豆瓣电影top250爬取
第一部分:实现方法
通过requests+xpath实现豆瓣电影top250一些信息的爬取
第二部分:思路、分析过程
1.浏览器输入豆瓣电影top250
2.打开主页面,显示有20条电影信息数据
page_url=https://m.baidu.com/sf?pd=topone_multi&top=%7B%22sfhs%22%3A1%7D&atn=index&word=%E8%B1%86%E7%93%A3%E7%94%B5%E5%BD%B1top250&lid=
16638235655785603014&key=bd%2FbPtJ7umUkuPF3fz0H4wbbfR%2FIB8veb6rRjTDeeqEVS%2F1TIXYtLVMW25bRVfFa%2BdvPb0y98zHLTQOcnk8wmJEQqtz76fON2BcDkEuHIdg%
3D&type=bpage

...........................................................................................................................................................................................................

如果page_url主页信息无法获取可以增加headers,按F12或者检查进入(进之前用F5刷新一下)
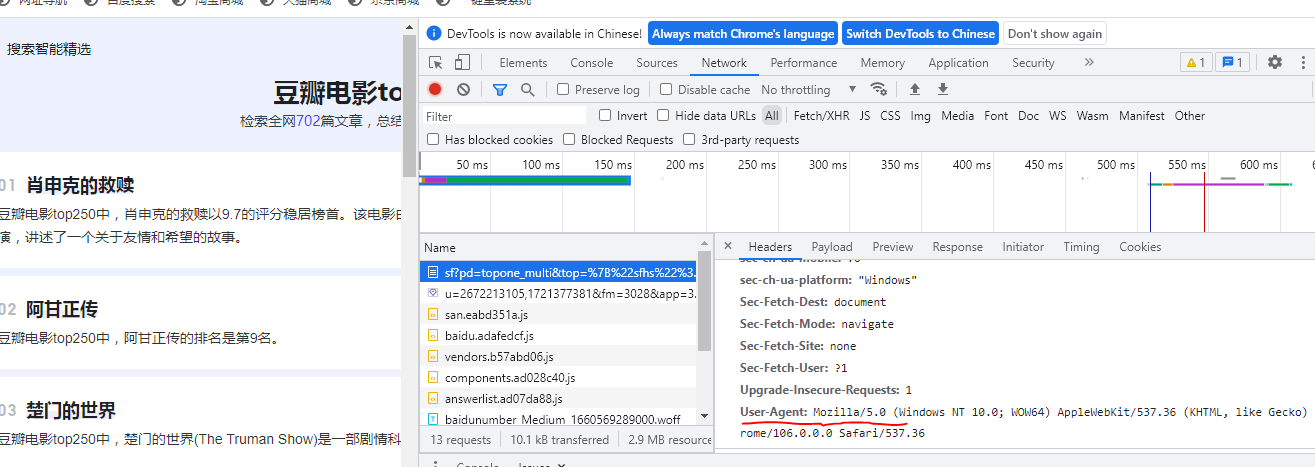
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
3.进入page页面,通过Ctrl+F搜索电影名字,如肖申克的救赎,找到电影信息的共同规律
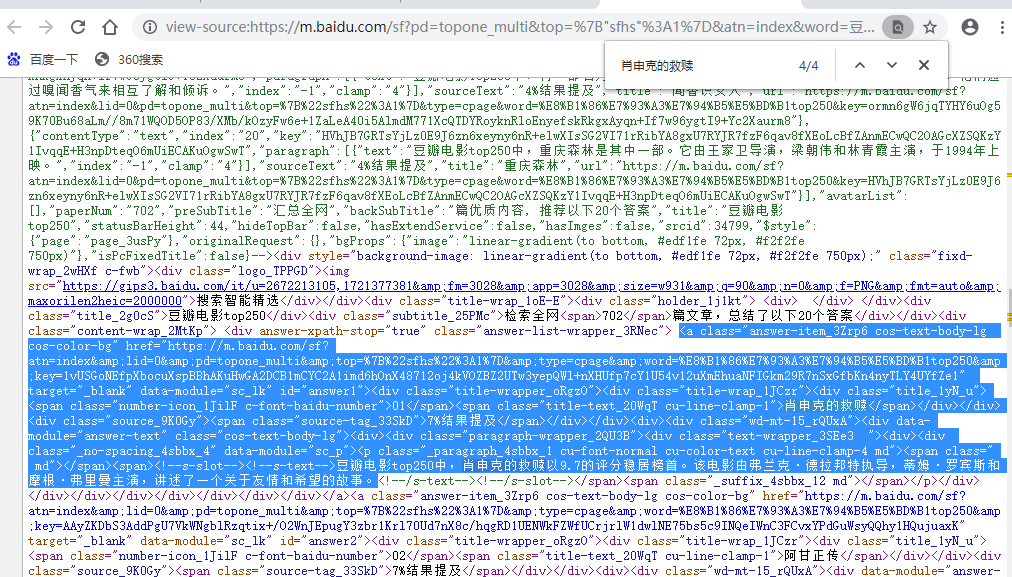
分析如下关键源码找到需要的数据信息代码:
<div class="content-wrap_2MtKp"> <div answer-xpath-stop="true" class="answer-list-wrapper_3RNec">
