scrapy 框架的安装及流程-01
一、简介

scrapy的优势:
1、为了更利于我们将精力集中在请求与解析上
2、企业级的要求,效率高
二、模块安装
scrapy支持Python2.7和python3.4以上版本
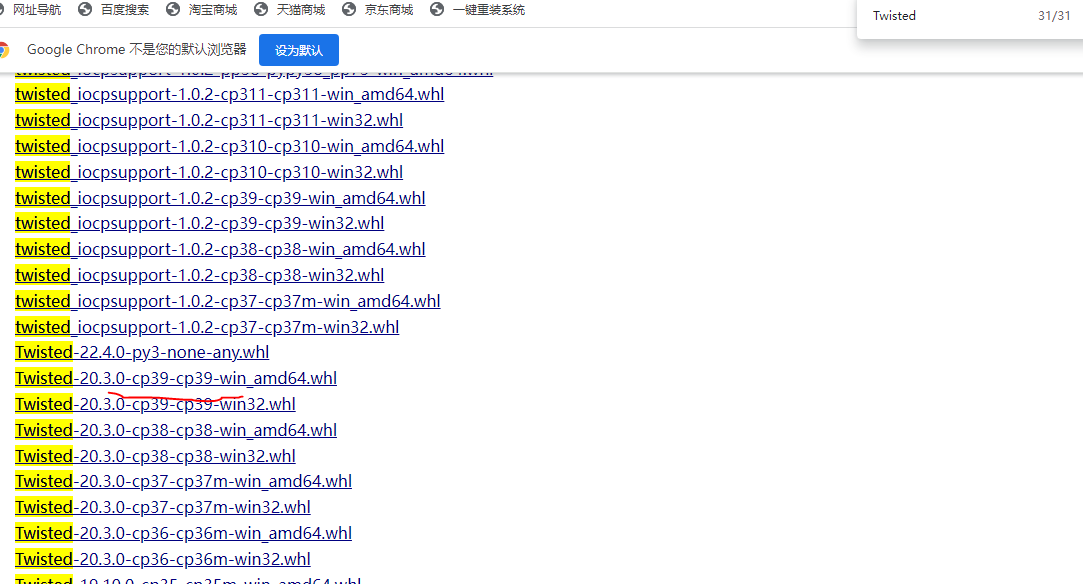
1.在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的Twisted的版本文件
注意:
cp为python 版本号,若版本不对应运行spiders 文件可能因为不兼容报错。这时需要卸载重新安装与python版本对应的Twisted

卸载:
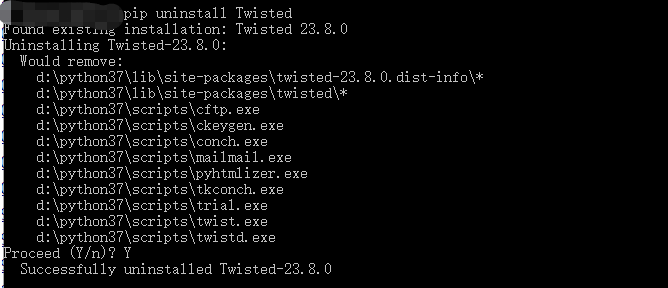
安装与pyhon37对应的Twisted: Twisted-20.3.0-cp37-cp37m-win_amd64.whl
pip install Twisted==20.3.0

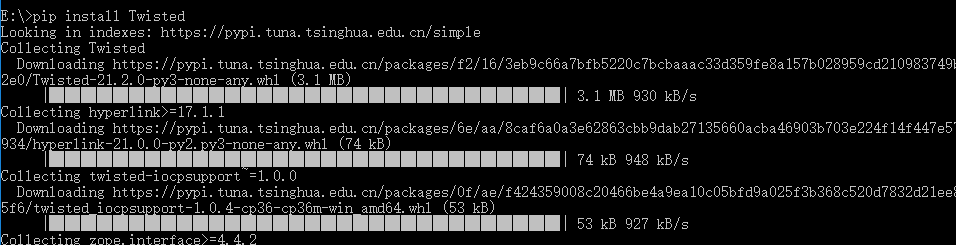
2. 在命令行进入到Twisted的目录 执行pip install 加Twisted文件名 pip install Twisted
