踩过了这些坑,你真的懂python基础吗?
一、浮点数的计算
- 思考1:打印结果是什么?
a = 0.1 b = 0.2 c = 0.3 print(b == a + a)
- 思考2:打印结果是什么?
a = 0.1 b = 0.2 c = 0.3 print(c == a + b)
是真的都返回True吗?让我们来看看结果:
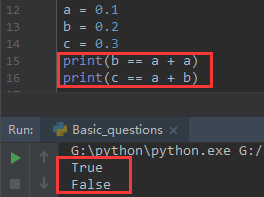
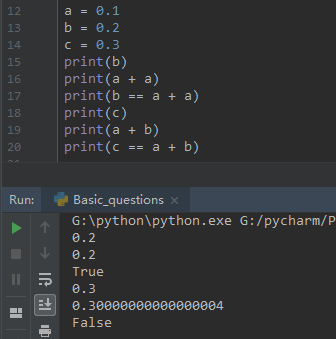
实际上,第一种a+a相当于a*2,所以结果为0.2,浮点数在python存储里面是不精确的,所以不能对浮点型数据直接进行精确计算,可以先转换为整数计算后在转化为浮点数即可,或者使用Decimal库来处理。
二、列表的复制
- 思考:能够使用赋值的方式复制一个列表吗?
star_list = ['吴京', '徐峥', '黄渤', '杨幂'] star_list_copy = star_list
答案是不能,我们可以通过对两个列表添加不同的值打印一下结果:
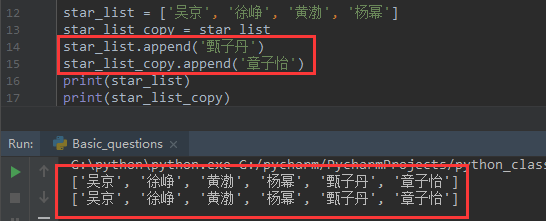
为啥会这样呢?我们可以使用id()方法查看内存地址去判断是否为同一个列表:

结果内存地址是一样的,因此列表不能用赋值的方法去进行复制,我们可以使用以下几种方法:
- 使用for循环结合append方法遍历添加
star_list = ['吴京', '徐峥', '黄渤', '杨幂'] star_list_copy = [] for i in star_list: star_list_copy.append(i) print(star_list_copy)
- 使用extend方法一次性添加
star_list = ['吴京', '徐峥', '黄渤', '杨幂'] star_list_copy = [] star_list_copy.extend(star_list) print(star_list_copy)
- 使用切片方法添加
star_list = ['吴京', '徐峥', '黄渤', '杨幂'] star_list_copy = star_list[:] print(star_list_copy)
- 使用copy内置方法添加
star_list = ['吴京', '徐峥', '黄渤', '杨幂'] star_list_copy = star_list.copy() print(star_list_copy)
三、多继承的深度优先和广度优先
- 思考1:打印结果是什么?
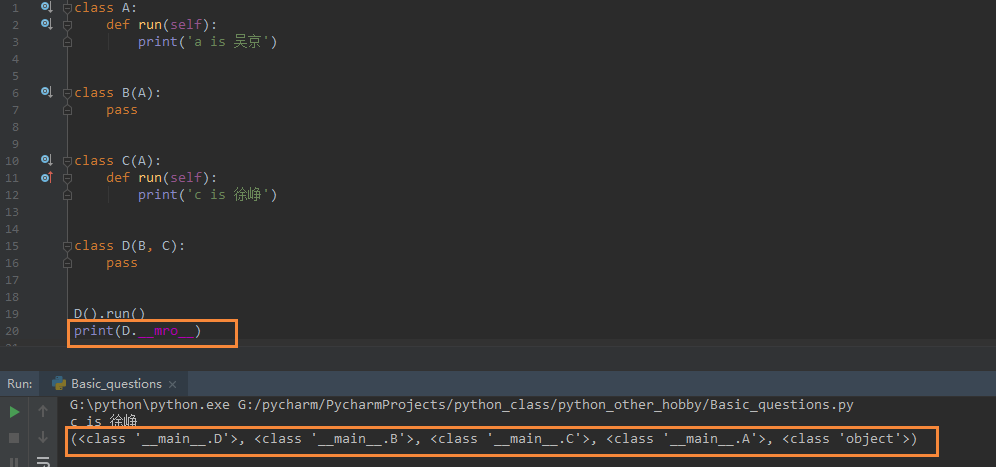
class A: def run(self): print('a is 吴京') class B(A): pass class C(): def run(self): print('c is 徐峥') class D(B, C): pass D().run()
思考2:打印结果是什么?
class A: def run(self): print('a is 吴京') class B(A): pass class C(A): def run(self): print('c is 徐峥') class D(B, C): pass D().run()
问题1,D同时继承了B和C,B又继承了A,在B这条继承上是D->B->A,在C这条继承上是D->C,相当于一个V字形,这个就是典型的V型问题,它采用的是深度优先原则,打印结果为:a is 吴京
问题2,D同时继承了B和C,B和C都继承了A,在B这条继承上是D->B->A,在C这条继承上是D->C->A,相当于一个菱形,这个就是典型的菱形问题,它采用的是广度优先原则,打印结果为:c is 徐峥
以上两种情况使用的是python当中的C3算法来实现的,我们可以使用一种简单的方法来获取他的顺序,即调用__mro__魔术方法
四、列表的清空
- 思考1:打印结果是什么?
star_list = ['吴京', '徐峥', '黄渤', '杨幂'] for i in star_list: star_list.remove(i) print(star_list)
- 思考2:打印结果是什么?
star_list = ['吴京', '徐峥', '黄渤', '杨幂'] for index, value in enumerate(star_list): star_list.pop(index) print(star_list)
列表被清空了吗?没有,让我们先看看结果:

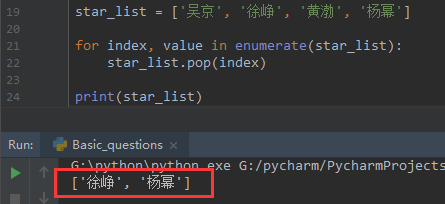
原因是列表本质上是可被修改的,通过for循环,每次删除一个值后,列表就会发生改变,所以不要使用for循环去清空列表的值,建议使用clear方法:
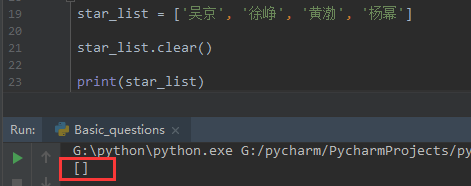
五、列表的 +=
- 思考1:打印结果是什么?
a = [1] a_id = id(a) a += [2] a_id_new = id(a) print(a_id == a_id_new)
- 思考2:打印结果是什么?
a = [1] a_id = id(a) a = a + [2] a_id_new = id(a) print(a_id == a_id_new)
我们先来看结果:
场景1:

场景2:
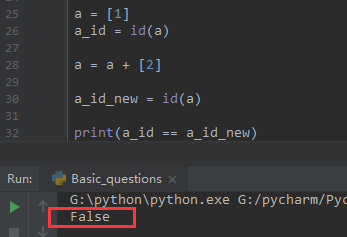
结果却不一样,实际上在列表里面,+=相当于调用了列表的extend方法,仍然还是原来的列表,内存地址没有发生变化,第二种实际上是赋值操作,创建了一个新的列表,所以内存地址发生了改变
六、== 和 is
- 思考:打印结果是什么?
a = [1] b = [1] print(a == b) print(a is b)
都打印为True吗?不是,先看看实际结果:
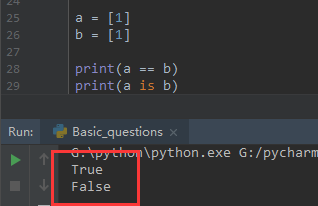
判断列表的时候:
-
- == 比较的是 value(值)是否相等
- is 比较的是 id 是否相同,也即两对象是否指向的同一块内存空间
但是对于数字型或者字符串类型,它们却是一样的。
七、列表的扁平化、列表降维
- 思考:如何将如下的一个列表降维?
star_list = [['吴京', '徐峥'], ['黄渤', '杨幂'], ['甄子丹', '章子怡']]
提供了如下几种方法进行降维操作:
- for循环

- 列表推导式
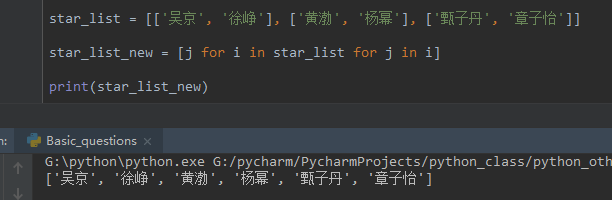
- sum方法
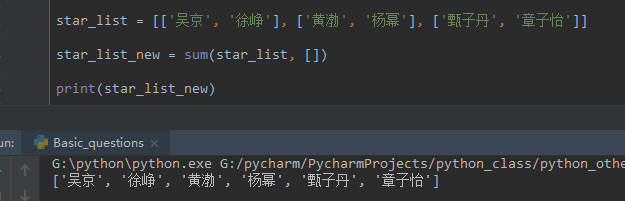
八、列表的可变性
- 思考:打印结果是什么?
def add_movie(movie, movies=[]): movies.append(movie) return movies print(add_movie('战狼2')) print(add_movie('流浪地球', [])) print(add_movie('哪吒'))
先看结果:
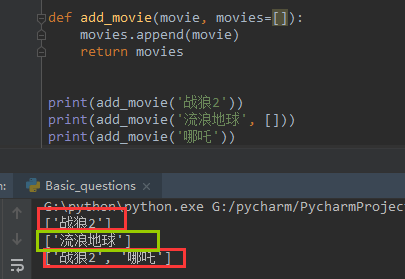
第一个打印和第二个打印都使用的是默认参数列表,所以内存地址没有发生变化,每次增加的值都是在原先的基础上添加值,第二个打印重新传入了一个空列表,此时创建了一个新的列表,内存地址发生了变化,因此它们不是一个列表
-------------------------------------------
个性签名:不忘初心,方得始终!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

