使用CrawlSpider类抓取纵横小说网页内容
第一节课:
一:根据page页面解析出book_url
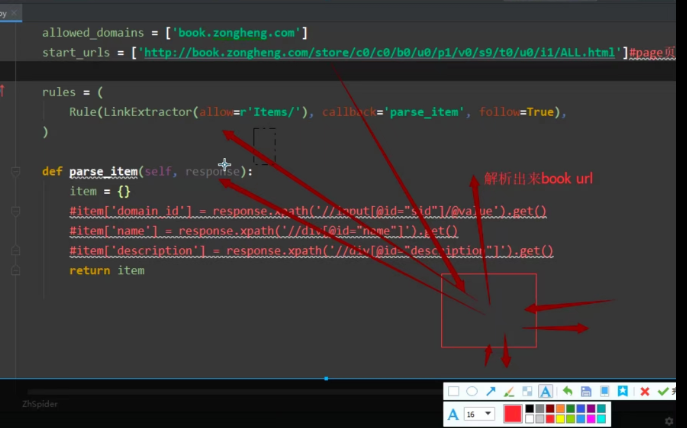
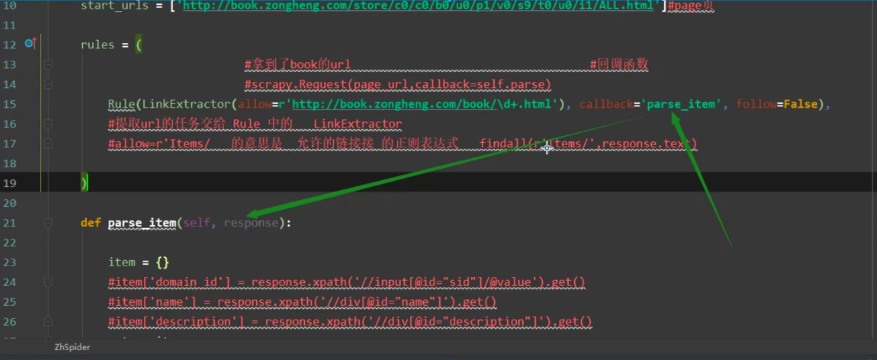
二: 解析来的response (book_url) 并不是交给parse_item方法,而是交给了上面的rules处理,然后通过LinkExtractor提取静态页面数据url,url形成一个新的请求交给引擎,引擎一顿操作给到callback=‘parse_item’回调函数