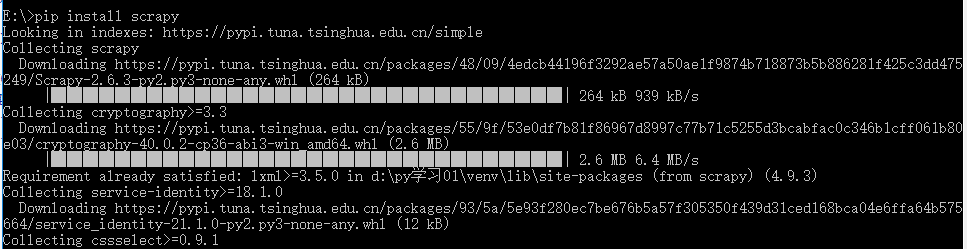
3.执行pip install scrapy
三、运行流程
只要是框架就要掌握其运行流程
1.找到目标数据==》2.分析请求流程==》3.构造http请求==》4.提取数据==》5.数据持久化
A:新生报到的例子

宿舍 床号 班级 卡号
移动办卡 床单
可能有新的需求会交给管理员,然后重新排队(如换床号,不住宿等),然后再到报到处报道拿资料,然后到新生等待处,当 需求满足0时退出
B:
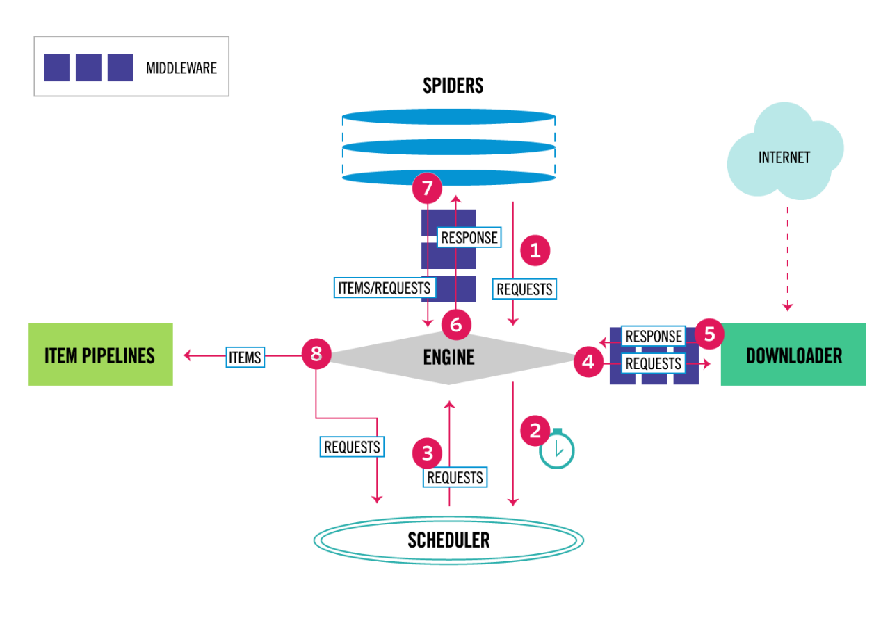
上图显示了Scrapy框架的体系结构及其组件,以及系统内部发生的数据流(由红色的箭头显示) Scrapy中的数据流由执行引擎控制,流程如下:
1.首先从爬虫获取初始的请求
2.将请求放入调度模块,然后获取下一个需要爬取的请求
3.调度模块返回下一个需要爬取的请求给引擎
4.引擎将请求发送给下载器,依次穿过所有的下载中间件
5.一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件。
