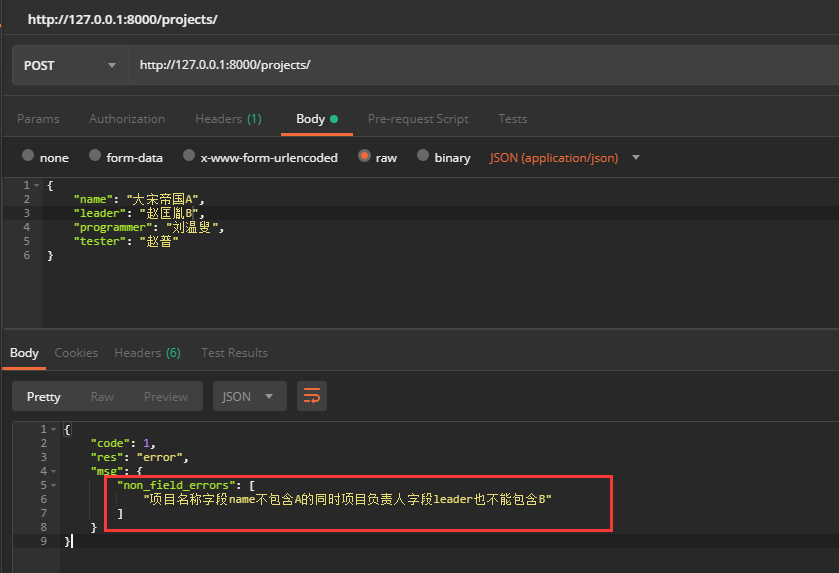
我们可以看到该异常校验信息字段的key并不是我们想要的,接下来我们针对这个key进行修改
我们从DRF的源码settings.py模块中可以找到这个字段配置信息

修改方法:在django项目下的settings.py模块中,修改REST_FRAMEWORK字典中的'NON_FIELD_ERRORS_KEY'的值即可
REST_FRAMEWORK = { 'NON_FIELD_ERRORS_KEY': 'more_errors' }
验证结果: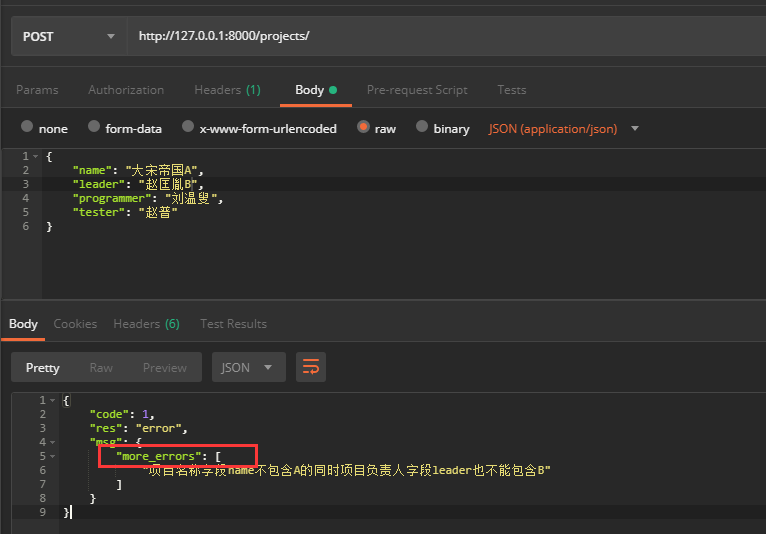
-------------------------------------------
个性签名:不忘初心,方得始终!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号