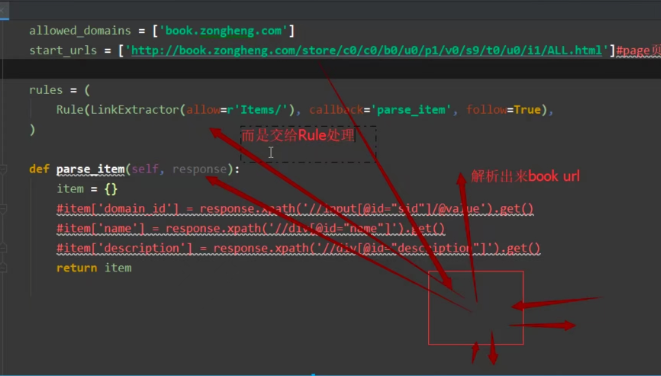
三:最后交给parse_item
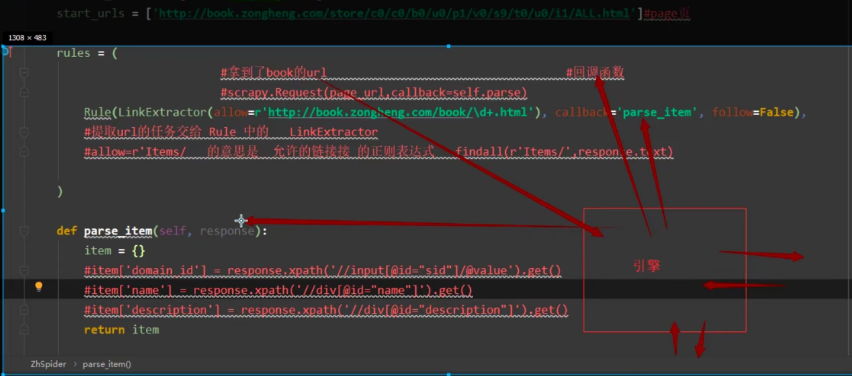
梳理整个流程:
1.根据page页面url得到的response处于无处安放状态
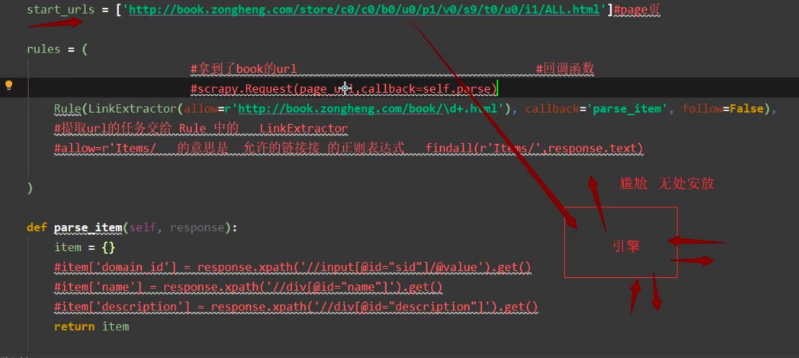
2.response交给Rule处理
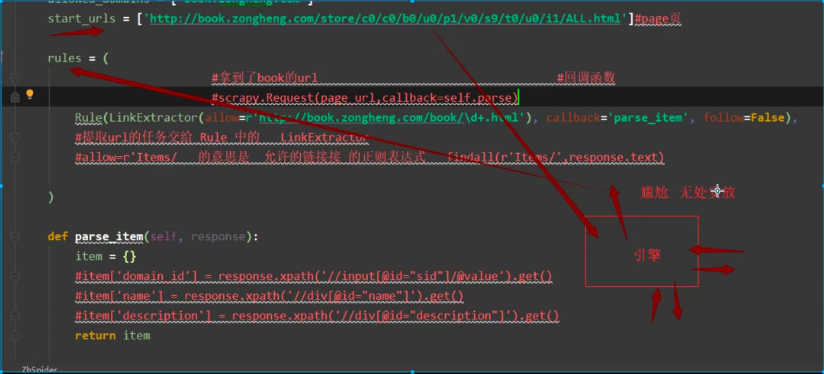
3.通过LinkExtractor提取静态页面数据url,url形成一个新的请求交给引擎