6.引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件
7.爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎
8.引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求
9.该过程重复,直到调度程序不再有请求为止。

第四部分、简单的使用
创建爬虫文件bd步骤
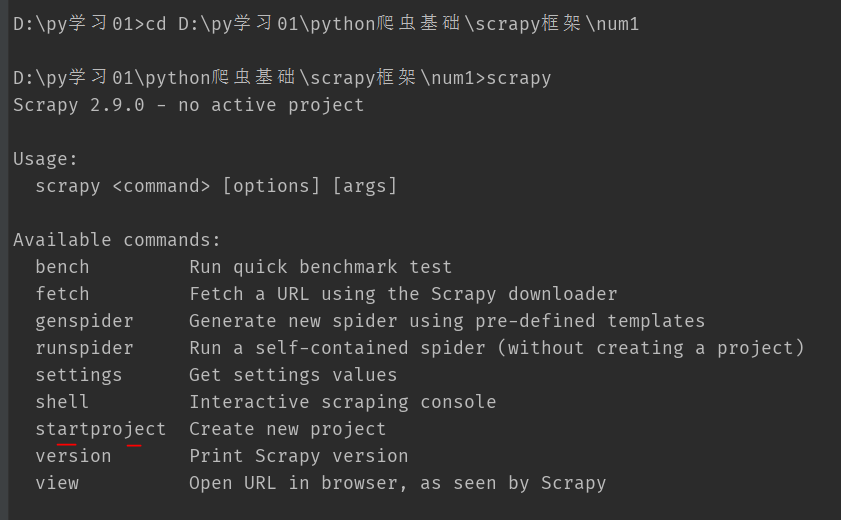
1.Terminal窗口输入:scrapy
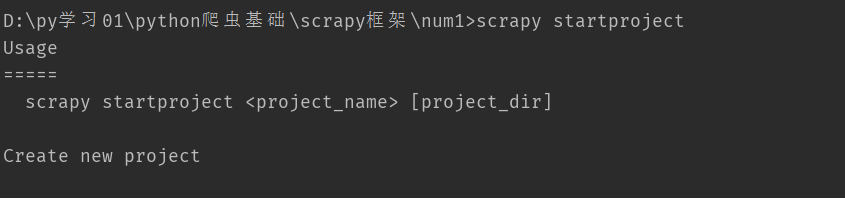
2.创建项目: scrapy startproject <project_name> [project_dir] ps: "<>"表示必填 ,"[]"表示可选
scrapy startproject baidu(项目名字baidu)
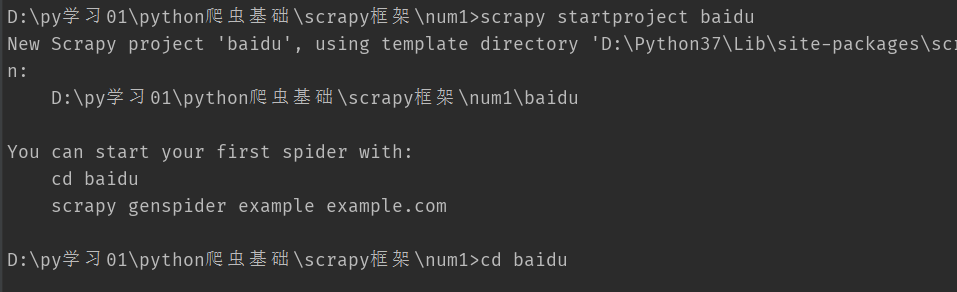