<a class="answer-item_3Zrp6 cos-text-body-lg cos-color-bg" href="https://m.baidu.com/sf?atn=index&lid=0&pd=topone_multi&top=%7B%22sfhs%22%3A1%7D&type=cpage&word=%E8%B1%86%E7%93%A3%E7%94%B5%E5%BD%B1top250&key=1vUSGoNEfpXbocuXspBBhAKuHwGA2DCB1mCYC2A1imd6hOnX48712oj4kVOZBZ2UTw3yepQWl+nXHUfp7cY1U54v12uXmEhuaNFIGkm29R7nSxGfbKn4nyTLY4UYfZe1" target="_blank" data-module="sc_lk" id="answer1"><div class="title-wrapper_oRgzO"><div class="title-wrap_1JCzr"><div class="title_1yN_u"><span class="number-icon_1JilF c-font-baidu-number">01</span><span class="title-text_20WqT cu-line-clamp-1">肖申克的救赎</span></div></div><div class="source_9K0Gy"><span class="source-tag_33SkD">7%结果提及</span></div></div><div><div class="wd-mt-15_rQUxA"><div data-module="answer-text" class="cos-text-body-lg"><div><div class="paragraph-wrapper_2QU3B"><div class="text-wrapper_3SEe3 "><div><div class="_no-spacing_4sbbx_4" data-module="sc_p"><p class="_paragraph_4sbbx_1 cu-font-normal cu-color-text cu-line-clamp-4 md"><span class=" md"></span><span><!--s-slot--><!--s-text-->豆瓣电影top250中,肖申克的救赎以9.7的评分稳居榜首。该电影由弗兰克·德拉邦特执导,蒂姆·罗宾斯和摩根·弗里曼主演,讲述了一个关于友情和希望的故事。
a.获取电影的链接信息
Xpath如何爬取a标签中的href*(相对应的网址)?