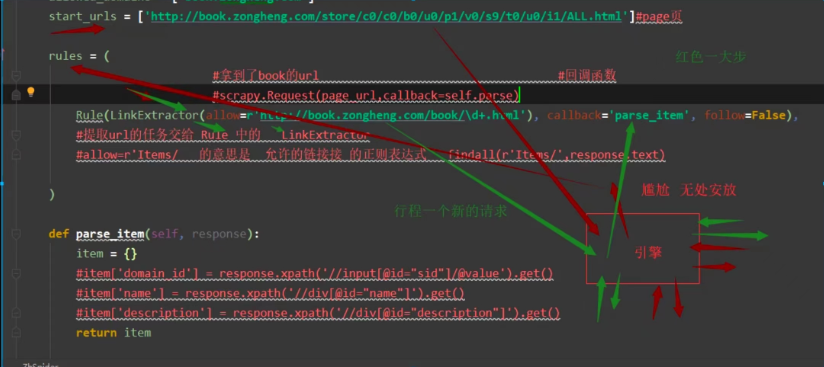
4.引擎一顿操作给到callback=‘parse_item’回调函数
5.可以启动程序测试一下
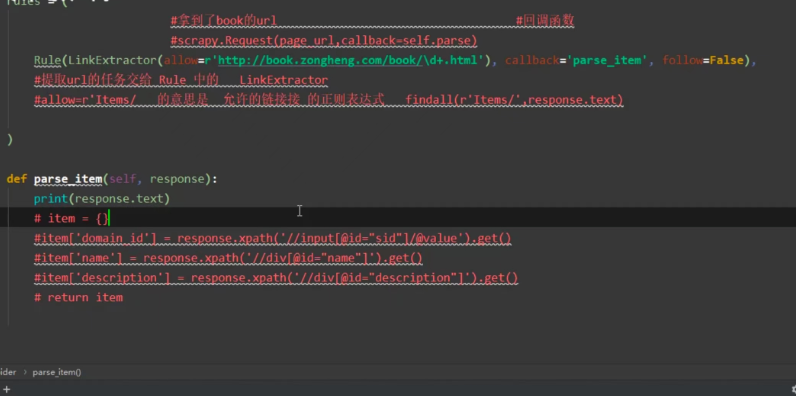
测试
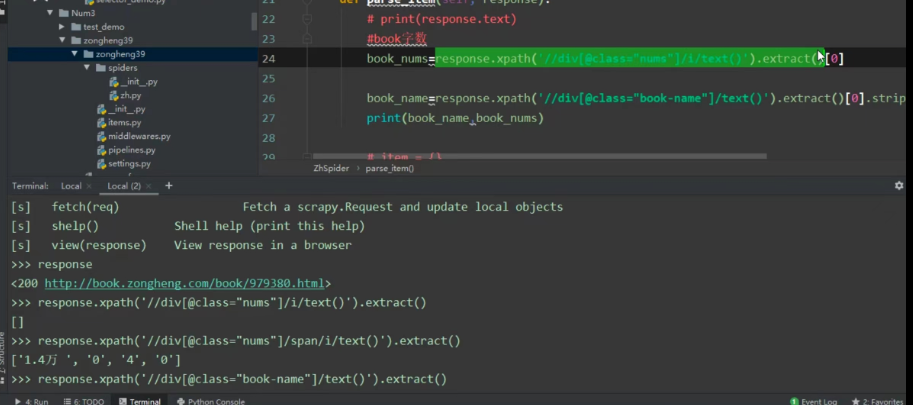
启动程序:scrapy crawl zh
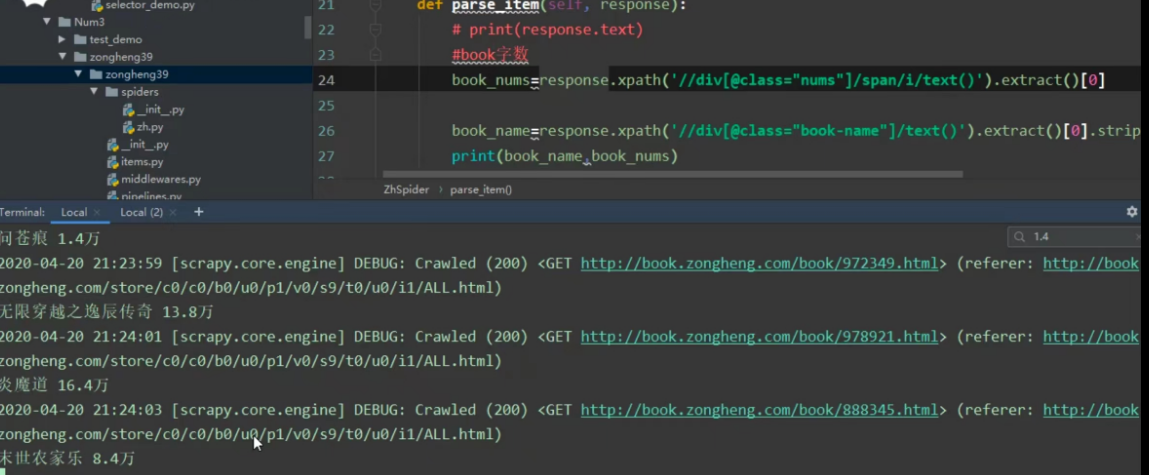
以下最新版:
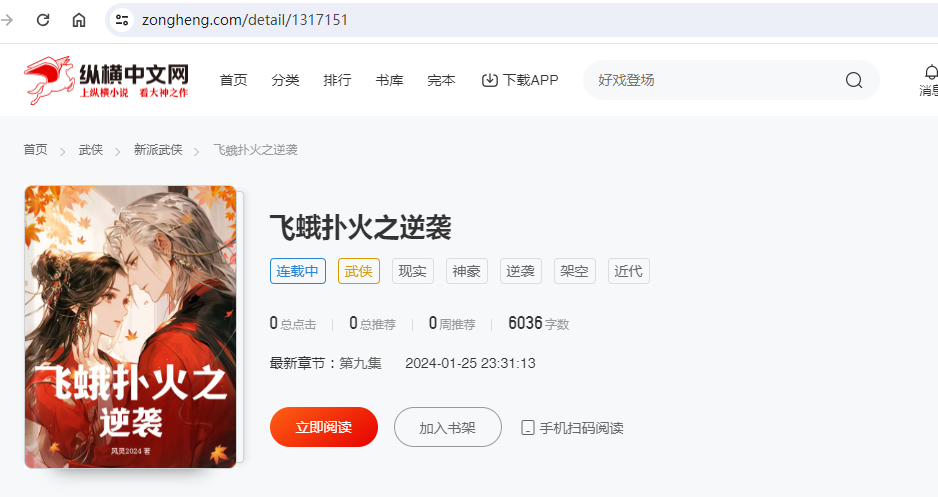
详情页url(次级页面):https://www.zongheng.com/detail/1317151
次级页面源码:
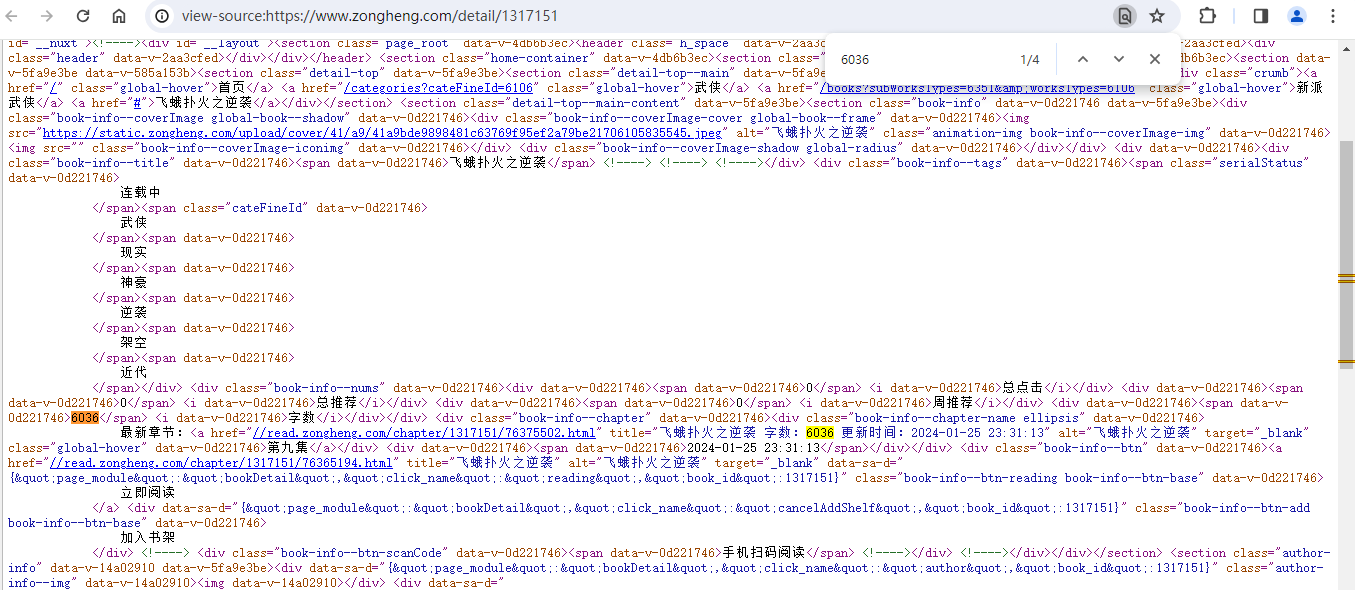
书名信息:
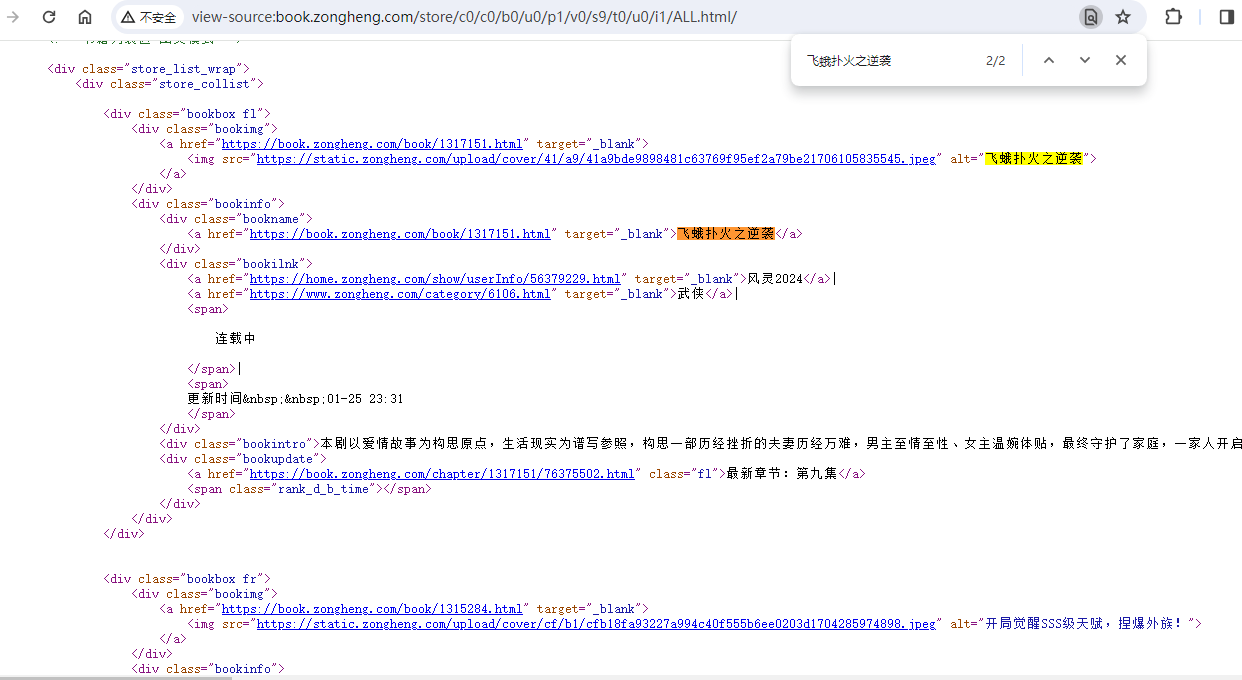

| <div class="bookinfo"> | |
| <div class="bookname"> | |
| <a