3.cd 到项目下 scrapy genspider [options] <name> <domain> scrapy genspider example example.com 会创建在项目/spider下 ;
其中example 是爬虫文件名, example.com 是 url
如下:scrapy genspider bd www.baidu.com
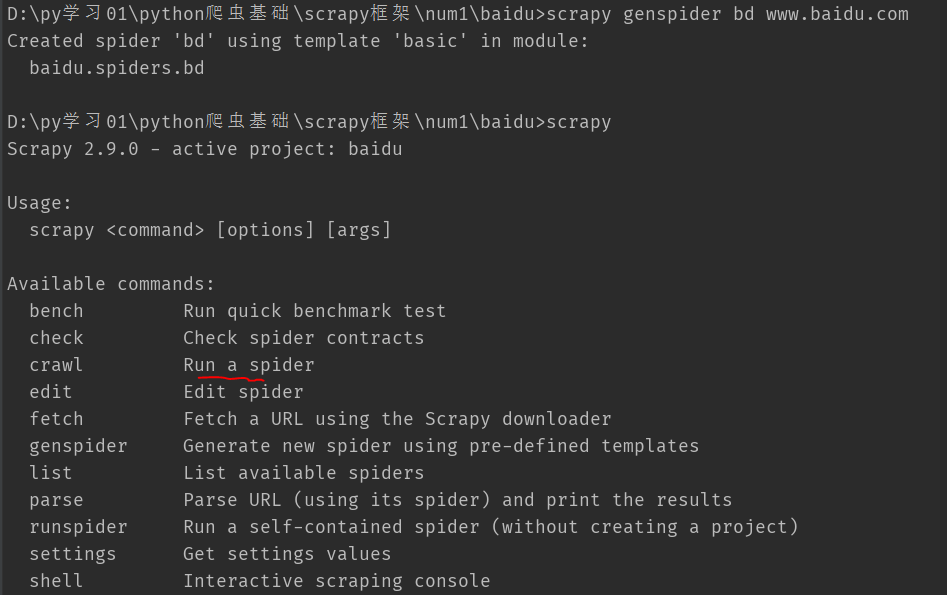
4.运行项目 scrapy crawl 爬虫文件名(bd),运行bd.py文件

5.setting 里配置 更改

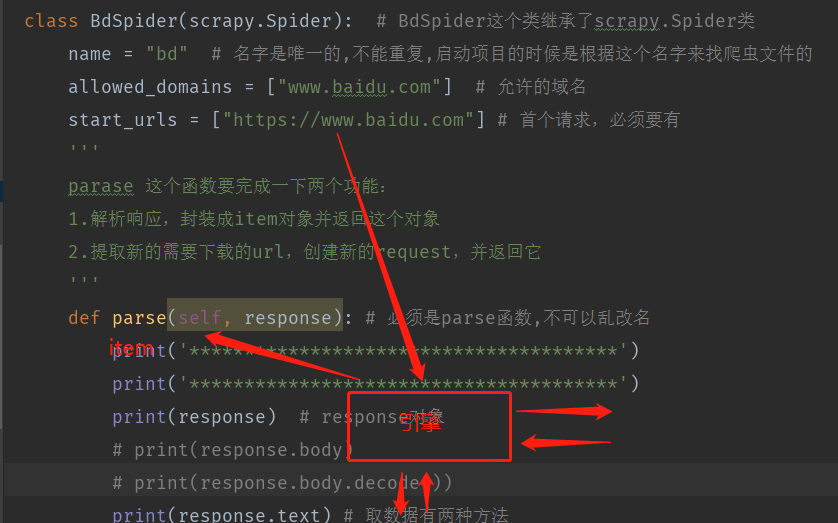
6.bd.py文件代码
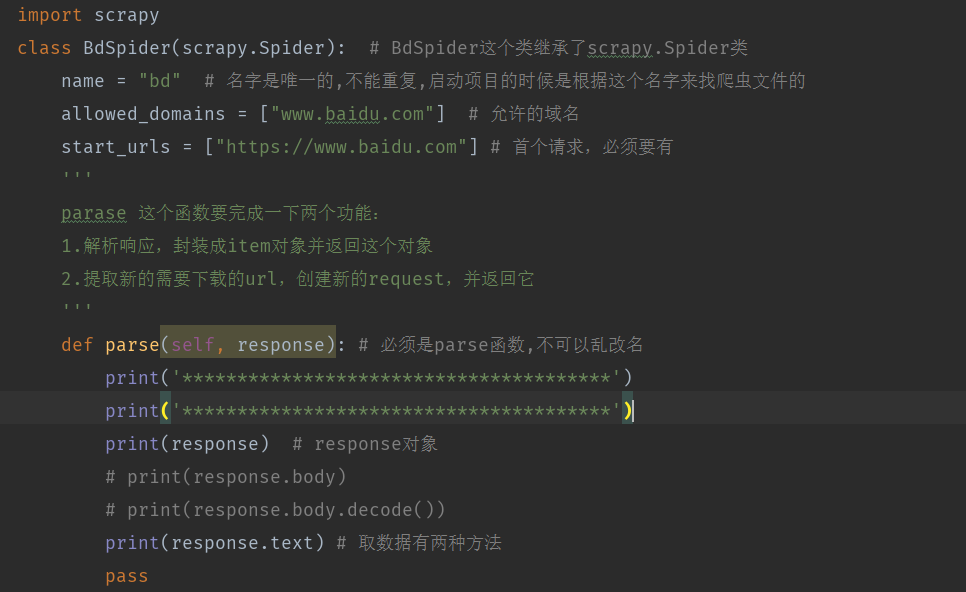
import scrapy
class BdSpider(scrapy.Spider): # BdSpider这个类继承了scrapy.Spider类
name = "bd" # 名字是唯一的,不能重复,启动项目的时候是根据这个名字来找爬虫文件的
allowed_domains = ["www.baidu.com"] # 允许的域名
start_urls = ["https://www.baidu.com"] # 首个请求,必须要有