直接把你的text()改成@href就可以了,这个就能直接拿到链接,不用再加text()了
links=html.xpath('//div[@class="content-wrap_2MtKp"]/div/a/@href')
b.获取电影名字信息
第一种方法:
film_name=html.xpath('//div[@class ="title_1yN_u"]/span[2]/text()') # text() 获取值
第二种方法:
film_name1=html.xpath('//div[@class="content-wrap_2MtKp"]/div/a/div/div/div[@class="title_1yN_u"]/span[2]/text()')
c.提示信息获取
tips=html.xpath('//div[@class ="source_9K0Gy"]/span/text()')
d.电影介绍信息获取
introduces=html.xpath('//div[@class="_no-spacing_4sbbx_4"]/p/span[2]/text()')
第三部分:完整代码
# scrapy之前知识复习
'''
1.爬虫概念 HTTP协议 会话技术
2.socket urllib urllib3 requests
3.数据提取方法 bs4 xpath Re
4.fidder 抓包工具 selenium
5.访问网页、下载图片、抓取手机app视频 12306图片验证登录
'''
# 通过requests+xpath实现豆瓣电影top250一些信息的爬取
import requests
from lxml import etree
page_url='https://m.baidu.com/sf?pd=topone_multi&top=%7B%22sfhs%22%3A1%7D&atn=index&word=%E8%B1%86%E7%93%A3%E7%94%B5%E5%BD%B1top250&lid=10088551000581072176&key=bd%2FbPtJ7umUkuPF3fz0H4wbbfR%2FIB8veb6rRjTDeeqEVS%2F1TIXYtLVMW25bRVfFa%2BdvPb0y98zHLTQOcnk8wmJEQqtz76fON2BcDkEuHIdg%3D&type=bpage'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
res=requests.get(page_url,headers=headers)
# print(res.text) # 如果打印不出来加个headers
html=etree.HTML(res.text) # 把整个网页变成html标签
# 1.链接信息
# Xpath如何爬取a标签中的href*(相对应的网址)?
# 你直接把你的text()改成@href就可以了,这个就能直接拿到链接,不用再加text()了
links=html.xpath('//div[@class="content-wrap_2MtKp"]/div/a/@href')
# links=html.xpath('//div[@class="content-wrap_2MtKp"]/div/a/@href')[0]
print(len(links)) # 20个电影信息
print(links)
# tags=html.xpath('//div[@class ="title_1yN_u"]/span[2]') # 主页面共20条数据
# div[@class ="title_1yN_u"]/span[2]/text() 这个只能获取电影名字 信息不全需要换个div
# 2.获取电影名字
film_name=html.xpath('//div[@class ="title_1yN_u"]/span[2]/text()') # text() 获取值
film_name1=html.xpath('//div[@class="content-wrap_2MtKp"]/div/a/div/div/div[@class="title_1yN_u"]/span[2]/text()')
print(film_name1)
# 3.提示信息获取
tips=html.xpath('//div[@class ="source_9K0Gy"]/span/text()')
print(tips)
# print('ok') # 测试用的
# 4.电影介绍
introduces=html.xpath('//div[@class="_no-spacing_4sbbx_4"]/p/span[2]/text()')
print(introduces)
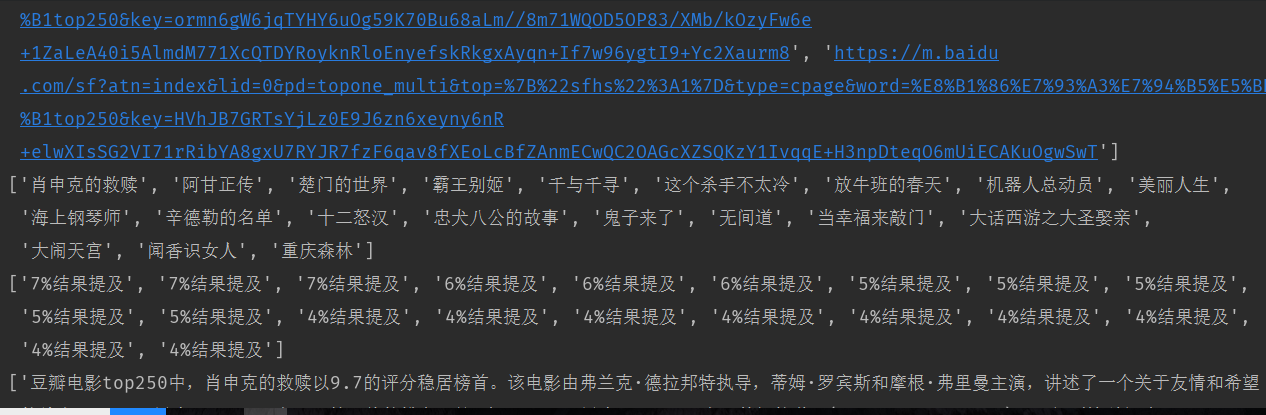
运行截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号