href="https://book.zongheng.com/book/1317151.html" target="_blank">飞蛾扑火之逆袭</a> | |
| </div> |
D:\py学习01\python爬虫基础\scrapy框架\CrawlSpider爬取纵横小说\num3\zongheng233>scrapy shell https://www.zongheng.com/det
ail/1317151
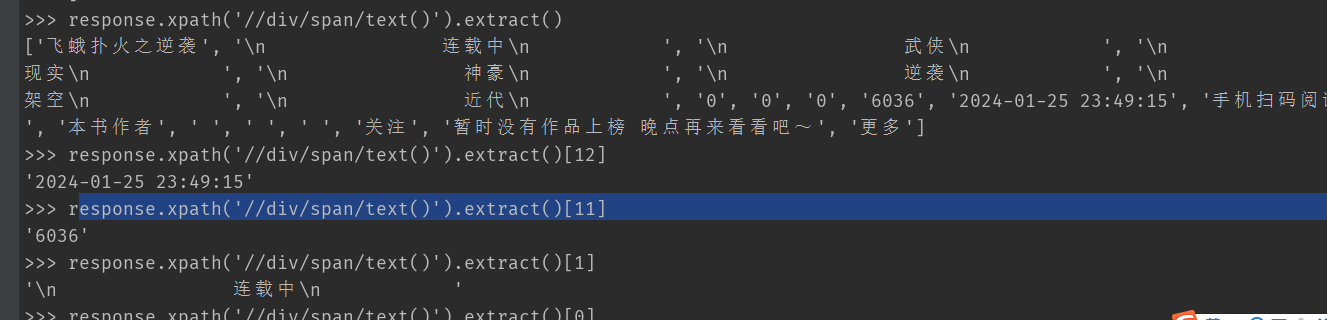
第二节课:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号