'''
parase 这个函数要完成一下两个功能:
1.解析响应,封装成item对象并返回这个对象
2.提取新的需要下载的url,创建新的request,并返回它
'''
def parse(self, response): # 必须是parse函数,不可以乱改名
print('***************************************')
print('***************************************')
print(response) # response对象
# print(response.body)
# print(response.body.decode())
print(response.text) # 取数据有两种方法
pass
7.运行截图
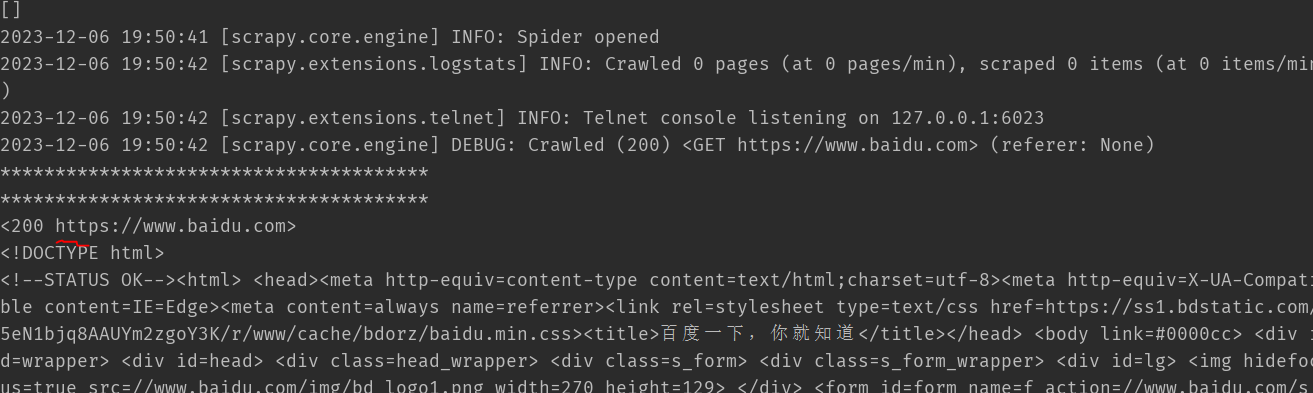
总结:
请求给到引擎,然后引擎先给给到调度器,再到中间件,最后到管道。即请求由引擎一顿操作完成解析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号